-
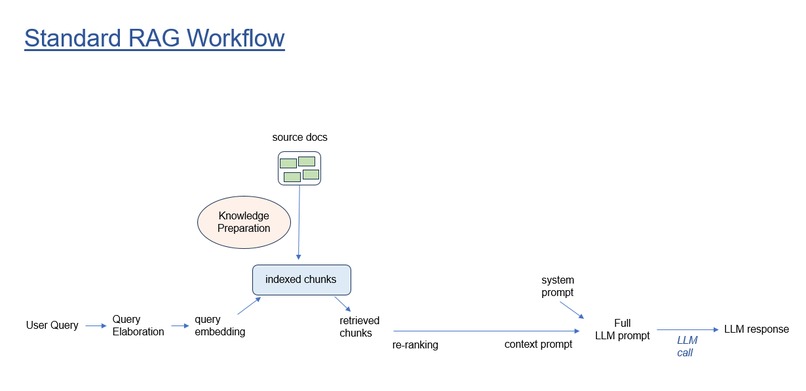
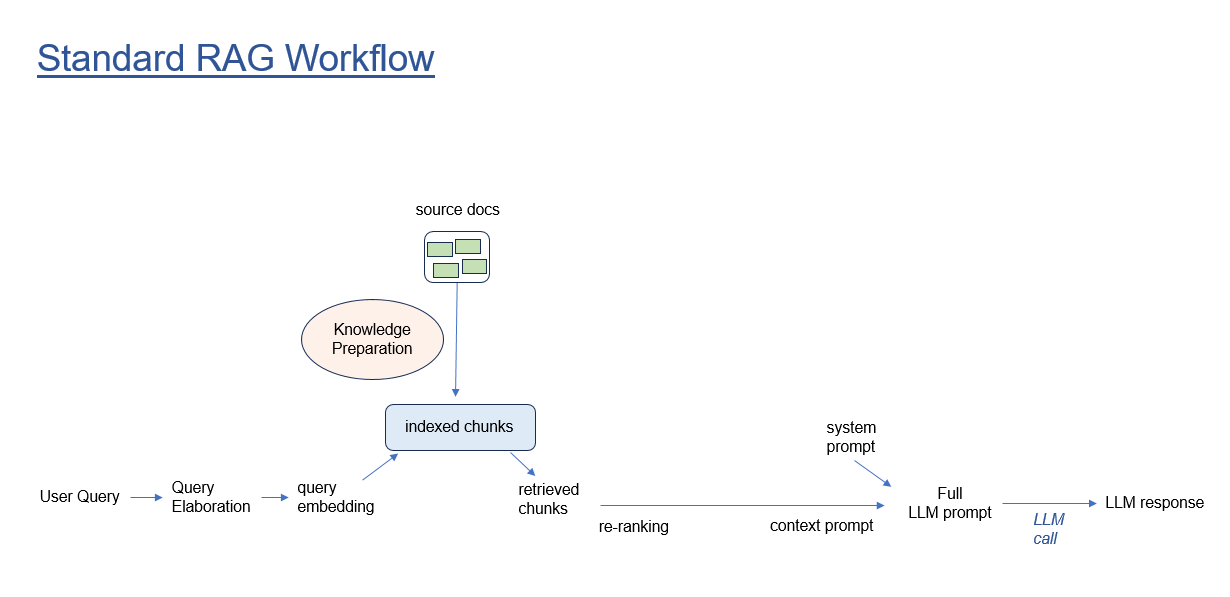
Basic RAG
-
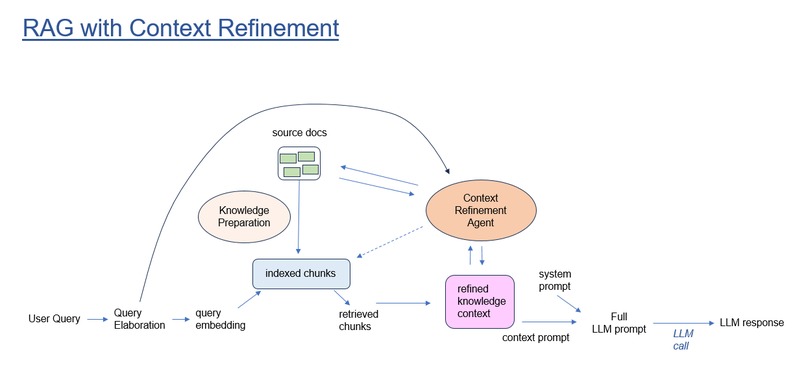
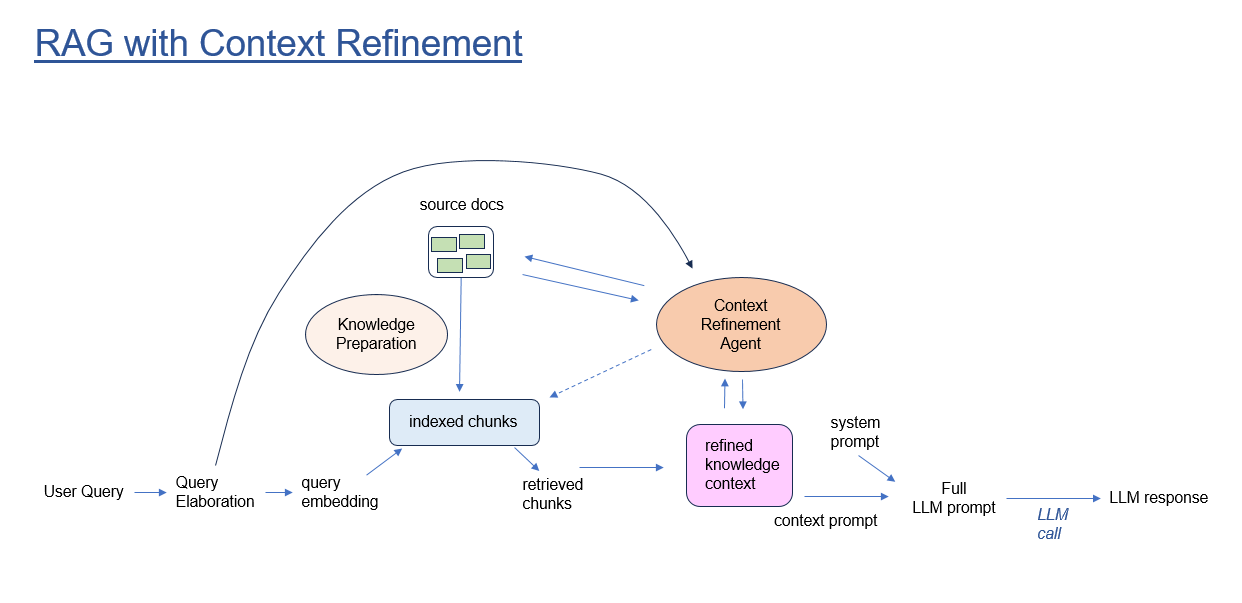
RAG with Context Refinement Agent
-
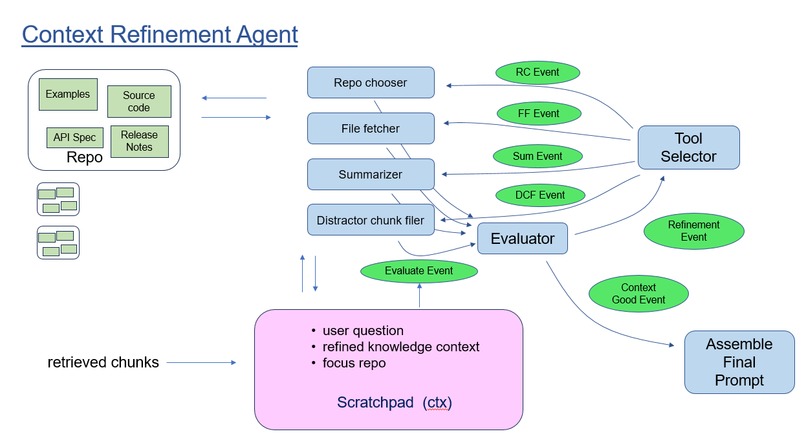
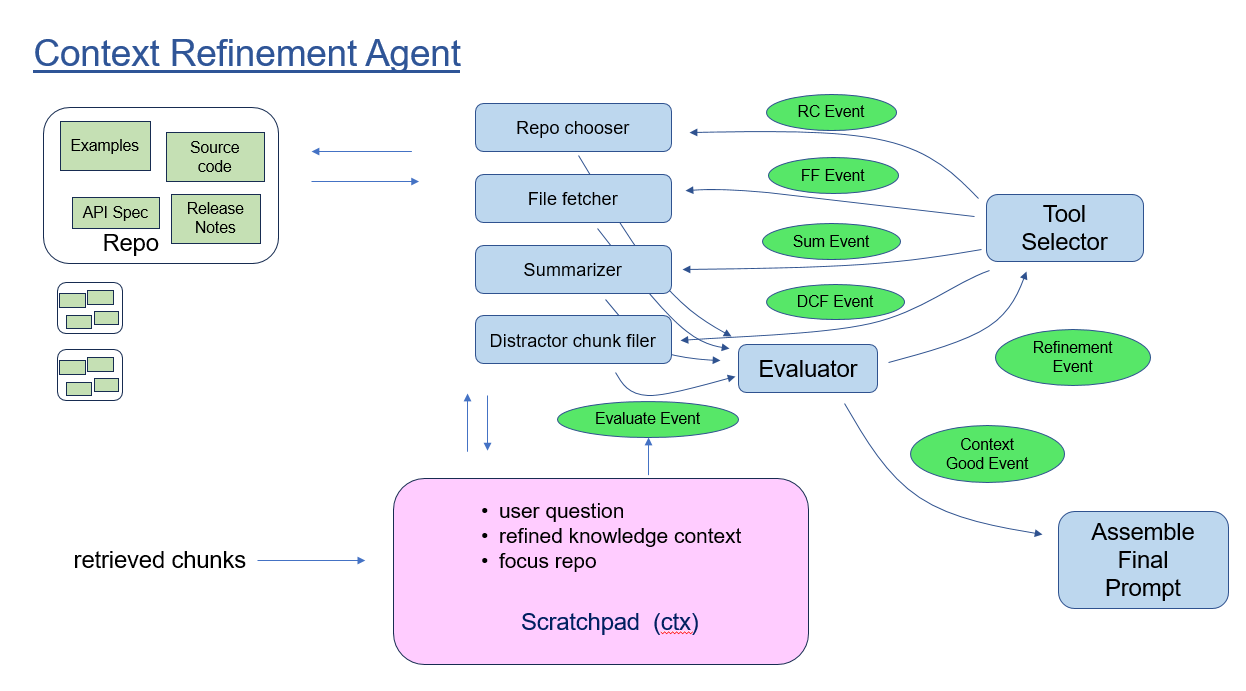
