-
-
Top 3 Suggestions by Rally open to voting
-
Homescreen without chat
-
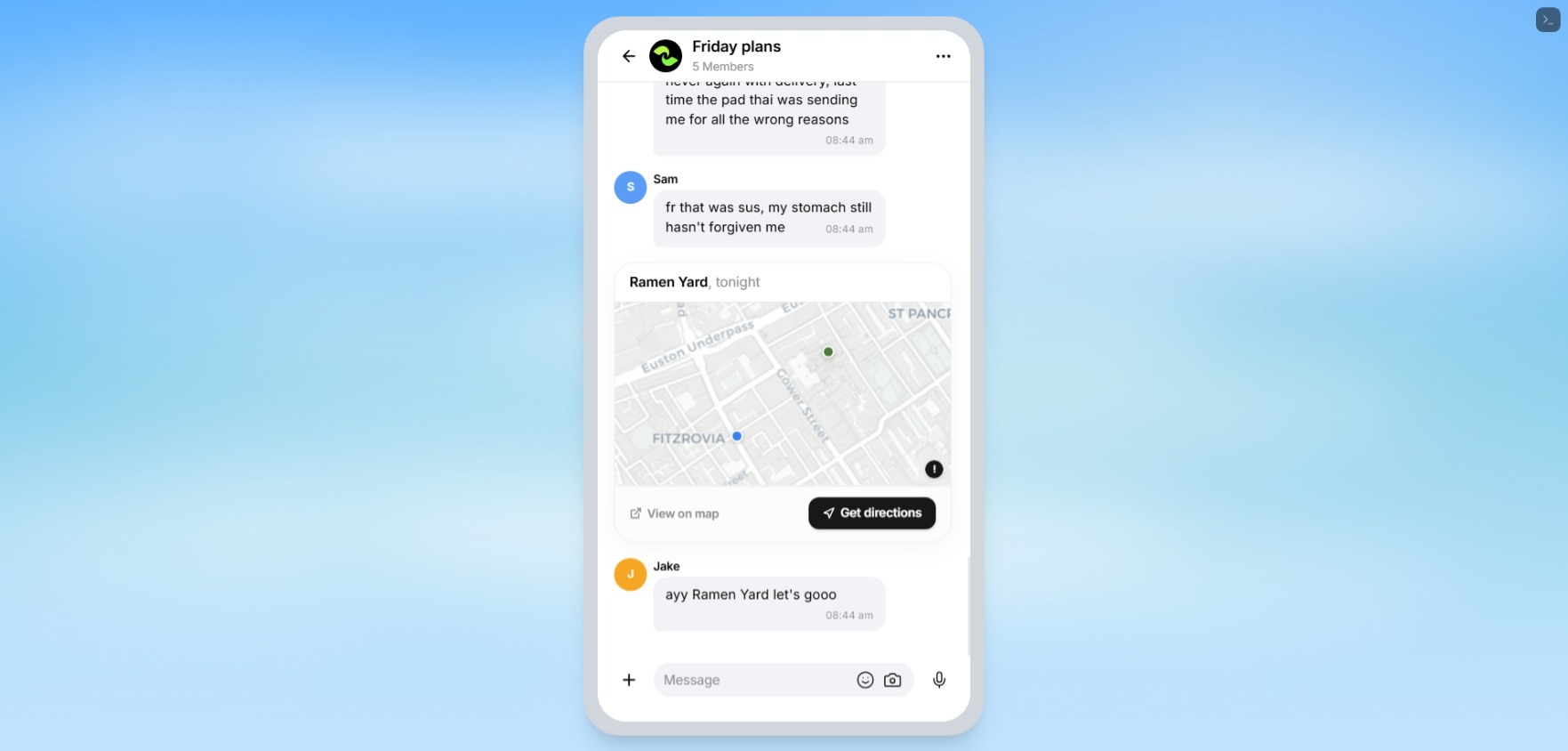
Inbuit location map to the restaurant
Inspiration
Every group chat has the same failure mode: 40 messages, six suggestions, three hidden constraints, and still no decision.
