Inspiration
Large Language Models can generate text with remarkable fluency, but when it comes to recipes, they often fail — producing vague and inaccurate dishes. We wanted to address this inefficiency by combining LLMs with real-world data. That’s where the idea for RAGRecipes came from: an AI-powered cooking assistant that uses Retrieval-Augmented Generation (RAG) to craft data-backed recipes in real time.
What it does
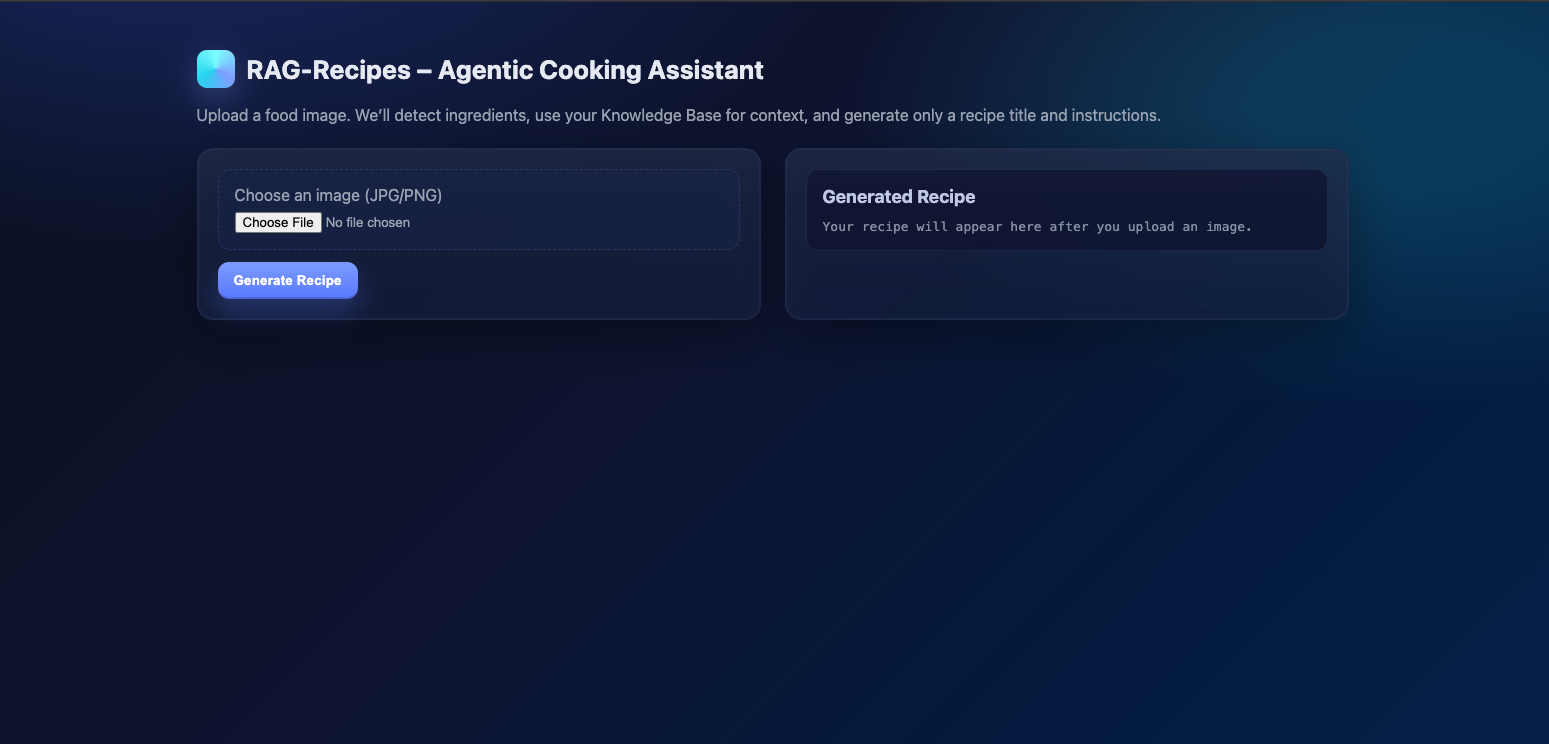
RAGRecipes allows users to upload an image of their ingredients. The system identifies what’s in the image, retrieves the most relevant recipes from a massive recipe database, and uses an LLM to generate a detailed, coherent recipe tailored to what the user already has. Instead of generic or hallucinated suggestions, users get context-aware, grounded recipes pulled from real data.
How we built it
First we implemented the GoogleVision API to properly detect items in an image, acting as our base CV model. Next, we sanitized data using Amazon Bedrock, removing any extraneous non-food items.
Then, we used the RecipeNLG dataset as our foundation and stored it in an Amazon S3 bucket as a CSV file. This served as our knowledge base. We built a RAG pipeline using:
Amazon Titan V2 embeddings model for vectorizing the recipe data.
Amazon Bedrock LLM for generation.
A vector database in Amazon’s knowledge base for efficient retrieval.
When a user submits an image, the app extracts ingredient names, converts them into embeddings, retrieves the most relevant recipes based on cosine similarity, and feeds that context into the Bedrock model to produce a final recipe output. Our frontend was built with Flask+HTML/CSS, and the backend used Python for simplicity and fast iteration.
Challenges we ran into
One major challenge was with custom chunking of our recipe CSV. We initially planned to use AWS Lambda to split data into structured components (ingredients as data, recipes as metadata), but ran into memory and serialization issues after hours of testing. We ultimately switched to a simpler, fixed-size chunking method that worked reliably.
We also faced hosting challenges. Our initial plan to deploy the backend via AWS Lambda or Google Cloud Run with FastAPI endpoints ran into dependency conflicts and route errors. We pivoted to a Flask-native backend to ensure smooth communication between frontend and backend.
Accomplishments that we're proud of
Successfully implementing a fully functional RAG pipeline from scratch using Amazon Bedrock and Titan embeddings.
Integrating a large real-world dataset (RecipeNLG) into a searchable, vectorized knowledge base.
Building a clean, functional Flask frontend connected to a Python backend.
Turning a concept about inefficient recipe generation into a working prototype that demonstrates retrieval-augmented generation in a practical domain.
What we learned
How to integrate retrieval-augmented generation with real-world datasets effectively.
How to build and tune an embedding-based retrieval system using Amazon Titan.
The value of keeping systems simple: a custom chunking function isn’t always worth the complexity.
What's next for RAGRecipe
We plan to:
Improve the chunking mechanism with a custom AWS Lambda function (splitting data and metadata into separate text and json files respectively)
Integrate real-time ingredient detection from images using a lightweight computer vision model.
Expand our recipe database beyond RecipeNLG to include user-generated and trending recipes.
Improve personalization by factoring in user preferences, dietary restrictions, and available kitchen equipment.
Deploy a production-ready version using AWS Lambda + API Gateway, and refine our retrieval architecture for faster query times.
Our goal is to make RAGRecipes the go-to AI cooking assistant, overall smart, context-aware, and built on real data.
Built With
- amazon-web-services
- bedrock
- css
- flask
- html
- python
- s3
- visionapi




Log in or sign up for Devpost to join the conversation.