-
-
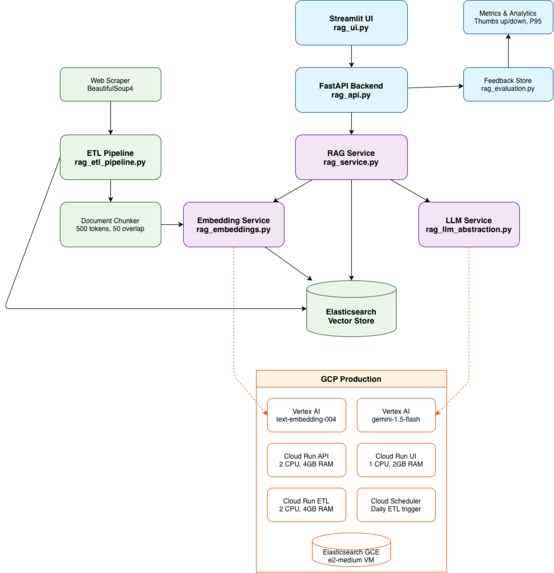
Architecture
What Inspired This Project
As a DevOps engineer, I found myself constantly searching through internal documentation, troubleshooting guides, and knowledge bases to solve infrastructure challenges. Traditional search tools often returned irrelevant results or outdated information, making it difficult to find the right solutions quickly.
I was inspired to build this RAG system after seeing how AI-powered search could transform how we access and utilize organizational knowledge. The idea was to create a system that could understand the intent behind queries and provide contextual, accurate answers based on our actual documentation and runbooks.
What I Learned
Building this RAG system taught me several key concepts that are crucial for DevOps engineers working with AI:
RAG Architecture Fundamentals
- Embeddings: How text gets converted to numerical vectors for semantic search
- Vector Databases: Why Elasticsearch with HNSW indexing is powerful for similarity search
- Retrieval Strategies: Balancing recall vs. precision in document retrieval
- Token Management: Critical importance of staying within LLM token limits (20k for Vertex AI)
Production Considerations
- Scalability: Auto-scaling Cloud Run services with proper resource allocation
- Cost Management: Hybrid local/GCP deployment to minimize operational costs
- Monitoring: Comprehensive logging and metrics for system health
- Security: VPC networking and IAM roles for secure cloud deployments
DevOps Integration Patterns
- Infrastructure as Code: Terraform for reproducible GCP deployments
- CI/CD: Cloud Build for automated Docker image building and deployment
- Container Orchestration: Docker Compose for local development, Cloud Run for production
- Configuration Management: Environment-specific configs with proper secrets handling
How I Built This Project
Phase 1: Core RAG Implementation
# Key architectural decisions:
# 1. Multi-provider abstraction for LLMs and embeddings
# 2. Elasticsearch as vector store with HNSW indexing
# 3. Document chunking with overlap for better retrieval
# 4. RESTful API design with FastAPI
Phase 2: Production Deployment
- Local Development: Docker Compose with Ollama for cost-effective testing
- GCP Production: Cloud Run services with Vertex AI for enterprise-grade performance
- Infrastructure: Terraform for reproducible, version-controlled deployments
Phase 3: DevOps Integration
- Monitoring: Comprehensive metrics and logging
- Cost Optimization: Pause/resume scripts for development environments
- Documentation: Complete guides for local and production deployment
Challenges I Faced
Token Limit Management
Challenge: Vertex AI embeddings have a 20,000 token limit, but some documents exceeded this during ingestion.
Solution: Implemented intelligent chunking with token validation:
def count_tokens(text: str) -> int:
"""Accurate token counting with tiktoken"""
encoding = tiktoken.get_encoding("cl100k_base")
return len(encoding.encode(text))
# Automatic truncation for oversized chunks
if token_count > 15000: # Conservative buffer
text = truncate_text(text, target_tokens=15000)
Hybrid Local/Cloud Deployment
Challenge: Balancing development efficiency with production capabilities.
Solution: Created dual deployment modes:
- Local: Ollama + sentence-transformers for rapid iteration
- Production: Vertex AI for enterprise-grade performance
- Unified Interface: Same API regardless of backend
Infrastructure Complexity
Challenge: Managing VPC networking, IAM roles, and service dependencies in GCP.
Solution: Infrastructure as Code with Terraform:
# VPC connector for Cloud Run → GCE communication
resource "google_vpc_access_connector" "connector" {
name = "rag-vpc-connector"
ip_cidr_range = "10.8.0.0/28"
network = "default"
region = "us-central1"
}
Cost Optimization
Challenge: GCP costs can escalate quickly with always-on services.
Solution: Implemented cost management strategies:
- Pause/Resume Scripts: Stop Elasticsearch VM when not needed
- Auto-scaling: Cloud Run scales to zero when idle
- Local Development: Complete local stack for testing
DevOps Applications
This RAG system demonstrates several DevOps principles:
Observability
- Metrics: Query latency, satisfaction rates, cost tracking
- Logging: Structured logging with correlation IDs
- Health Checks: Service health monitoring and alerting
Reliability
- Error Handling: Graceful degradation and retry logic
- Circuit Breakers: Protection against cascading failures
- Data Consistency: Proper indexing and change detection
Scalability
- Horizontal Scaling: Auto-scaling Cloud Run services
- Performance: Optimized vector search with HNSW indexing
- Efficiency: Batch processing and connection pooling
Built With
- artifact-registry
- cloud-build
- cloud-run
- compute-engine
- elasticsearch
- fastapi
- gcp
- iam
- python
- streamlit
- terraform
- vertex
- vpc

Log in or sign up for Devpost to join the conversation.