I built Rally because group coordination is not really a search problem. It is a social decision problem. One person wants cheap food. Someone else is vegetarian. Someone wants somewhere close. Another person keeps suggesting ramen. The quiet person says “I am fine with anything,” but what they actually mean is “please do not pick somewhere expensive, far away, or impossible for my diet.”
Most apps solve this with polls, forms, or a chatbot. That creates more work for the group. Rally starts from the chat that already happened.
For the Build with Zymix track, I wanted to build something that feels native to a Gen Z social app: instant, low-friction, social, and useful inside the conversation. Rally turns social intent into action.
What it does
Rally is a one-tap coordination helper for group chat.
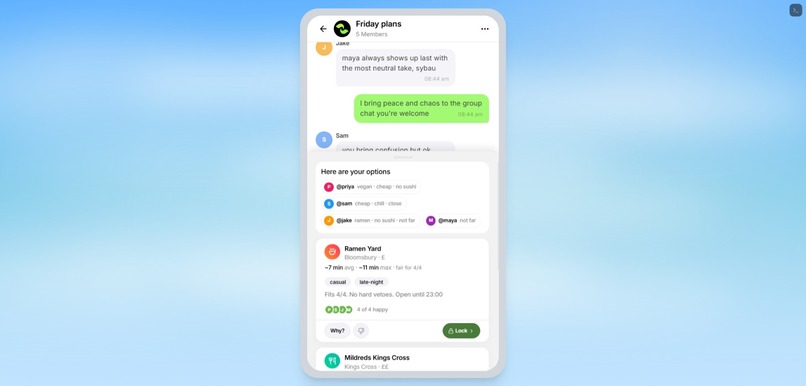
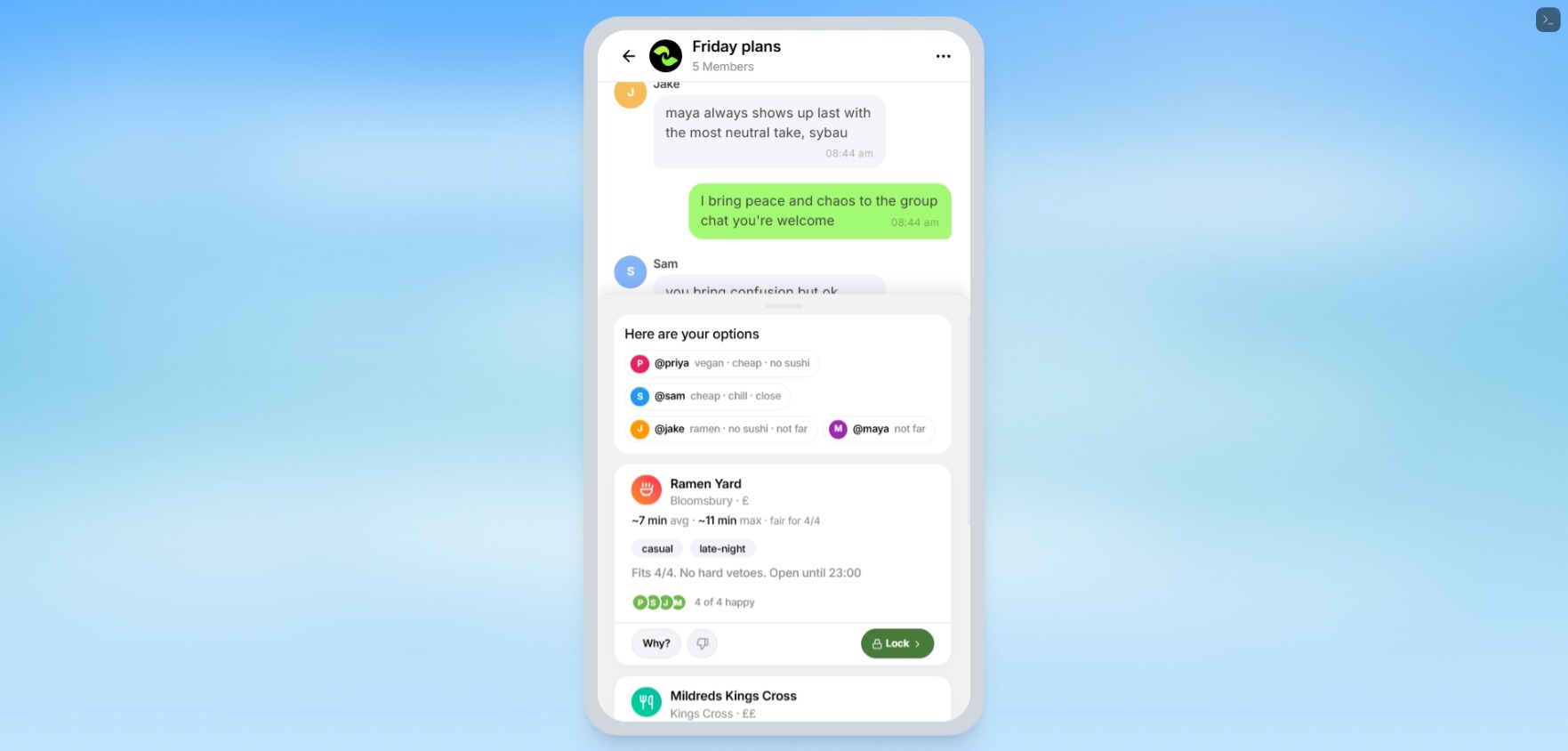
When a group is stuck deciding where to eat or what to do, Rally detects coordination friction and surfaces a subtle “Decide for us” button. When tapped, it reads the recent chat, extracts each person’s constraints, retrieves grounded venue options, scores them fairly, and returns three option cards.
Each option card shows:
- the venue or plan
- budget, diet, vibe, and travel fit
- who it works for
- who might object
- a fairness score
- a “Why this?” explanation
- a “Why not?” comparison against losing options
