-
-
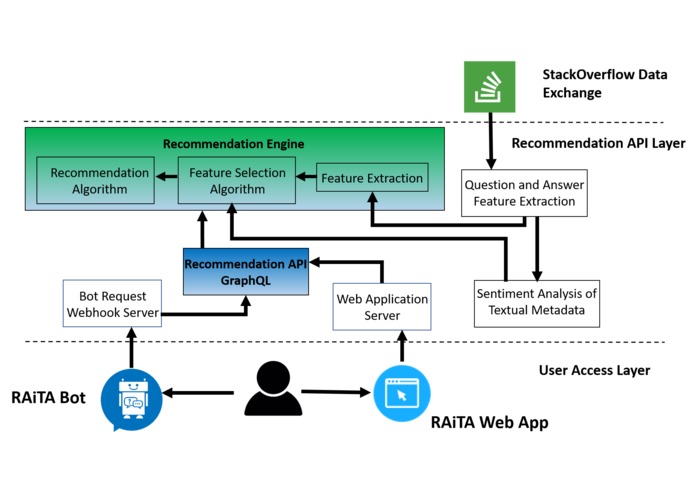
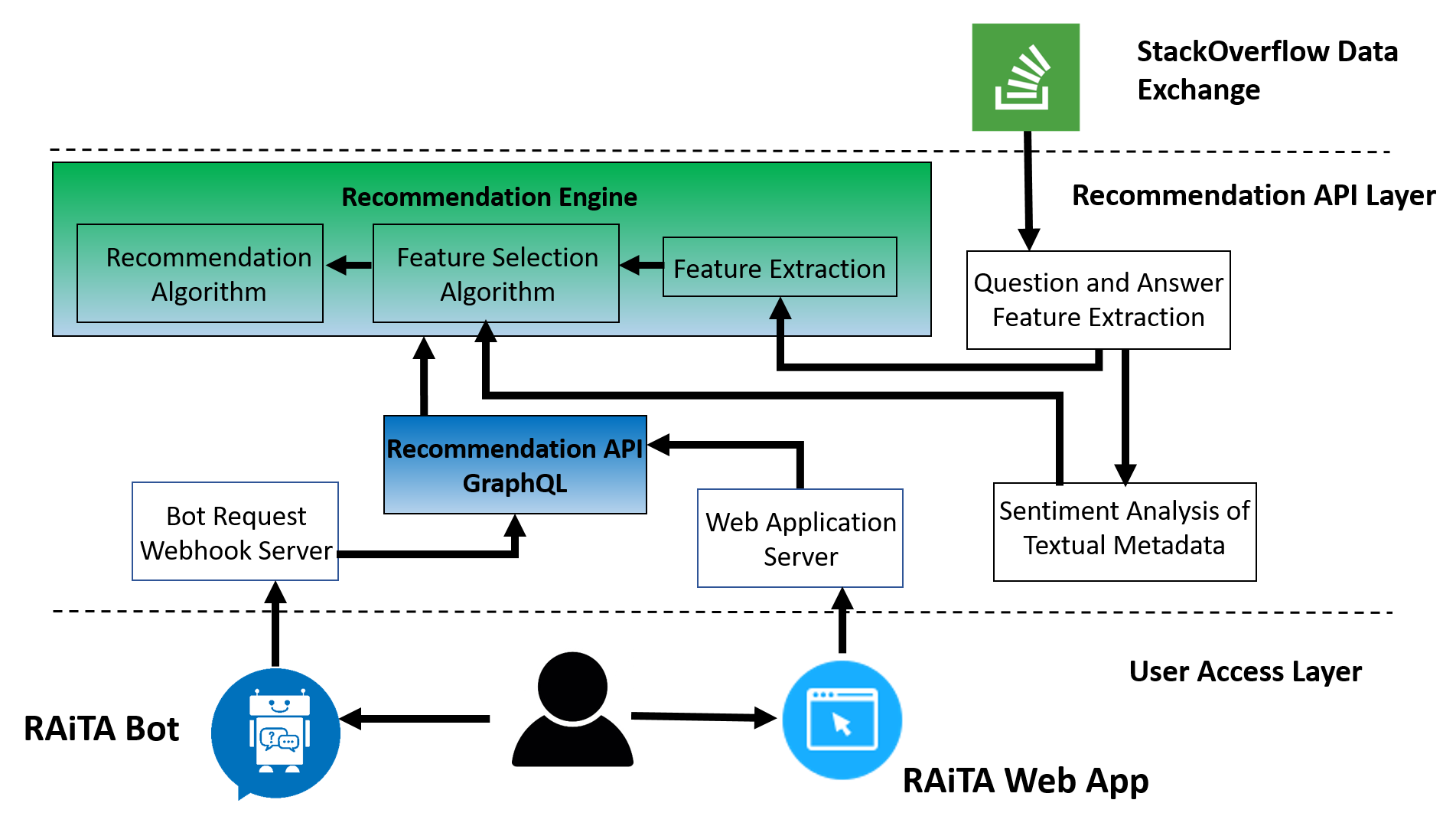
System Architecture of RAiTA System
-
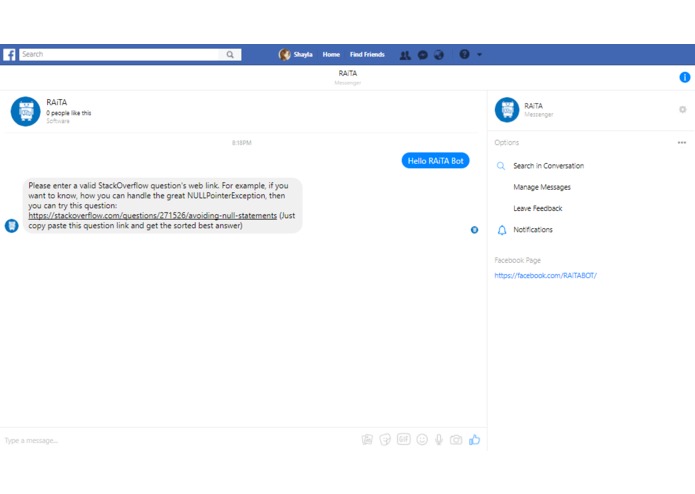
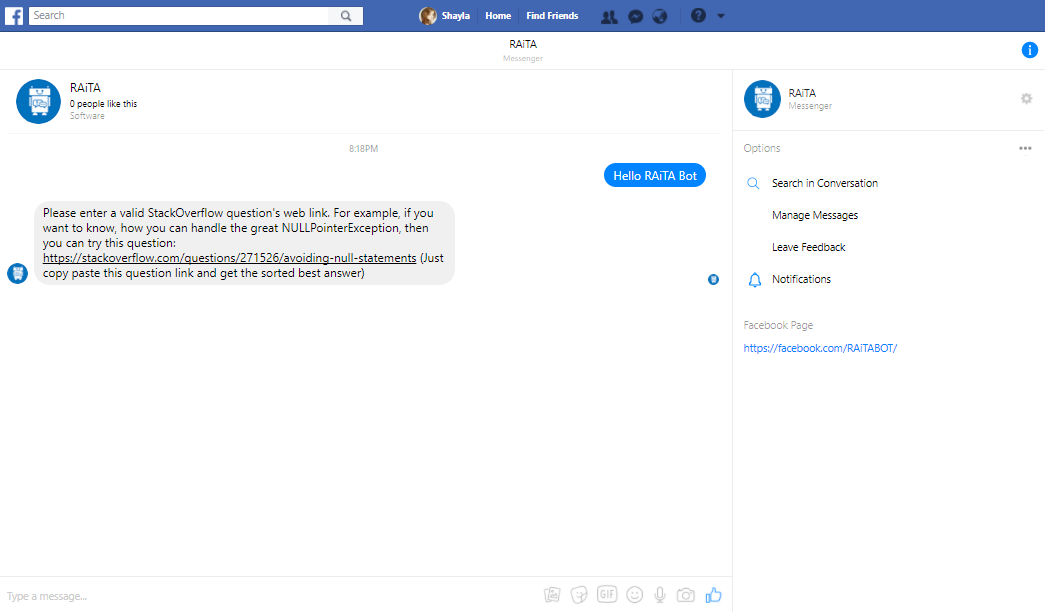
RAiTA Bot Application
-
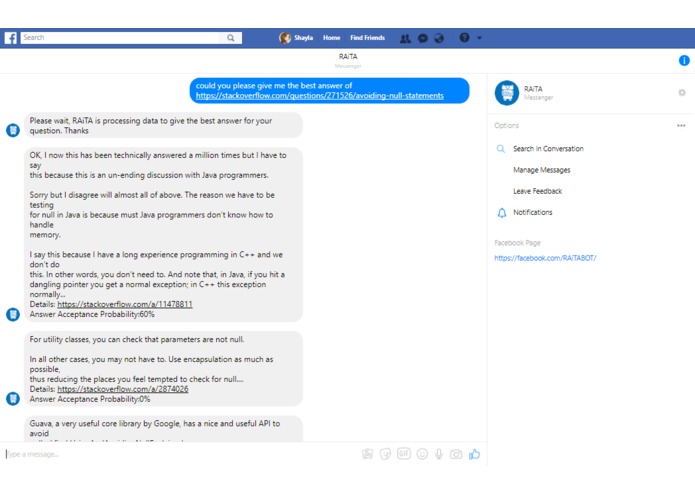
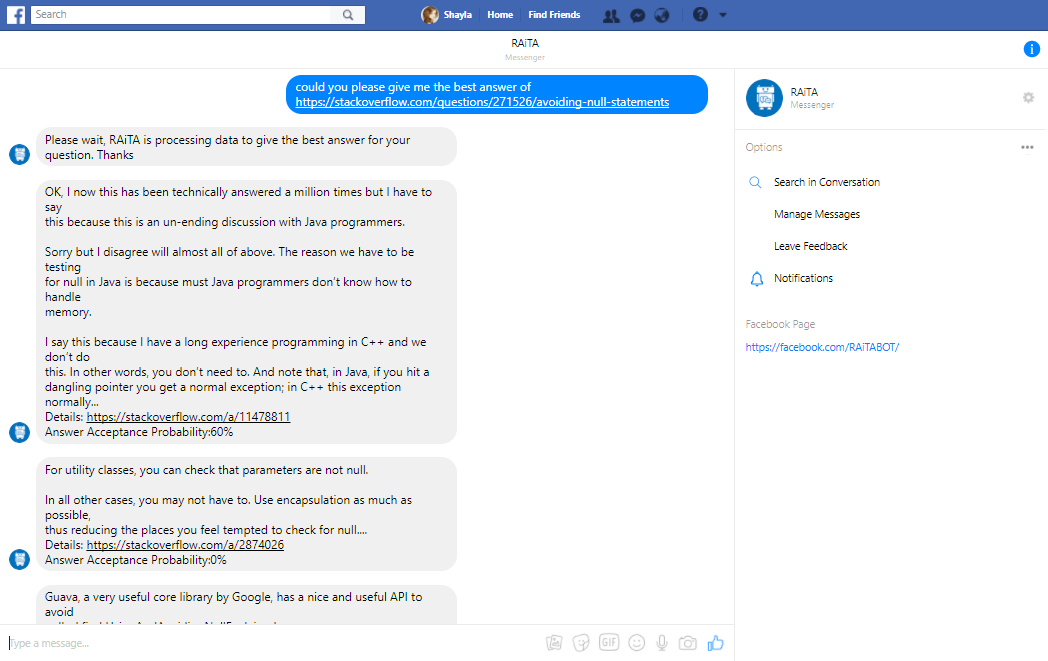
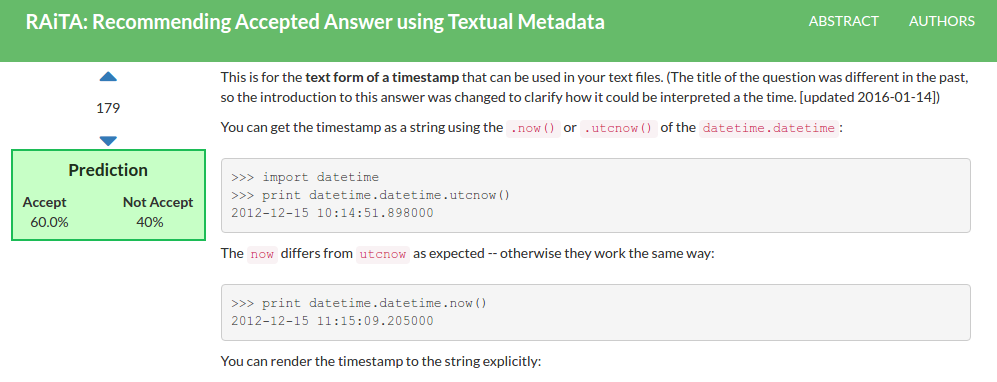
RAiTA Bot Application: Returned the suitable answer for the requested questions
-
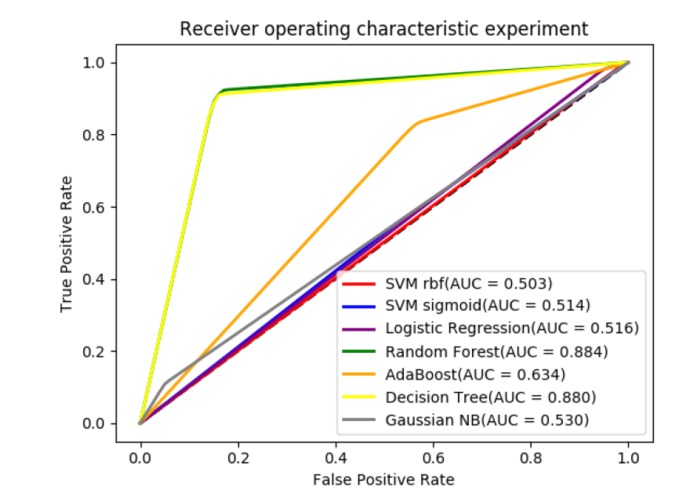
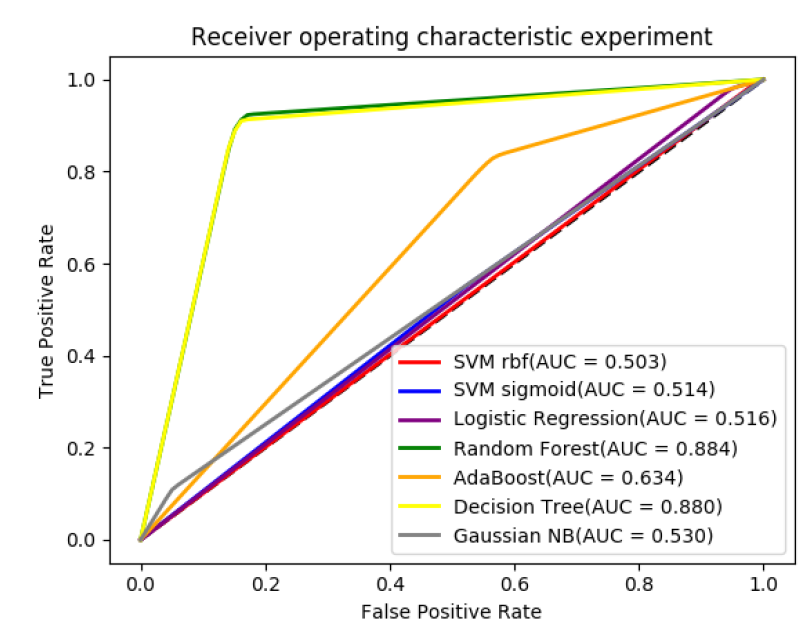
Performance Comparison of Different Machine Learning Approaches
-
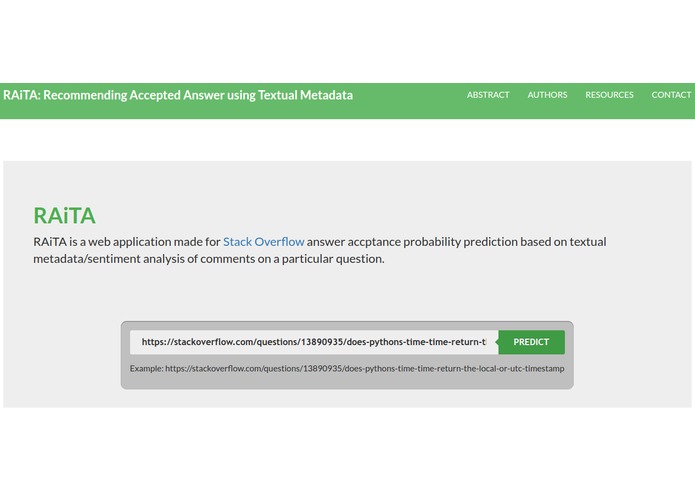
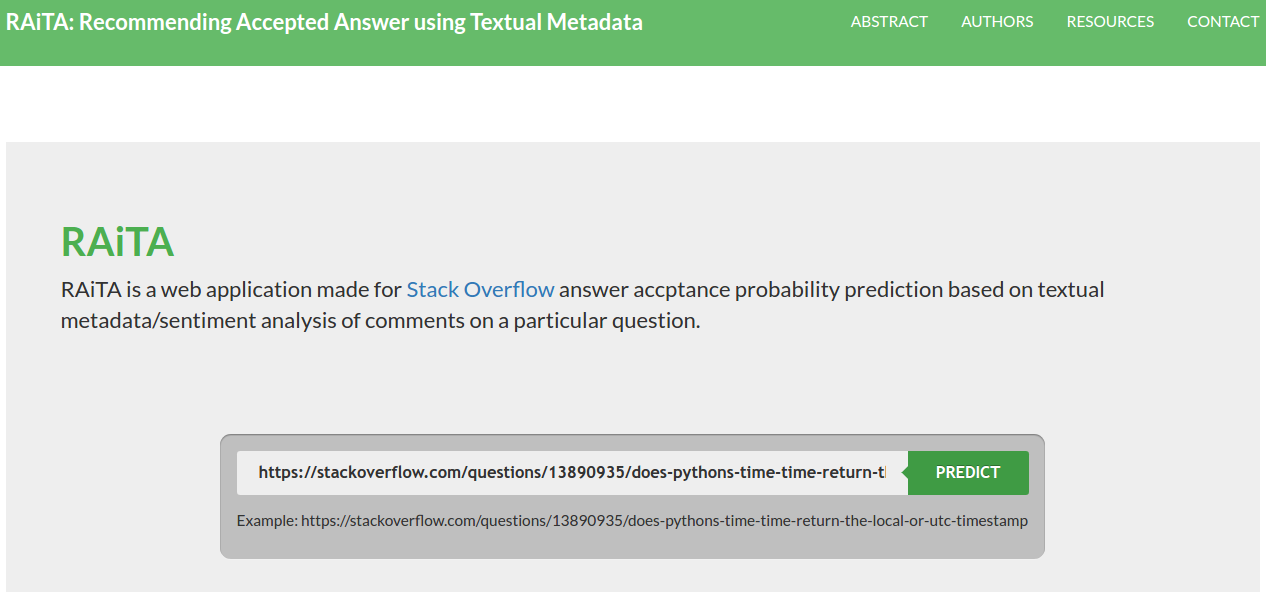
RAiTA Web Application Home Page
-
