-
-
Landing Page
-
Login Page
-
Course Page
-
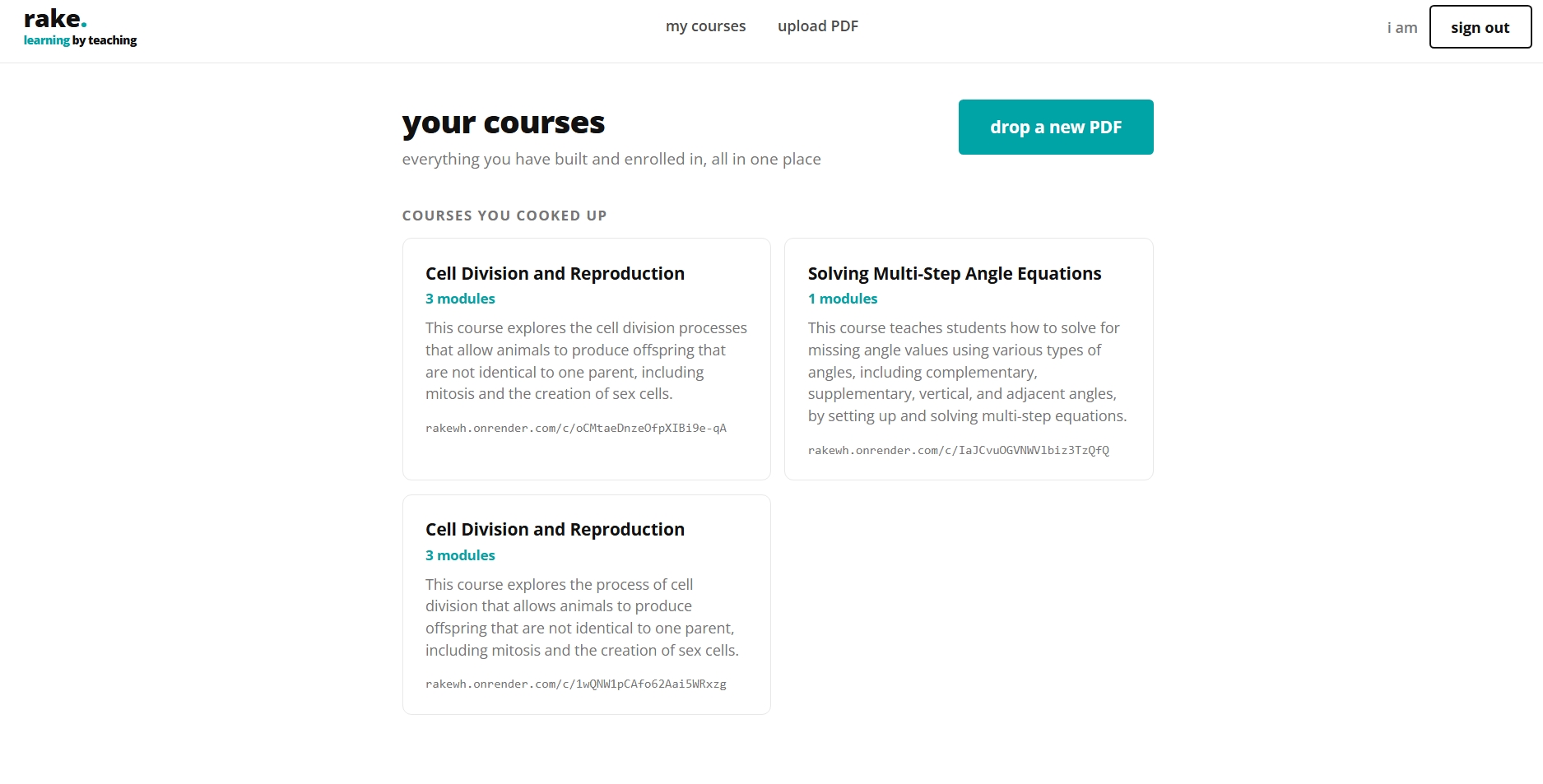
Dashboard Page
-
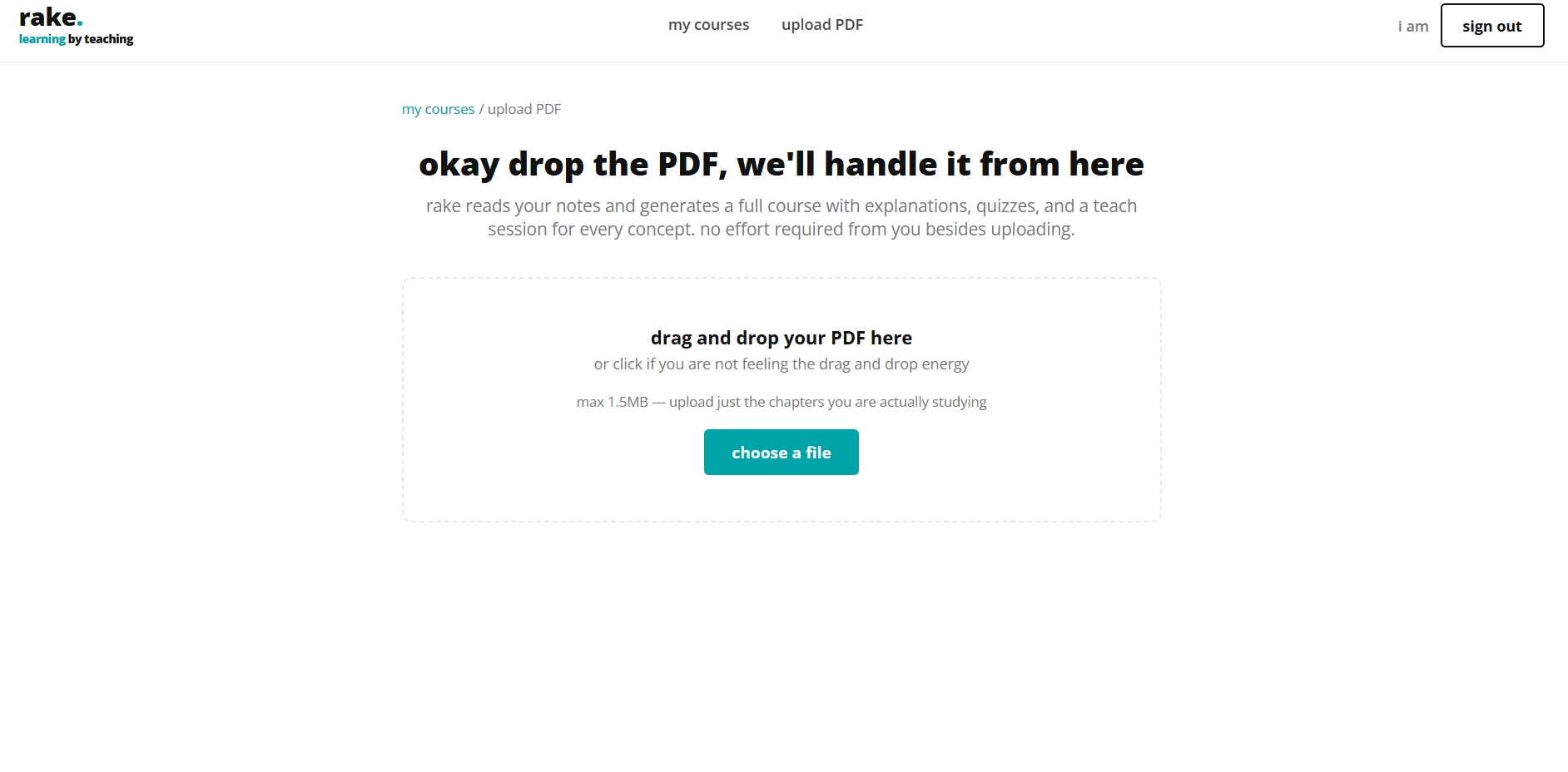
PDF Upload Page
Judges or anyone planning to use the demo, the password to access the site is "alwa9sturnwestatthecrossro4ds."
Inspiration
As a high school student, I've tried so many ways to learn stuff.
I was tired of memorizing things, forgetting them after the unit exam, and then spending sleepless nights cramming for finals. I wondered what I could do. It then hit me that I didn't know what I didn't know, but a way to combat that was to teach the topic to someone else myself. If I missed something, they could ask questions.
That's why I decided to make this project about helping students learn by having them teach, so they don't have to master it fully themselves. Because as they teach, they'll learn.
What it does
Rake is an AI and ML-powered platform that allows students to learn through reading, quizzes, and teaching a chatbot that knows nothing.
By using Llama 3.3 70B, which is an LLM, and an XGBoost model, it's able to help students make use of the new resources available to them today. The XGBoost model is trained on factors that reflect the user's understanding of the concept in real time to improve accuracy.
Since Rake is very straightforward to use, it allows almost anyone to use it. If a student is likely to forget a concept, the XGBoost can predict it 80% of the time and bring up a question from that concept to help the student recall it.
What issue am I solving?
The issue I'm solving is one faced by almost all students worldwide: learning with depth. At first, students may put offside learning with depth, but soon that can be reflected in their grades. If people learn in depth, they'll be able to recall that concept at any point in time.
How does my project address it?
Rake can help students learn in depth without spending too much time by providing a platform for students to explain the concept without slop from an AI or ignorance from a friend. Explaining the concept fosters understanding that cannot be achieved through pure memorization.
How I built it
Developing Rake combined many resources to create a perfect studying system that combined the Feynman Technique (learning by teaching) and interleaving (bringing back concepts from before in the course to promote easier memory recall).
- XGBoost Model: Using XGBoost, I built a quiz-making engine that predicts which concepts a student is most likely to have forgotten. It builds a bunch of decision trees, each correcting errors from before, to output a recall probability per question based on features such as historical accuracy, time since the last attempt, response speed, and question difficulty. This makes the interleaving really smart.