- anonymous soft veto
- one-tap lock
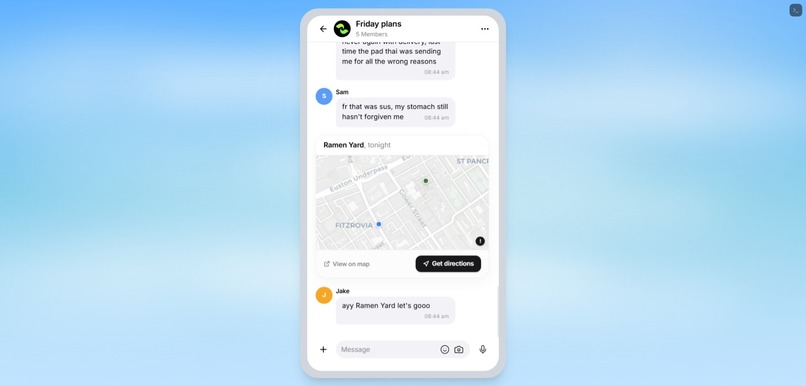
- directions through Google Maps or Apple Maps
The important part is that Rally does not just pick the most mentioned place. It turns messy chat into a structured group decision.
A typical flow looks like this:
- The group chat gets stuck.
- Rally detects planning friction.
- Someone taps “Decide for us.”
- Rally extracts constraints such as vegan, under £15, not sushi, close to UCL, and chill vibe.
- Rally retrieves grounded venues from a local database.
- Rally filters out hard constraint failures.
- Rally scores remaining options using a fairness-aware consensus algorithm.
- The group gets three clear plans.
- Anyone can soft-veto.
- The group locks the plan and gets directions.
How I built it
I built Rally as a full-stack AI coordination engine, not as a prompt wrapper.
Frontend
The frontend is a React and TypeScript app designed to feel like a Zymix-native mini-app. The core UI is a chat screen, a “Decide for us” pill, a bottom-sheet recommendation flow, fairness bars, option cards, soft veto, plan lock, a live QR room, and a proof panel for the AI pipeline.
The UX goal was brutal simplicity:
- no onboarding
- no forms
- no manual preference survey
- no long chatbot interaction
- no full-screen planner
- no unnecessary map engine
The product has to feel like one tap from chaos to action.