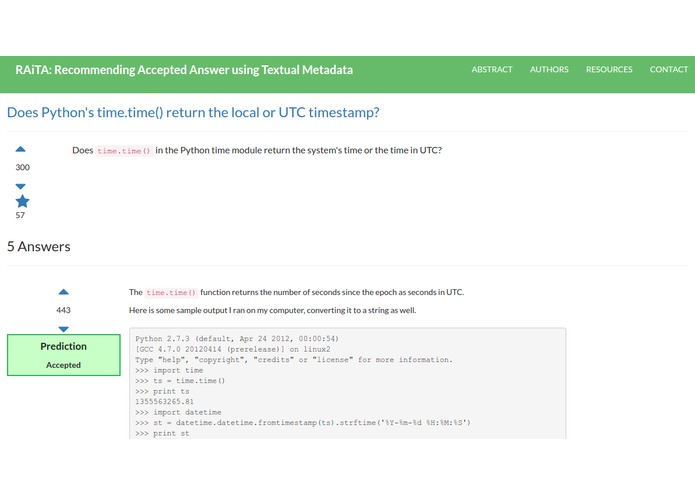
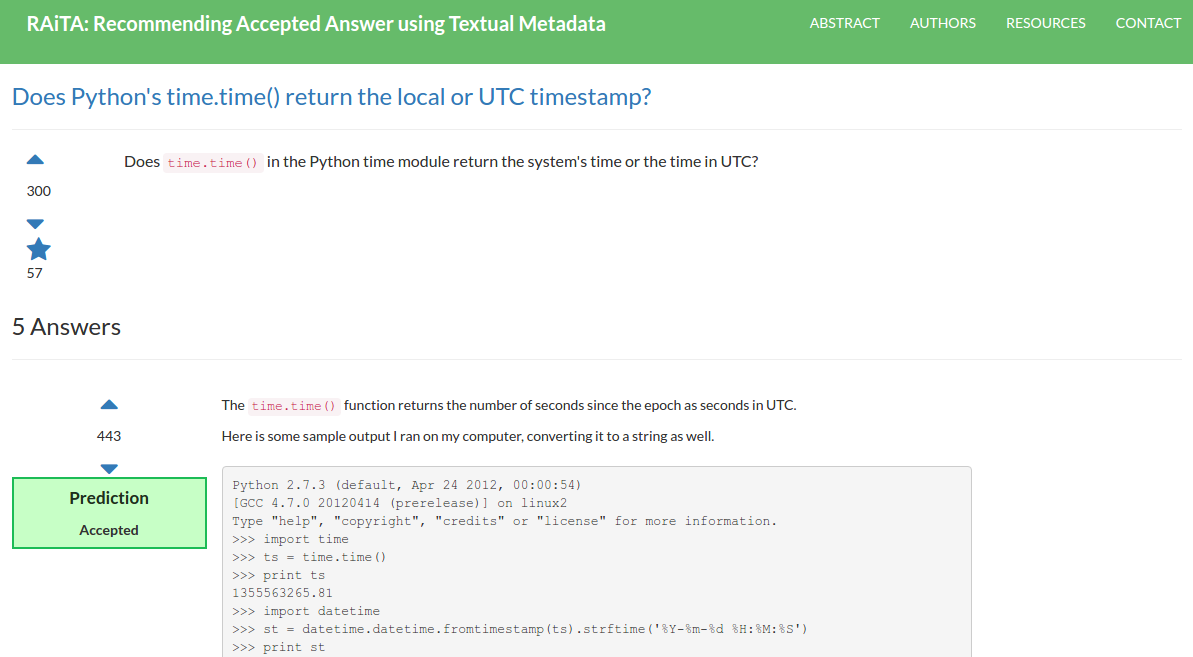
RAiTA Web Application: Result Page
-

RAiTA Web Application: Result Page
-
Application : https://www.facebook.com/RAiTABOT/
This research project is accepted in Springer International Conference on Emerging Technologies in Data Mining and Information Security(IEMIS)-2018. However, it also accepted in IEEE WIECON-ECE-2017 Conference, but we withdraw it due to the VISA issue and resubmit in IEMIS-2018. You can read the full paper here
You can watch the detailed video description of this project from here: https://youtu.be/ONBimYmdgCU
Abstract
