-
-
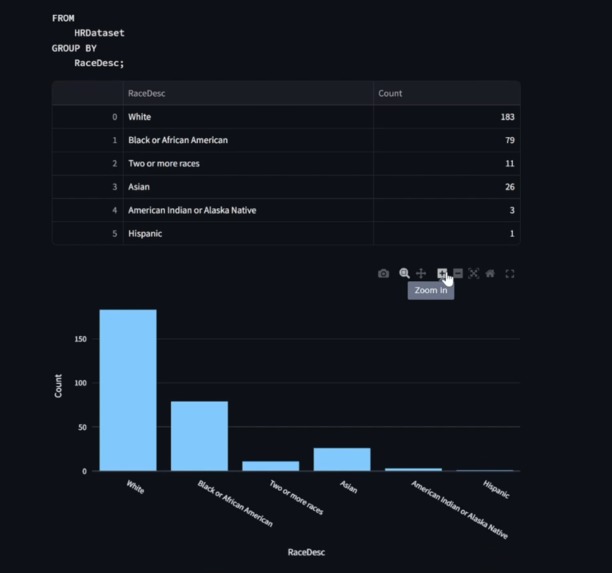
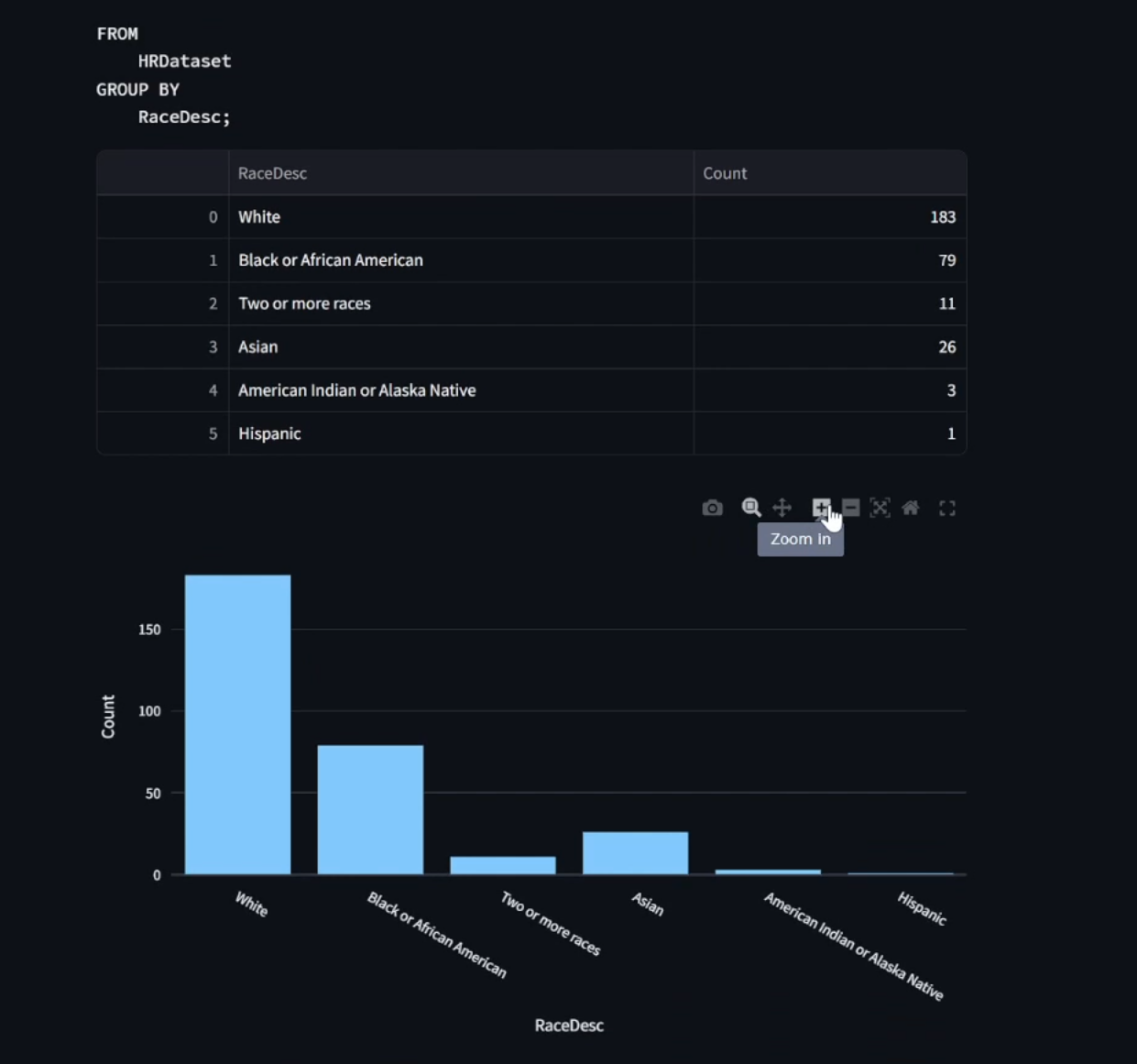
A graph and table created by our model for the prompt "show distribution of races"
-
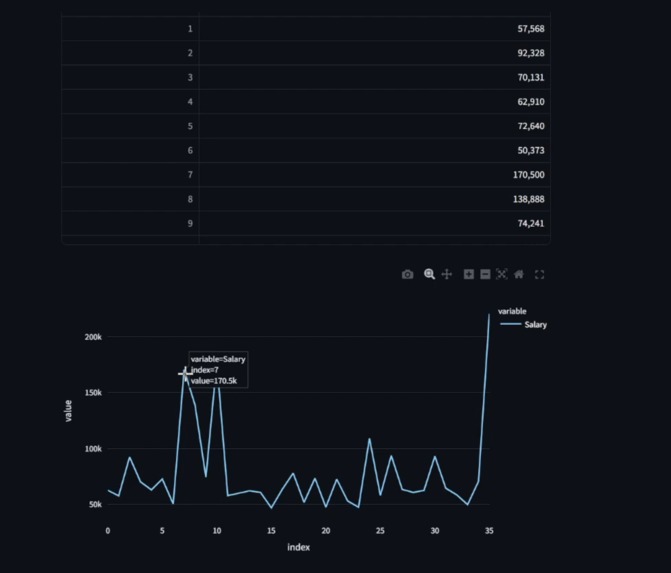
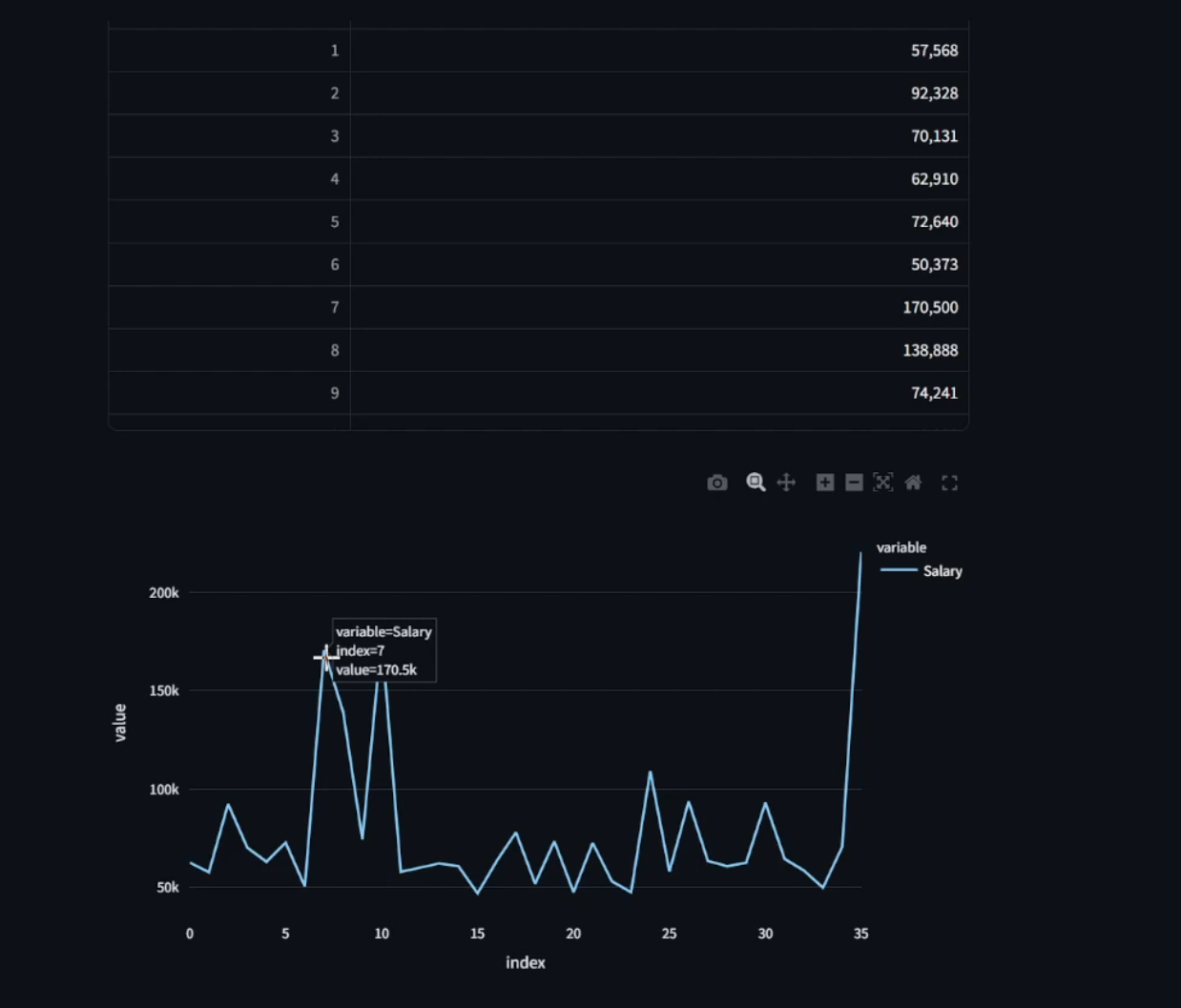
A graph and table created by our model for the prompt "What is the salary of employees with highest performance score"
-
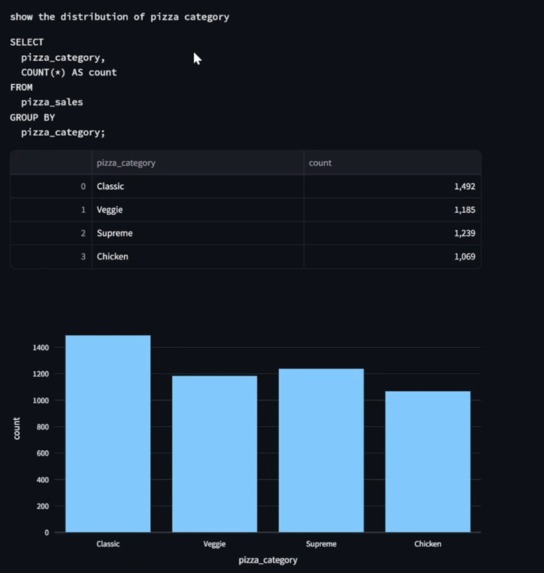
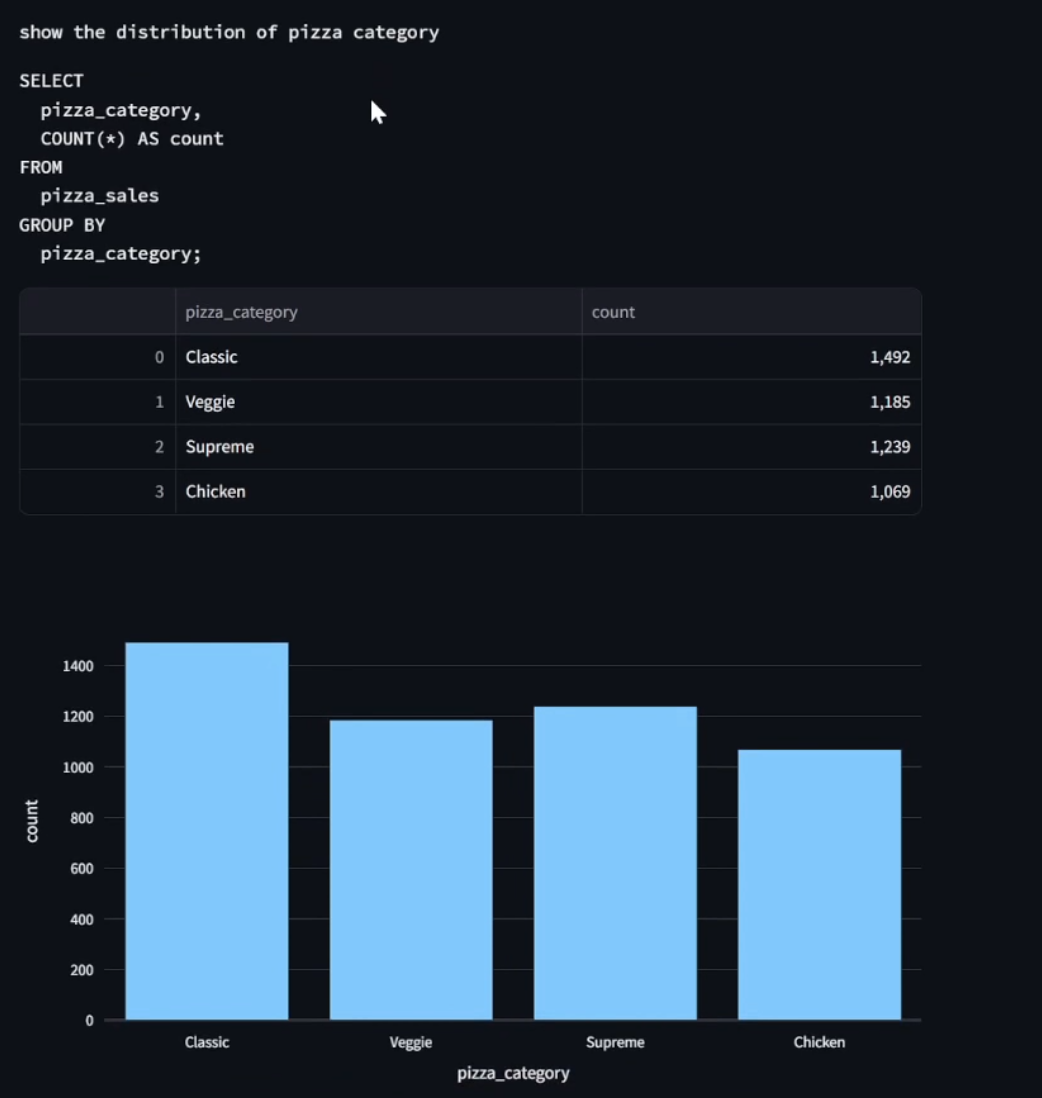
A graph and table created by our model for the prompt "show the distribution of pizza category"
Inspiration
The idea for our project stemmed from the growing frustration we observed in organizations that possess vast amounts of valuable data but face challenges in making it accessible to all business