Backend
The backend is a Rust Axum server with SQLite as the core data layer. I chose Rust because the product needs low latency, strong type safety, and a credible systems story. The backend ingests group chat messages, extracts structured preferences, retrieves candidate venues, scores them, and broadcasts events to connected clients through WebSockets.
The backend is intentionally single-process and single-binary. I avoided microservices because this is a hackathon product where reliability matters more than infrastructure theatre.
AI and NLP pipeline
Rally uses a three-tier preference extraction pipeline.
Tier 1: deterministic scanner
A Rust scanner catches explicit signals in under 5ms:
- “vegan” becomes a hard dietary constraint
- “under 15” becomes a budget cap
- “not sushi” becomes a cuisine veto
- “nearby” becomes a travel constraint
- “quiet” becomes a vibe tag
Tier 2: embedding similarity
For less obvious signals, Rally uses lightweight semantic matching. This helps map phrases like “lowkey,” “somewhere calm,” or “cheap and cheerful” into structured vibe or budget signals.
Tier 3: Z.ai GLM
Z.ai GLM is used only when language is genuinely ambiguous. It extracts structured preference deltas from messy chat, such as:
- “I am basically skint until payday” to budget constraint
- “I guess I am easy” to low-confidence neutrality
- “not too far, please” to travel-radius preference
- “anything but sushi again” to soft veto
The model does not pick venues. The model does not write final explanations. The model does not invent places. It only helps convert human conversation into structured decision state.
Retrieval and grounding
The venue recommendations are grounded in a local SQLite database. Rally uses hybrid retrieval over venue names, cuisine tags, diet tags, areas, vibe tags, and embeddings.
The retrieval design uses:
- SQLite FTS5 for lexical and metadata matching
- vector similarity for semantic vibe matching
- Reciprocal Rank Fusion to combine lexical and semantic results
- hard filters for budget, diet, opening hours, and feasibility
- a memory-vector fallback on Windows when sqlite-vec is unavailable
This means the demo stays reliable. If a vector extension fails, Rally still runs. If the network fails, Rally still runs. If the AI provider is unavailable, the deterministic and demo-safe paths still work.
Fairness and scoring
Rally uses a fairness-aware consensus engine inspired by group recommender systems, computational social choice, Average Without Misery, Nash Social Welfare, and fair division literature.
The scoring pipeline has three stages.
Stage 1: hard constraint filter
A venue cannot win if it violates a hard constraint. For example, a venue without vegetarian options cannot be recommended if a participant requires vegetarian food. A venue over someone’s hard budget cap is removed before scoring.
Stage 2: per-person utility
For each surviving venue, Rally computes a utility score for each participant across:
- cuisine match
- budget fit
- distance and travel fit
- vibe alignment
- dietary safety
- soft vetoes
- confidence in extracted preferences
Stage 3: group consensus
Rally combines individual utilities with:
final_score = 0.6 * WAWM + 0.4 * Nash - soft_veto_penalty
WAWM stands for Weighted Average Without Misery. It rewards plans that work for the group while avoiding options that make someone clearly unhappy.
The Nash term penalizes skewed outcomes. A venue that is amazing for three people but bad for one person should not automatically beat a venue that is good for everyone.
This is the core difference between Rally and a poll. A poll counts votes. Rally reasons about constraints, fairness, and social tradeoffs.
Live and proof modes
I also built extra demo modes to prove the system is real.
Curated replay mode
A reliable mode for judging. It replays a realistic Zymix-style chat and runs the decision pipeline.
Live QR room
A judge can scan a QR code, enter a username, and join a live room. Messages persist through Supabase Realtime, and Rally can run the same decision pipeline on live chat messages.
AI persona proof mode
GLM can generate live group-chat messages from fixed persona specs. Rally then detects disagreement naturally from those AI-generated messages. The “Decide for us” button appears only when the normal detector crosses its threshold. It is not forced by the simulation.
This proves the three parts of the pipeline:
- AI-generated chat appears live.
- The detector sees genuine coordination friction.