With the increasing software developer community, questions answering(QA) sites, such as StackOverflow, have been gaining its popularity. Hence, in recent years, millions of questions and answers are posted in StackOverflow, however, a large number of StackOverflow questions' answers are not marked as accepted answer to help the community for finding the suitable answer for a question. Around 62.8% of the questions in StO have marked the accepted answer. As a result, about 37.2% questions are remaining without any accepted answer marking. As a result, it takes an enormous amount of effort to find out the suitable answer to a question. Luckily, StackOverflow allows their community members to label an answer as an accepted answer. However, in the most of the questions answers are not marked as accepted answers. Therefore, there is a need to build a recommender system which can accurately suggest the most suitable answer to the questions. Contrary to the existing systems, in this work, we have utilized the textual features of the answers' comments with the other metadata of the answers to building the recommender system for predicting the accepted answer. In the experimentation, our system has achieved 89.7% accuracy to predict the accepted answer by utilizing the textual metadata as a feature. We deployed our system as Facebook Messenger Bot Application, which is accessible at https://www.facebook.com/RAiTABOT/, for helping the developer to easily find out the suitable answer for a StackOverflow question. Additionally, we have also deployed our recommendation system as a web application, which is publicly accessible: http://210.4.73.237:8888/.
Major Contribution
The major contributions of this work are summarized bellow:
- The novelty of this work is to utilize the textual metadata (sentiment) with the other factor of the answer's to recommend the accepted answer.
- Rigorous experimentations have been performed to identify the most suitable feature groups which help to sort out the questions' answers.
- A Facebook Messenger Bot application and a web application is developed so that developer can use this recommendation systems to identify the suitable answers.