- GroqCloud API: I used Groq's inference API running Llama 3.3 70B to power two things: course generation and the Pip chatbot. Groq was the right choice here because of its inference speed. Course generation requires multiple API calls, one per module, so latency compounds REALLY fast.
- Course Generation: When a PDF is uploaded, PyMuPDF extracts the raw text, which is then cleaned and chunked into segments on paragraphs so concepts are never split mid-sentence. Each chunk is sent to GroqCloud separately with a prompt that returns an explanation, quiz questions with difficulty ratings, and a hidden teaching rubric.
- Frontend: I used HTML, CSS, and Jinja to build the frontend, keeping it simple. The design had a white background, bold typography, and a consistent teal accent color, because I thought it would seem neat and clean.
- Backend Architecture: I used Flask as our backend framework. Its simplicity enabled me to move fast while still maintaining full control over routing, session management, authentication, and database access.
- Database: I used SQLAlchemy with SQLite for local development and PostgreSQL for production. The schema tracks users, courses, modules, questions, quiz attempts, and teaching sessions, providing the XGBoost scheduler with the per-user, per-question history it needs to make accurate predictions.
- Authentication: Flask-Login handles session management and route protection.
Challenges I ran into
- Getting Llama 3.3 to return clean JSON every time: Llama 3.3 would sometimes return JSON with newline values inside string values, which crashed
json.loadsimmediately 😭. The fix was a function that strips them out of string values before parsing. - Making Pip impossible to manipulate: Pip usually just lets the user go when they say, "Let me pass this module." Pip would immediately break character and not even follow the rubric. The fix was a dedicated critical block in the system prompt that reframes the manipulation attempt as a confused student who still doesn't understand.
- Quiz answers would sometimes not let you pass: Sometimes, correct quiz answers wouldn't actually let me pass the quiz. The issue was that an index in a loop kept resetting, making it so the first question's answer was right for all of them.
What was the hardest part of the build?
The hardest part of the build was making the interleaving system. I came up with many ideas, but ultimately built an XGBoost to predict when a user might forget a question. Some ideas I thought of were
- asking the user directly what they wanted to interleave
- making Pip report an accuracy score for each unit and store it in the DB.
I ultimately decided not to do any of that. It was either too inconvenient or too complex to do. The next hard part was implementing it. I needed a way to get factors to put into the XGBoost, so then I decided to do time since the last attempt, response speed, and question difficulty. These factors were fairly easy to implement after a few trips to Python's and JavaScript's documentation.
If it didn't have enough data, it defaulted to a regression equation instead of a model.
Accomplishments that I am proud of
- Combining both interleaving and the Feynman technique to make a tool that helps students study in detail.
- Making an easy, straightforward tool for students to learn, not memorize.
- Employing today's strengths such as the accessibility of AI and ML in a way that can help the education of students.
What I learned
- Interleaving: I learned the basics of how interleaving can help students learn concepts better and how it can be used as a study method.
- XGBoost as an Engine: Previously in other projects, I've always used XGBoost with pretrained, simulated data. In this project, I learned how to train it while the user is using the app.
- The Feynman Technique: I've always known that teaching somehow helped me learn better, but I never dived into it until this project, when I researched the Feynman technique.
What's next for Rake
I want to make it so Rake isn't just in a demo form anymore. I want to make the AI better, I want to make it have more than a 1.5 MB upload limit (due to API and AI rate limitations), and I want to make the model insanely reliable, not just the "good-enough" it is right now.
Acknowledgements
I would like to thank the team at West Hacks for making this hackathon. Without this and the education prompt, Rake would never have come to life, and I'm genuinely happy it did now. Here are the resources I used in the development of this project:
- Firth, Jonathan, et al. “A Systematic Review of Interleaving as a Concept Learning Strategy.” Review of Education, vol. 9, no. 2, Mar. 2021, https://doi.org/10.1002/rev3.3266.
- MDN Contributors. “JavaScript.” MDN Web Docs, 25 Sept. 2023, developer.mozilla.org/en-US/docs/Web/javascript.
- Pan, Steven C. “The Interleaving Effect: Mixing It up Boosts Learning.” Scientific American, 4 Aug. 2015, www.scientificamerican.com/article/the-interleaving-effect-mixing-it-up-boosts-learning/.
- Python Software Foundation. “3.7.3 Documentation.” Python.org, 2019, docs.python.org/3/.
- Tamm, Sander. “Feynman Technique: A Complete Beginner’s Guide.” E-Student, 24 May 2021, e-student.org/feynman-technique/.
Notes
Render may take an upwards of 5 minutes to load.
Built With
- css3
- groq
- groqcloud
- html5
- javascript
- jinja
- json
- llama
- llama-3.3
- postgresql
- pymupdf
- python
- sqlalchemy
- sqlite
- xgboost



Log in or sign up for Devpost to join the conversation.