- The normal Rally decision pipeline returns grounded, scored options.
Challenges I ran into
The hardest challenge was making the system impressive without making it fake.
A basic version would have sent the whole chat to an LLM and asked it to choose a restaurant. That would be easy to build, but it would fail in three ways:
- It could hallucinate venues.
- It could overfit to whoever typed last.
- It could not explain the decision with auditable math.
I avoided that by separating the system into strict responsibilities:
- GLM extracts preferences.
- SQLite grounds venue retrieval.
- Rust computes the final ranking.
- Templates generate explanations from scoring data.
- Maps handle navigation only after the plan is locked.
Another challenge was fairness. A simple average is not enough because group decisions are not solo recommendations. If one person is vegan, the group cannot average that constraint away. If one person is quiet, the system should not treat them as irrelevant. Rally uses hard filters, participation caps, recency-based weighting, WAWM, and Nash-style penalties to avoid the loudest-speaker problem.
I also hit local engineering issues. SQLite vector extensions can fail on Windows with vec0 module errors, so I added a memory-vector fallback that keeps semantic retrieval working without blocking the demo.
Accomplishments that I am proud of
I am proud that Rally is not just a good idea. It is a real working system with a serious architecture.
The strongest parts are:
- A Rust backend with Axum, SQLite, WebSockets, and deterministic scoring
- A three-tier NLP pipeline that avoids unnecessary LLM calls
- Z.ai GLM used where AI is actually essential
- Grounded venue retrieval so the model cannot invent places
- A fairness algorithm based on WAWM and Nash-style scoring
- Anonymous soft veto and live reranking
- “Why this?” and “Why not?” explanations generated from structured scoring data
- Travel fairness and directions handoff
- Live QR room for real participant input
- AI persona proof mode to demonstrate natural disagreement detection
- Demo-safe fallback paths that preserve the core product flow
The part I am most proud of is the fairness explanation. Rally does not just say what won. It shows why one plan won, why another lost, and which constraints mattered.
What I learned
I learned that the real product problem is not recommendation. It is trust.
People do not just need a place to go. They need to believe the decision did not ignore them. A coordination helper has to be socially aware, not just smart.
I also learned that the right AI architecture is usually smaller than people expect. The LLM should not own the whole product. In Rally, the AI handles ambiguity, while deterministic systems handle retrieval, scoring, constraints, explanations, and state transitions.
The biggest technical lesson was that hackathon reliability is part of product quality. A flashy live dependency is less valuable than a fast, grounded system with clear fallbacks.
Research and algorithms I consulted
Rally was influenced by several research areas and algorithmic ideas:
- group recommender systems
- Average Without Misery
- Least Misery
- Borda-style social choice
- Nash Social Welfare
- computational social choice
- multi-attribute utility theory
- fair division
- fairness in recommender systems
- Reciprocal Rank Fusion
- hybrid lexical and vector retrieval
- structured output extraction from LLMs
- speaker-aware dialogue state tracking
- multi-agent conversation simulation
The final system is a practical synthesis of these ideas. It does not try to prove perfect fairness. It makes fairness visible, auditable, and useful inside a fast consumer UX.
What is next for Rally
Rally can become a real Zymix-native mini-app.
The next steps are:
- connect to official Zymix group chat APIs if available
- write locked plans back into Zymix group chats
- expand from food into events, study sessions, nightlife, meetups, and campus plans
- add privacy-safe standing preferences controlled by each user
- add live venue refresh through official Places APIs
- sync plans with calendar and reminders
- improve long-term fairness so the same person is not always compromising
- expose an admin-free live group flow for real Zymix communities
Long term, Rally can become the missing decision layer inside social apps: the step between “we should do something” and actually doing it.
Built With
- apple-maps-links
- axum
- css
- google-maps-links
- html
- javascript
- memory-vector-retrieval
- qr-code-live-room
- react
- render
- rest-api
- rust
- sqlite
- sqlite-fts5
- supabase-realtime
- tokio
- typescript
- vercel
- vite
- websockets
- z.ai-glm

Log in or sign up for Devpost to join the conversation.