Motivation
Human life is full of questions. In addition, the Internet makes the world as a village to ease the communication and sharing knowledge with the people. As a consequence, question answering(QA) sites are growing their popularity rapidly. A number of question answering sites, such as StackOverflow, Quora, Yahoo Answer, have already established their reputation up to a limit that people are engaging more and more on those sites to get help with their questions' answer. In these sites, a person can ask questions or answer of any existing questions according. Moreover, they can also redirect the questions to the expert users. As a result, a question may have different answers from different persons.

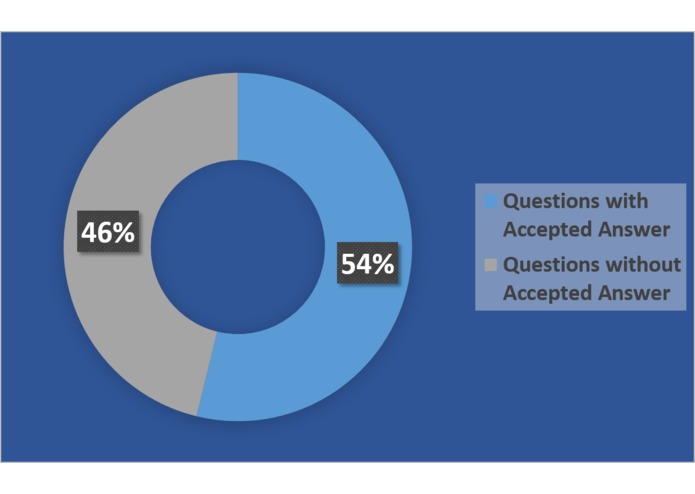
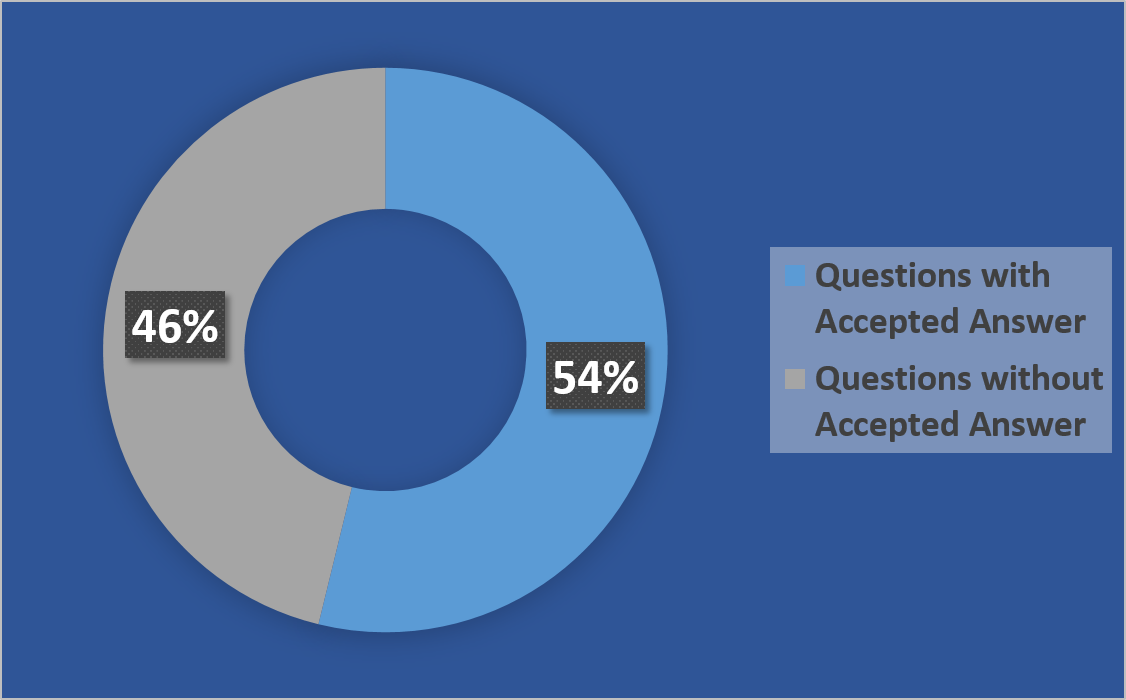
With the increasing participation of people in those sites, the number of questions and answers are increasing very quickly. So, the searching of the most suitable answers is becoming strenuous day by day. At this point, it becomes annoying for a new user who needs urgent answer. Fortunately, some sites allow their community to mark the most suitable answer to a question. For example, till 2017, almost 15 million questions have asked and 23 million answers have given in StackOverflow, however, only 7 million questions' answers' are marked as accepted answers by the StackOverflow community. Hence, almost 50% questions' answers are not marked.
Moreover, some questions', where the answers are marked as accepted, can get new suitable answers than the accepted answers which are not marked as accepted answer. Therefore, QA sites need a recommender system which can rank the answers of questions which help users to get the most suitable answers.
Proposed System : RAiTA Bot
System Architecture
We developed the RAiTA recommendation system as a three layer modular architecture, so that we can easily modify and enhance the system performance. This three layer architecture and GraphQL enable us to separate the recommendation engine layer from the data and user layer. As a result, we can easily modify the recommendation engine layer without modifying the other layer.