Workflow Architecture
-
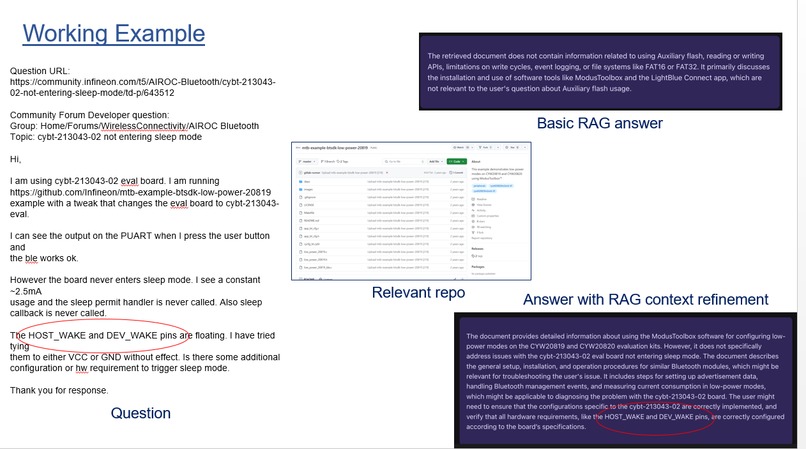
Working Example (screen shot from Reflex console)
-
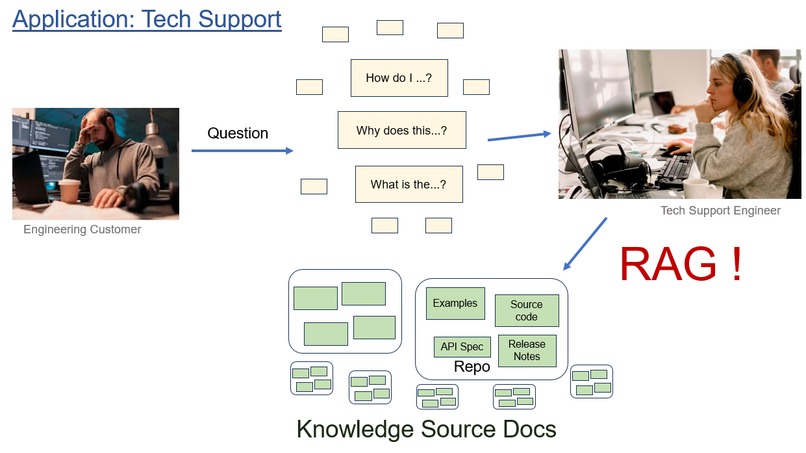
Real-world application

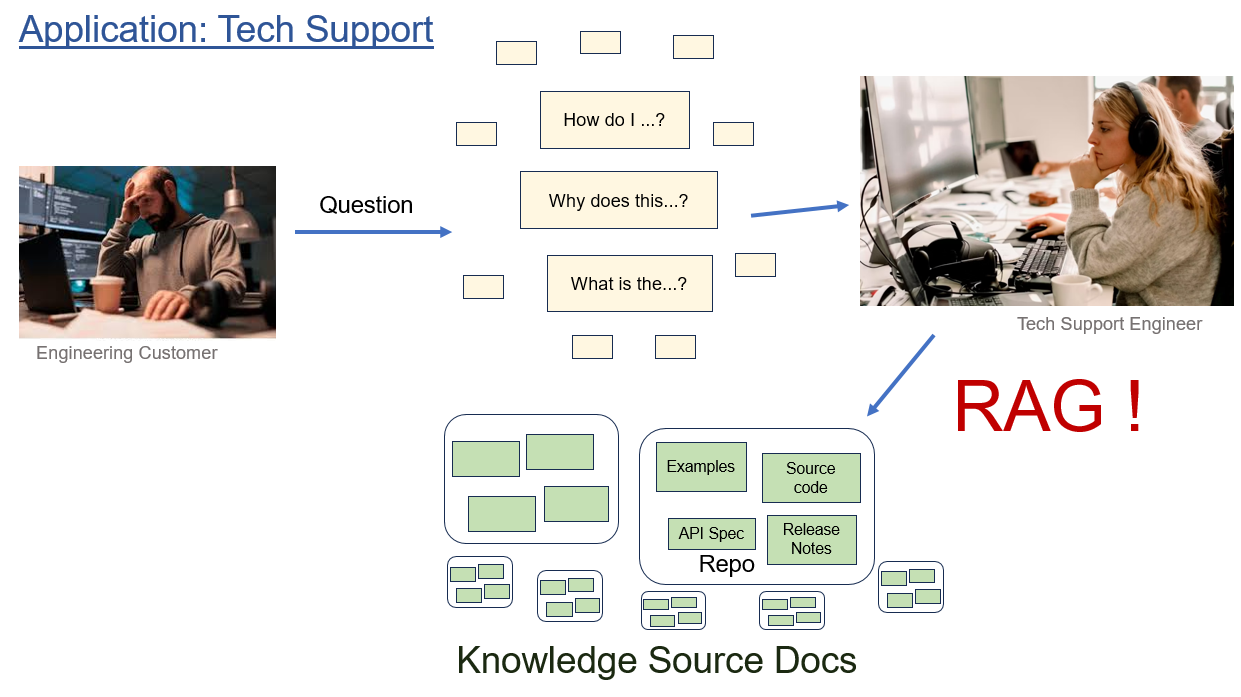
Problem Statement
Our problem scenario is a real-world application of RAG in technical support. Users have questions, support engineers respond with answers. Often the answer is based on documentation that may be more or less accessible to average users. For example, a major manufacturer of semiconductors hosts a community forum listing thousands of how-to and troubleshooting questions. Many answers refer to one of the hundreds of github repos the company maintains containing APIs, example code, firmware, and documentation. AI should help the support engineers find the right documents, and synthesize useful answers for customers' problems.