users. During our research, we identified a significant skills gap. While data analysts and engineers can comfortably access and interpret data using advanced SQL and a deep understanding of organizational data structures, most non-technical users — such as product managers, sales executives, and marketing teams — struggle to obtain timely insights. These users often have pertinent business questions but lack the SQL expertise needed to explore the data independently. This reliance on data teams creates bottlenecks, limiting agility and slowing down the decision-making process.
We interviewed more than ten startups at the IIT Madras Incubation Center and discovered that this challenge is prevalent across industries. Startups in particular suffer because they need to be nimble, and delays in accessing data can stifle innovation. We were inspired to create a solution that democratizes data access, allowing any team member to query organizational data using natural language, reducing dependency on data analysts, and speeding up decision-making.
What it does
Our system leverages a Retrieval-Augmented Generation (RAG) model that can be trained on an organization's specific data, including its unique database schema and metadata. This allows the model to not only understand the structure of the data but also generate SQL queries that are highly contextualized to the organization's datasets.
Once trained, users can interact with the system through various interfaces — such as Jupyter Notebooks, Streamlit apps, or a web-based UI — where they can input natural language queries. The model uses intelligent retrieval mechanisms to fetch relevant schema and database information, generating an SQL query that accurately represents the intent behind the user’s question.
The generated SQL query is then automatically executed on the database, returning results in a clean, easy-to-understand format. This system removes the technical barrier of needing to know SQL and the underlying data structure, empowering non-technical users to perform data analysis independently. The RAG model’s training ensures that each subsequent query is better optimized for the organization’s unique data, continually improving the quality and relevance of the SQL generated.