StackOverflow Data Exchange Layer
We utilize the StackOverflow data exchange API to extract the questions and answer data, such as question ID, list of answers and their comments. We did not cache the data for our recommendation engine. After extracting the requested question data, it is fed into the recommendation system engine for generating the suitable answers.
Recommendation API Layer
This is the vital layer in the full RAiTA system and it consists of five major elements.
- Recommendation engine
- Recommendation API GraphQL
- Question and Answer Feature Extraction
- Sentiment Analysis of Textual Metadata
- Bot Request Webhook Server
- Web Application Server
Bot Request Webhook Server and Web Application Server serve the Facebook Messenger Bot application or the web application respectively. When any of the server get request, the requested server call the Recommendation API GraphQL engine to extract the the suitable answers for the requested questions. Recommendation API GraphQL engine employs the Recommendation engine to find out the accepted answers. Recommendation API GraphQL engine utilized the GraphQL library to smooth the REST API developing and calling process.

Recommendation engine consists of mainly three major components,
- Recommendation Algorithm
- Feature Selection Algorithm
- Feature extraction
When Recommendation API GraphQL engine calls Recommendation Engine, Feature Extraction module is called to extract the necessary feature data from the StackOverflow data exchange. After extracting the feature data using Question and Answer Feature Extraction module, sentiment Analysis of Textual Metadata is employed to identify the sentiment of the answers' comments using NLTK library. Finally, Feature Extraction module fed the extract and processed sentiment data to the feature selection algorithm to find out the best possible feature from the data.
After getting the selected features, Recommendation Engine employs the pre-trained Recommendation Algorithm for identifying the best possible answer. Then the list of accepted answer is returned through the GraphQL Recommendation API.
User Access Layer
To simplify the user access , we develop two applications, RAiTA Bot and web application. Both the application access the recommendation engine through their corresponding application server, while the application server only calls the recommendation API module to extract the recommendation engine output. As a result, user access layer is completely separate from the recommendation engine, which enable us to easily modify the recommendation approach without modifying the user application.
Feature Selection
Stackoverflow (StO) provides the comments of all the questions and answers with a number of attributes. The attributes contain question details with id, score, view count, comment count etc. It also contain answer related informations as count, score, creation date, comment count, comment score etc. From all the informations, we have used two categories of features to design our prediction model.
Thread features - it contains question title, tags, details, number of responder with response details, question score with favorite count, answer rating, number of commenter with comment score. It also contains view counts as well as timing metadata like question creation time, response time, answer creation time etc.
Textual Metadata - this is a finding from the textual data. It represents the sentiment of the responder as well as commenter whether they are positive, negative or neutral with their comments and responses.
Feature Finalization
To design the prediction model, we have tested Random Forest (RF), Logistic Regression (LR), AdaBoost (AdaB) and Support Vector Machine (SVM). On the other hand, Recursive Feature Elimination (RFE) is used to finalize the features from our feature set. After a extensive experimentation, which is presented in Section\ref{sec:PerfEval}, we have selected 23 attributes from the StO provided attributes list to examine our work. Feature finalization is completed with the following steps.
Thread Features Extraction - all the important attributes related to the thread according to our research are filtered out and added into the feature set to be tested.
Textual Metadata Analysis - after analyzing the text using nltk library\cite{nltk} for each of the comments, we get the sentiment results. The library analyses the comments and return us a sentiment of the text as positive, negative or neutral. Then it is used as a feature.
Feature Elimination - in this step, we have used scikit-learn library to select the features according to the Recursive Feature Elimination method. After the elimination, the feature set is updated.
With the finalized feature set we have tested our prediction model. After that the best result along with others have been shown in Performance Evaluation Section
Performance Evaluations and Discussion
Experimenting with a number of different classifier, our evaluation shows that we have better results. We have evaluated the work using different measures. The datasets and all the results are given below.
Dataset Description
The dataset contains all the comments as well as the metadata of the questions of Stackoverflow. We extracted these questions' data from the StackOverflow Data Exchange system. The information of the experiments dataset is presented in the following table.
| No of Instances | 49992 |
| No of Unique Questions | 20449 |
| No of Unique Answers | 23191 |
| No of Accepted Answers | 12843 |
| Unique Questions without Accepted Answers | 7606 |
| Attributes | 23 |
We exploit the following list of attributes, consists of user information and thread information, the definition of attributes are self explanatory. Attributes: QuestionId, AcceptedAnswerId, QuestionScore, QuestionViewCount, Question, QuestionCreationDate, QuestionOwnerUserId, Title, Tags, AnswerCount, QuestionCommentCount, QuestionFavoriteCount, AnswerId, AnswerScore, Answer, AnswerCreationDate, AnswerOwnerUserId, AnswerCommentCount, CommentId, CommentScore, Comment, CommentCreationDate, CommentUserId.