RAG can work well when context chunks are derived from well-structured segments of natural language source documents. But some knowledge sources, such as code repositories, tend to produce chunks that lack context and meaning necessary for effective indexing, and that lack significance toward a useful question+context prompt for LLM response synthesis.
One solution operates at knowledge source preparation time, to build smarter chunks. For example, include imports and class with function-level chunks identified in software files. Or include a narrative summary for each chunk. Naturally, knowledge preparation is general-purpose---it cannot be tuned to surfacing knowledge for any particular user question.
A second approach is enabled by AI agents. Our idea is to deploy an AI Agent that starts with standard retrievals, but then is empowered to return to the source documentation and apply a suite of tools designed to fetch more information, reject irrelevant chunks, and refine the knowledge context. The agent can take into account the user question, then select the appropriate repos, READMEs, and source code that addresses that question specifically.
Please refer to the figures in the Project Media section.
What We Built
We built a proof-of-concept RAG Context Refinement Agent. Sample questions were selected from the public Community Forum site of Infineon. We chose questions whose peer and expert answers included references to Infineon's public github site. Then, we built and indexed knowledge chunks from these repos using the Llamaindex and Pinecone tool chain.
For baseline testing, we ran the questions against ChatGPT and standard RAG that used top-K retrievals as context.
We built the Context Refinement Agent in the Llamaindex Workflow framework. In fact, we built the entire RAG question/response-generation pipeline in the event-driven Workflow framework.
Within the Context Refinement Agent, a Context object maintains state which is updated as the agent operates. State consists of the user question and question elaborations, plus the knowledge context to be supplied in the final LLM answer generation call.
The core loop pivots around an Evaluation step. The Evaluation step decides whether the current knowledge context is adequate to responding to the user's question, or else will benefit from refinement. If refinement is in order, then a number of refinement tools are applied in a loosely-structured order. Tools include:
- selection and filtering of useful repos versus distractors, based on chunk scores and voting
- application of summarization to files and directories
- inclusion of entire code files (subject to size), based on chunks matched to fragments.
- removal of chunks deemed irrelevant to the question
- selection of explanatory documentation associated with functions, files, and repos
- following of links found to documentation located elsewhere on the company's site, or third party sites
Obviously, we did not have time to implement all of these tools. But we have a working demonstration that AI context refinement improves the response to a sample question over baseline RAG.
Challenges
- The number of examples, tutorials, recipes, and cookbooks is overwhelming. It was sometimes difficult to sort through them all to find the nuggets that did what we needed.
- Tool chains informed by documentation and borrowed from examples did not always work.
- Requirements, dependencies, and versioning is often omitted from documentation for brevity. What imports do we need to do this?
- The number of API keys required to follow some of the recipes can become daunting. Is it worth it to install and set up an account with yet another cloud service?
Accomplishments
- Much of our work was knowledge-sharing and brainstorming about the problem space--both within the final team and with other participants who offered insights and validated issues. We came away with a much sharper understanding of how AI applies to specialized document collections such as software repositories.
- We were able to ground our hypothesis about the potential utility of context refinement in some real examples.
- In the design of the workflow architecture and functions, we navigated the prescribed-vs-autonomy dimension of agent orchestration. Obviously this is just a first pass.
What We Learned
- IDEs such as Cursor are already very effective at summarizing and explaining code. This is a distinct use case for AI applied to code bases.
- The Step/Event Workflow framework is elegant and cool. But getting synchronous and asynchronous code to work together is difficult.
What's next for RAG Context Refinement Agent?
- With a proof-of-concept and working implementation in hand (at least in prototype, outline form), this idea is a candidate for further refinement. It is clear that a great deal of development and testing with real-world question-against-repo cases will be required to solidify and improve it. Specifically, any degree of agentic autonomy is subject to unpredictable behavior so requires careful instrumentation, monitoring, and evaluation.
Built With
- langchain
- llama-index
- pinecone
- python
- reflex
- workflow-api

Log in or sign up for Devpost to join the conversation.