-
-
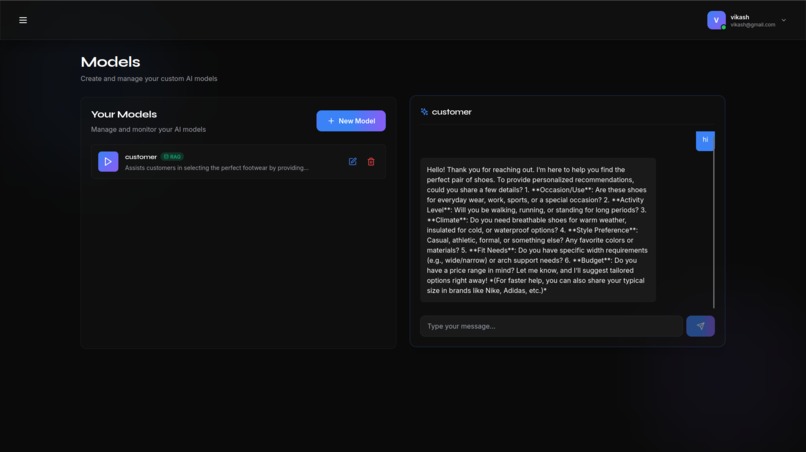
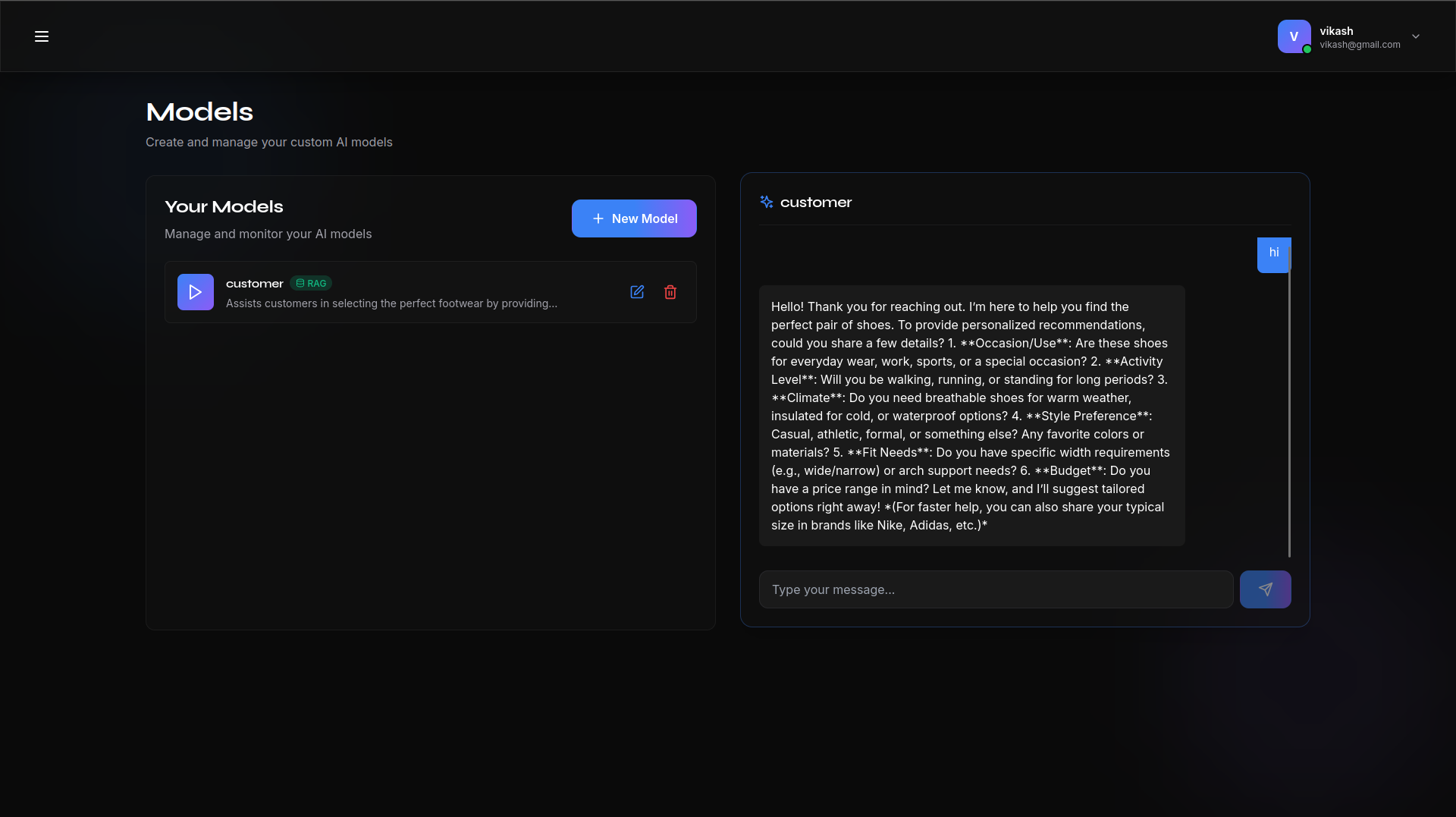
Real time streaming completion
-
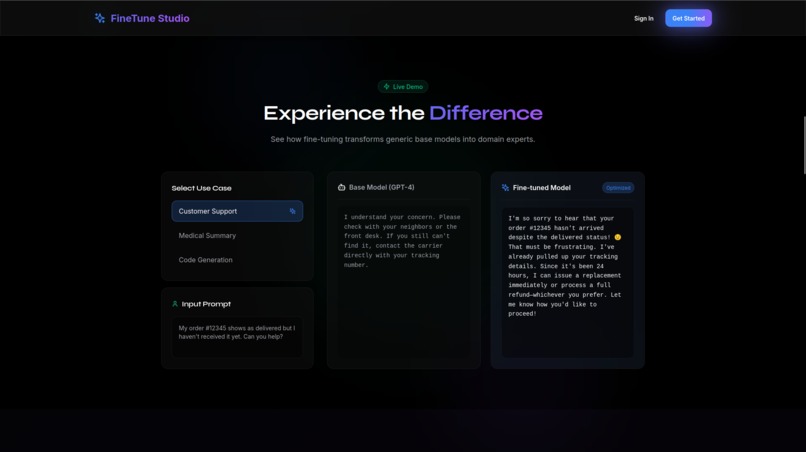
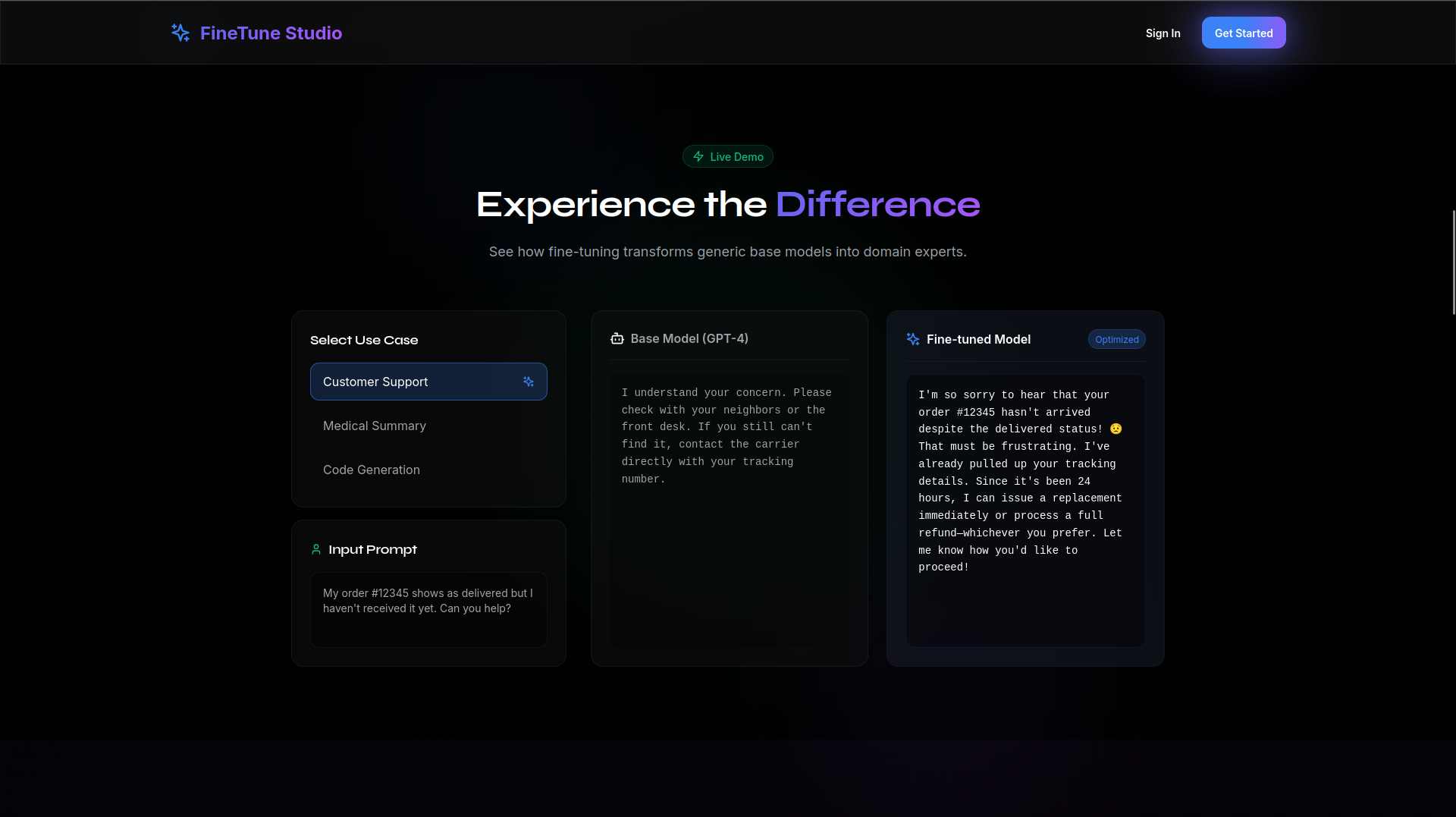
The differnece of base models and fine-tuned model
-
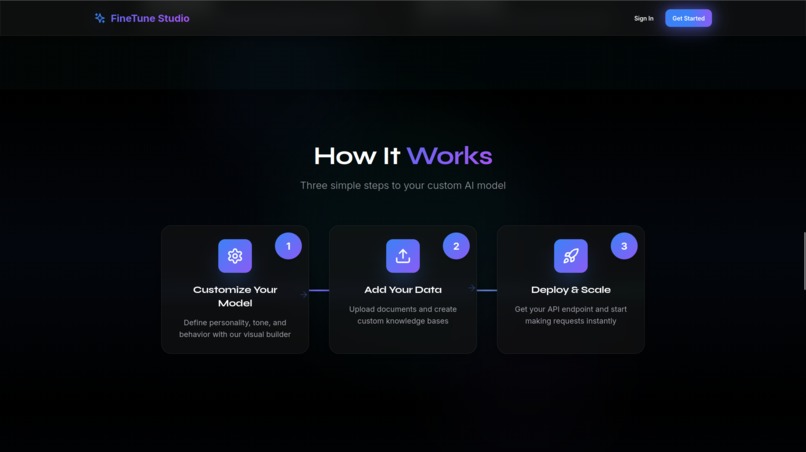
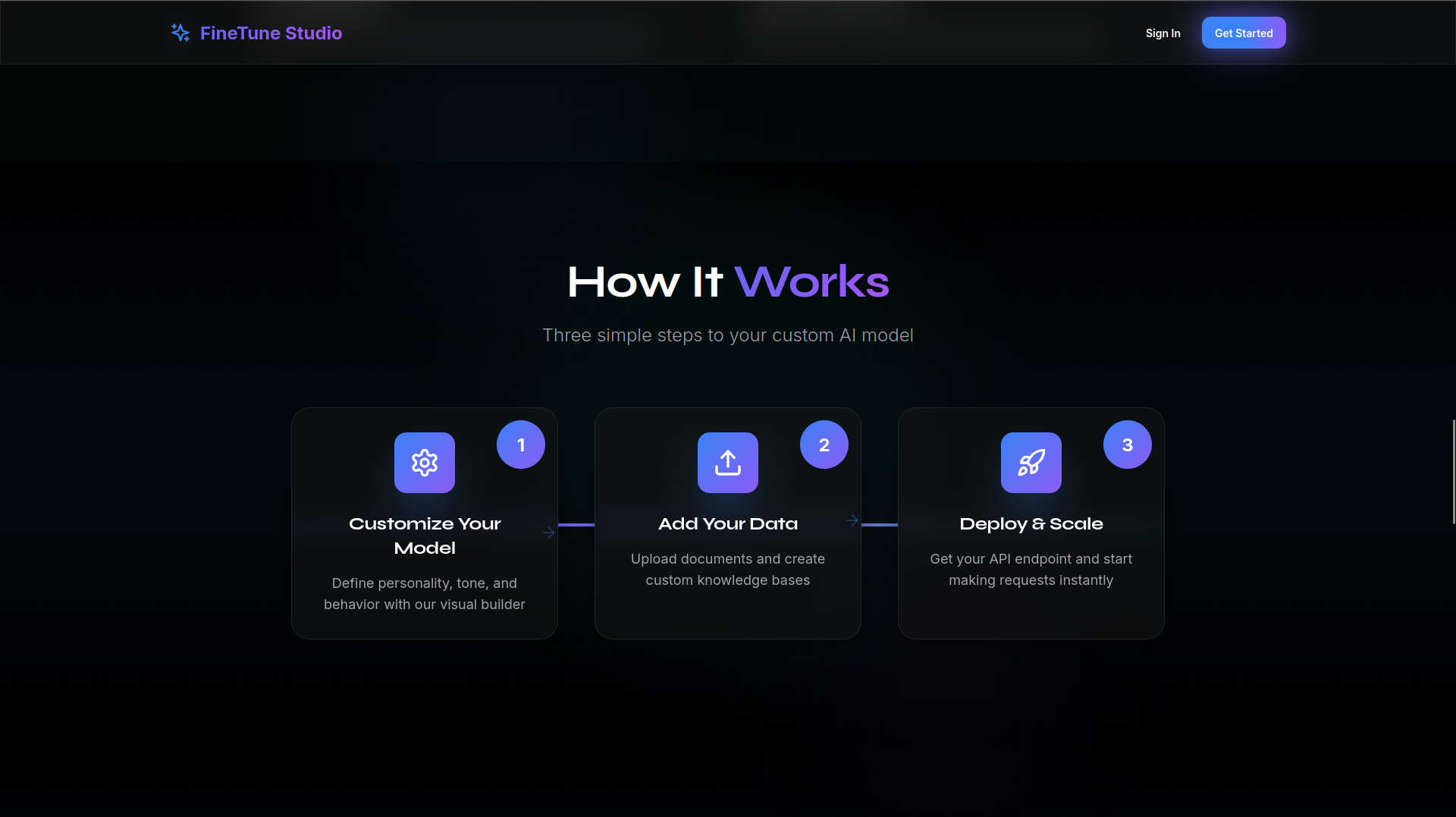
The steps that are involved
-
Home Page
Inspiration
We are living in the golden age of AI, yet for most businesses and developers, "customizing" an AI model is still a nightmare. You either have to rely on generic ChatGPT prompts that forget context, or you have to be a Machine Learning engineer wrestling with vector databases, Python scripts, and GPU infrastructure.
I wanted to bridge this gap. FineTune Studio was born from the idea that context is king. I wanted to build a platform where a user regardless of technical skill could upload their company manual, define a personality, and deploy a production-ready API endpoint in minutes, not weeks. The goal was to turn the complex architecture of Retrieval Augmented Generation (RAG) into a beautiful, drag-and-drop experience.
What it does