Effectiveness of Sentiments in Accepted Answer
The textual metadata as sentiment is very effective in our work. We have tested the effect of sentiments a number of times in our prediction model. The summary of the experiment without feature optimization is shown in the following table.
| Accuracy | Sensitivity | Specificity | AUC | MCC | |
| Feature & Sentiment | 0.897 | 0.848 | 0.923 | 0.886 | 0.774 |
| Only Features | 0.888 | 0.835 | 0.918 | 0.876 | 0.755 |
| Only Sentiment | 0.65 | 0.024 | 0.994 | 0.509 | 0.079 |
*All the simulation is done under 10-Fold validation
Analyzing the results in the above table, we see that the model works better with 89.7% accuracy, AUC and MCC values, 0.886 and 0.774 respectfully, are also significant without any optimization of feature set.
Classifier and Feature Selection and Evaluation
In this work, Random forest (RF), Logistic Regression (LR), AdaBoost (AdB) and Support Vector Machine (SVM) are tested to find the best suited classifier as well as feature set. The experimental result is shown in the following table.
| RF | LR | AdB | SVM | |
| No of features 11 | 88.17 | 66.03 | 69.69 | 83.77 |
| No of features 10 | 88.45 | 66.12 | 69.68 | 82.50 |
| No of features 9 | 88.09 | 66.11 | 69.60 | 81.31 |
*All the simulation is done under 10-Fold validation.
From the result in the above table, Random forest gives the best result of 88.45% accuracy with a set of 10 features. So, we have selected Random Forest classifier for our prediction model. And the list of selected attributes are: AnswerCommentCount, AnswerCount, AnswerScore, CommentScore, Neutral, Positve, QuestionCommentCount, QuestionFavoriteCount, QuestionScore and QuestionViewCount.
Moreover, the final prediction model is tested with different classifier and evaluated the quality and effectiveness according to various measures. The evaluation result is shown in the following table.
| Classifier | Accuracy | Sensitivity | Specificity | AUC | MCC |
|---|---|---|---|---|---|
| SVM(sigmoid) | 0.651 | 0.048 | 0.981 | 0.514 | 0.03 |
| SVM(rbf) | 0.648 | 0.005 | 1 | 0.503 | 0.057 |
| Logistic Regression | 0.652 | 0.051 | 0.981 | 0.516 | 0.09 |
| Random Forest | 0.897 | 0.848 | 0.923 | 0.886 | 0.774 |
| AdaBoost | 0.692 | 0.436 | 0.832 | 0.634 | 0.291 |
| Decision Tree | 0.890 | 0.851 | 0.911 | 0.881 | 0.76 |
| Gaussian Naive Bayes | 0.408 | 0.949 | 0.111 | 0.530 | 0.1 |
*All the simulation is done under 10-Fold validation.
After analyzing the above table data, we see that Random Forest classifier achieves the best accuracy, AUC and MCC value as 89.7%, 0.886 and 0.774 respectfully. Moreover, the other classifiers achieve significant accuracy too. The achievement in AUC value is visually represented in the following figure.

Challenges I ran into
The main challenge to design an accepted answers recommender system is to select the appropriate set of features which enable us to accurately select the accepted answers. QA sites, such as StackOverflow, Quora, Yahoo Answer, are providing some information(metadata) along with the answers. With the help of metadata associated with the questions and the answer, we can predict the accepted answer for a particular question. In this work, we have focused on the textual metadata of the answers with other factors provided by a question answering site. As there are a number of question answering sites, it is a tough decision to take one for our work. In this situation, we have taken StackOverflow as it is the largest and most trusted online community for developers throughout the recent years. Moreover, in StackOverflow, a lot of questions are not labeled as accepted answers. To overcome this situation, we have designed a recommender system to sort out the answers.
Conclusion and Future Work
As the popularity of Stackoverflow is increasing day be day, more people will rely on it to give and to get their answers. So, it is the time to confirm the acceptance of the answers for each and every questions using an automated system.
In order to find the accepted answer, we design our recommendation bot application, RAiTABot. It uses answers' metadata information with sentiment analysis to find the accepted answer for each answered questions. After a extensive experiment, the model is proven to be efficient and effective to find the accepted answers. The result shows that it can predict the accepted answer up to 89.7%. The AUC and MCC value for the model is also significant. Moreover, the model has fully functional Facebook Messenger Bot Application, RAiTABot, and a web application. In addition, the web application 'RAiTA', is very handy to use which has an user friendly interface too.
Future Work
The success of finding accepted answer in Stackoverflow has interested us to extend the system to design an adaptive recommender system for other QA services like Quora, Yahoo, ResearchGate etc, which can learn and transfer the knowledge. Furthermore, other textual features can be utilized to improve the prediction performance.
Moreover, we have a plan to use multi-modality learning approach so that our trained model for one social network can be easily used in another domain. In this context, we need deep learning approach and we want to employ adaptive deep modular neural network where the out-domain feature will be incorporated into the in-domain feature to improve the recommendation approach. For this purpose, we want to utilized the caffe2.ai deep learning framework to build our recommendation model. Additionally, we can easily change the recommendation system without changing the bot or web application system, as we develop the whole system in a modular way.
Built With
- facebook-messenger
- graphql
- machine-learning
- natural-language-processing
- scikit-learn
- stackoverflow-data




Log in or sign up for Devpost to join the conversation.