-
advance Rag
This structure is excellent! It provides a clear, comprehensive narrative about the project. Here is the revised "About" section in that format, based on the CodeSpire3 analysis:
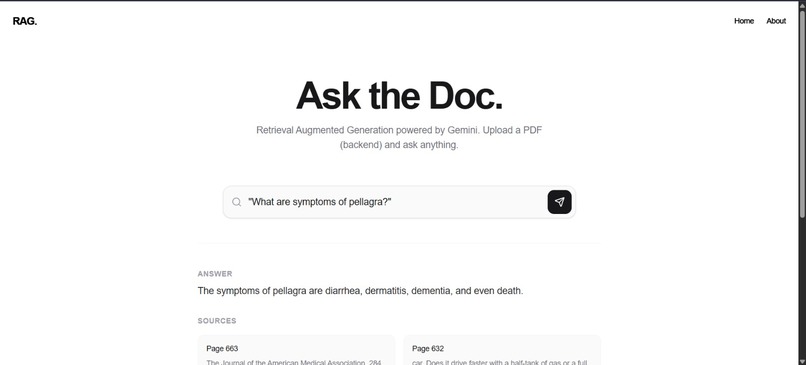
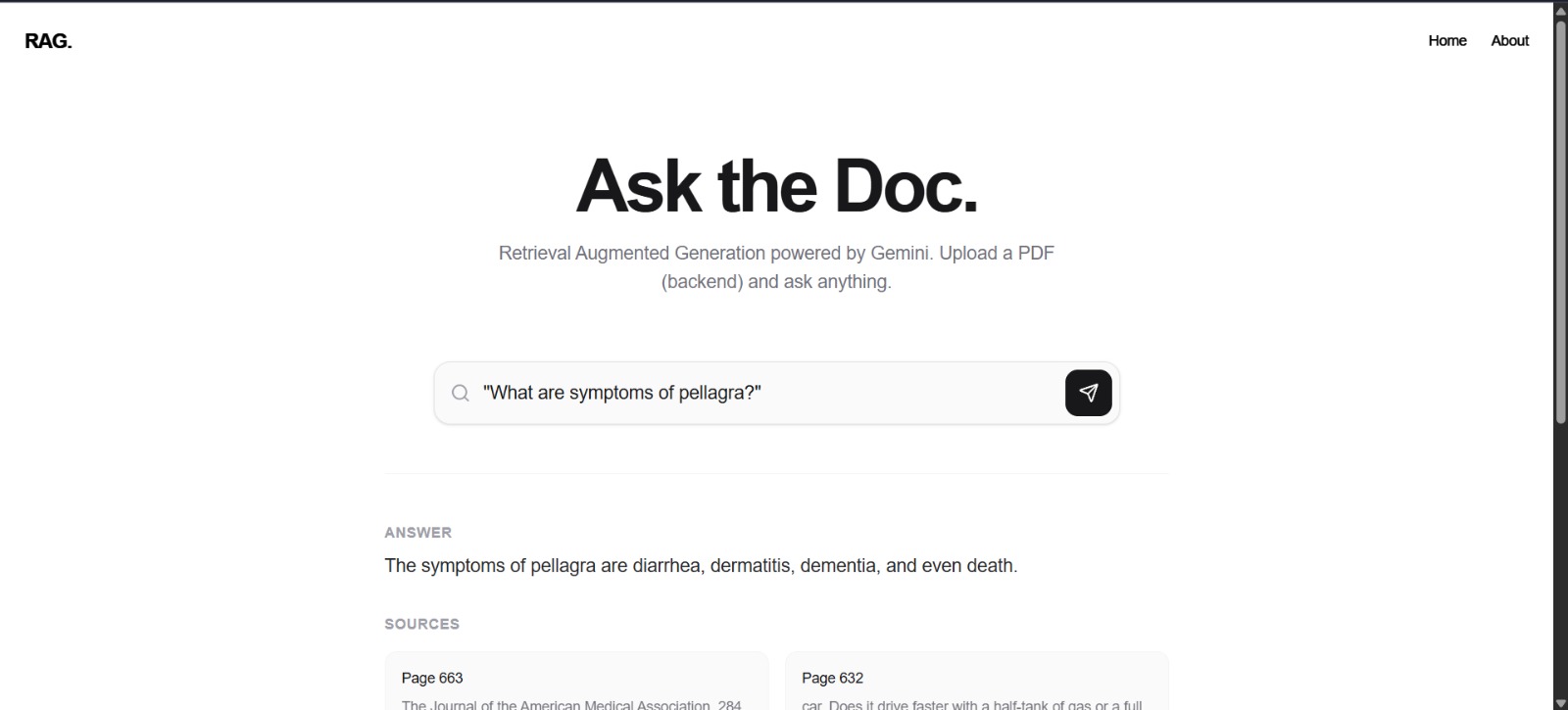
🌟 Inspiration The core inspiration was born from the recognized limitation of traditional Large Language Models (LLMs): the tendency to "hallucinate" and the inability to access current or proprietary domain-specific knowledge. We wanted to fuse the unparalleled reasoning power of Google's Gemini model with a reliable, verifiable knowledge source. The goal was to demonstrate how Retrieval-Augmented Generation (RAG) could be implemented as a complete, modern web service to provide 100% grounded answers from a specific document.