How we built it
We developed the system by first identifying key pain points in how business users interact with organizational data. Understanding that each organization has its own complex data schema, we focused on building a model that could learn from the metadata of a database and the relationships between various tables and fields.
To accomplish this, we implemented a RAG framework, where we trained the LLM on both the natural language understanding and the schema of the specific databases being used. We integrated metadata about each database — such as table relationships, field types, and index data — so that the model could intelligently map natural language questions to SQL queries.
First, we train the RAG model using the schema and data from the tables we intend to query. This data is converted into embeddings, capturing semantic relationships and stored efficiently in a vector database. When a user inputs a natural language prompt, it too is transformed into embeddings, which are then searched within the vector database to retrieve relevant context from the stored data. Once the most relevant context is identified, it is passed to a large language model (LLM), which uses the information to generate an SQL query. The generated query is executed against the database to extract the requested data, which is then formatted and presented in a user-friendly manner, enabling quick and accurate access to insights.
For user interfaces, we developed prototypes in Streamlit, Jupyter Notebooks, and a custom web UI built using React. Each interface allowed seamless natural language querying, with the backend handling the heavy lifting of SQL generation and database querying.
Challenges we ran into
One of the key challenges we faced was creating a model that could accurately understand the nuances of organizational data. Each organization has its own unique data schema, often with complex relationships between tables that aren’t always intuitive. Training a model that could not only parse natural language questions but also map them correctly to these unique data structures required significant experimentation.
Another major challenge was ensuring that the SQL generated by the model was not only accurate but also optimized for performance. Databases with millions of rows can quickly become slow if queries are not well-constructed. We had to integrate performance optimization techniques into the SQL generation process, such as automatically including indexes where necessary or structuring queries to minimize joins.
Lastly, we faced hurdles in designing an intuitive user interface. Non-technical users often have no experience with querying data, so the challenge was to create an interface that made it as simple as typing a question in natural language while still offering flexibility for more advanced queries. Ensuring that the system could handle a wide range of user inputs and provide meaningful results without the need for SQL knowledge was key to overcoming this challenge.
Accomplishments that we're proud of
One of our biggest accomplishments is successfully bridging the gap between technical and non-technical users when it comes to accessing and interpreting data. Our system enables users with no SQL knowledge to query complex datasets and get accurate, contextualized insights.
We’re proud of the efficiency of our RAG model in learning the intricacies of an organization’s data schema and producing highly optimized SQL queries. This ensures that users get the right data in a timely manner, without needing to go through layers of approval or depend on data teams.
Another significant accomplishment was the versatility of our system. The fact that it can be used across different platforms (Jupyter, Streamlit, web-based UI) and adapted to any organization’s data infrastructure makes it an ideal tool for startups, large enterprises, and everything in between.
What we learned
Throughout this project, we learned a great deal about the complexities of creating SQL generation models that can handle unique and intricate data schemas. We discovered that while natural language processing is advancing rapidly, it’s crucial to combine it with detailed metadata about the database itself to achieve high accuracy.
We also learned how important user experience is in building data tools. The most advanced system is only useful if users can easily interact with it, so balancing technical performance with user-friendly design was a valuable lesson.
Additionally, we deepened our understanding of optimizing SQL queries, learning how to build queries that are not only correct but also efficient for large-scale datasets. This project has helped us master the art of data retrieval, performance optimization, and NLP in real-world business applications.
What's next for RAGdash
Moving forward, we plan to further enhance the intelligence of our RAG model, improving its ability to learn from new datasets and adapt to changes in an organization’s data structure over time. We aim to integrate more advanced machine learning techniques for automatic query optimization, reducing query execution times even further.
We also want to expand the system’s capabilities beyond SQL. Our goal is to allow users to not only query data but also trigger automated actions based on the results, such as sending reports or updating dashboards. Additionally, we plan to add support for more databases and cloud storage systems, ensuring that the platform can be integrated into any organizational data environment.
Lastly, we aim to explore the potential of voice-based interaction, allowing users to ask questions verbally and receive answers in both text and voice formats, making data querying even more accessible. We believe that these features will make the system an indispensable tool for organizations of all sizes, ensuring that everyone, regardless of technical expertise, can leverage the power of data to make better decisions.

Log in or sign up for Devpost to join the conversation.