💡 What it Does CodeSpire3 is a live demonstration of a full-stack, document-centric RAG system. It allows users to:
Ask complex questions about the content of a specific PDF document (the knowledge source).
Receive accurate and factual answers generated by the Gemini model.
The system first retrieves the most relevant text snippets from the document and then uses those snippets as context for the LLM, ensuring the response is grounded in the source material.
It provides a highly responsive and visually appealing user interface built with React.
🛠️ How We Built It The project was executed in three concurrent tracks:
RAG Core: We used PyMuPDF to extract text from the PDF, segmented it into meaningful chunks, and created vector embeddings using SentenceTransformers. This logic was prototyped in the Rag.ipynb notebook to validate the retrieval mechanism.
FastAPI Backend: We built a high-performance REST API using FastAPI in Python. This server encapsulates the entire RAG pipeline and integrates the Google GenAI SDK to communicate with the Gemini model. It accepts the user query, performs the vector search, and formats the response.
React Frontend: We utilized React with Vite for rapid development. Tailwind CSS v4 provided utility-first styling for a clean look, while GSAP and Lenis were integrated to deliver premium, smooth animations and scrolling, elevating the user experience significantly.
🛑 Challenges We Ran Into The "Cold Start" Problem: The initial generation of embeddings for the PDF was time-consuming. We solved this by implementing persistent caching using NumPy (embeddings.npz), reducing the system's startup time after the first run to nearly zero.
Asynchronous State Management: We had to carefully manage the asynchronous nature of API calls in React, particularly ensuring the UI remained responsive and error-free while waiting for the complex RAG and LLM process to complete.
CORS Configuration: Setting up the proper Cross-Origin Resource Sharing rules in FastAPI was a crucial step to allow the React frontend (running on one port) to seamlessly communicate with the Python backend (running on another port).
🏆 Accomplishments That We're Proud Of Seamless Full-Stack RAG: We successfully married cutting-edge AI (Gemini + RAG) with a robust, modern backend (FastAPI) and a polished frontend (React) into a single, cohesive application.
High-Quality User Experience (UX): Integrating advanced libraries like GSAP and Lenis resulted in an application that feels fluid, professional, and highly interactive—a key differentiator from typical demo projects.
Demonstrable Grounding: The project effectively validates the RAG approach, consistently providing answers directly traceable to the source PDF, proving the solution's reliability.
💡 What We Learned We gained expert-level knowledge in architecting RAG pipelines, specifically the delicate balance between chunk size, embedding quality, and retrieval accuracy. Furthermore, we mastered the deployment synergy of Python (FastAPI) and JavaScript (React) for real-world application deployment.
🚀 What's Next for CodeSpire3 Future development will focus on scaling the knowledge base and improving utility:
Multi-Document Support: Expanding the system to index and query multiple documents or even entire directories.
Diverse File Formats: Adding support for other file types beyond PDF, such as DOCX, Markdown, and TXT.
User Interface Enhancements: Implementing a "source citation" feature to show the exact page number or text chunk from which the answer was retrieved.
Cloud Deployment: Preparing the application for scalable deployment on platforms like Google Cloud Run or Kubernetes.

Log in or sign up for Devpost to join the conversation.