FineTune Studio is a full-stack SaaS platform that allows users to create, customize, and deploy personalized AI agents.
- RAG Engine: Users can upload PDFs, CSVs, or TXT files. The system automatically chunks this data, creates vector embeddings, and allows the AI to "read" and cite these documents during conversations.
- Visual Prompt Builder: A stunning interface to tweak system prompts, temperature, and personality traits without touching code.
- Production API: Every model created gets a unique API endpoint (compatible with OpenAI standards), secured by API keys, ready to be integrated into any app.
- Analytics & Monetization: A dashboard tracks token usage and costs, integrated with Cashfree for subscription handling.
How we built it
The project follows a modern microservices architecture to ensure scalability.
The Brain (Backend): We chose FastAPI (Python) for its speed and native support for AI libraries. We used LangChain to orchestrate the logic between the LLM and our vector store. For the "Memory" of the AI, we utilized ChromaDB to store vector embeddings of uploaded documents. We implemented Redis to handle caching and rate limiting to protect our API endpoints.
The Beauty (Frontend): The frontend is built with Next.js 14 and TypeScript. We didn't want this to look like a standard dashboard, so we used Framer Motion extensively to create fluid page transitions and micro-interactions. The UI is styled with Tailwind CSS and shadcn/ui for a clean, futuristic aesthetic.
The Infrastructure: The entire stack is containerized using Docker, ensuring that the complex interplay between the vector database, Redis cache, and API server works reliably in any environment.
Challenges we ran into
The biggest technical hurdle was the RAG Pipeline. Implementing a system that can accept a messy PDF, clean the text, chunk it intelligently (so the context isn't lost), and retrieve the exact right paragraph during a chat was difficult. We spent a lot of time tweaking the chunk sizes and overlap to ensure the AI didn't hallucinate answers.
Another challenge was User Isolation. Since this is a SaaS, User A's uploaded financial documents absolutely cannot be accessible by User B's model. We had to implement a robust Row-Level Security architecture within our vector store and MongoDB to ensure strict data privacy.
Accomplishments that we're proud of
- The UI/UX: It honestly feels like a Silicon Valley product. The animations make the complex task of "model tuning" feel fun.
- Seamless RAG: Dragging and dropping a 50-page PDF and having the AI answer a specific question from page 42 in under 2 seconds feels like magic.
- Security: We managed to implement full JWT authentication, API key management, and rate limiting, making this not just a demo, but a secure, deployable product.
What we learned
Building FineTune Studio taught us that AI is 10% model and 90% data pipeline. The quality of the response depends almost entirely on how you retrieve and feed context to the model. We also learned the intricacies of Dockerizing a multi-container application that involves heavy Python libraries and vector stores.
What's next for FineTune Studio
- Agentic Capabilities: Allowing the models to not just "chat" but browse the web to fetch live data.
- Multi-Modal Support: Adding image analysis capabilities to the custom models.
- Fine-Tuning: Currently we do RAG; the next step is offering one-click LoRA fine-tuning for modifying the actual weights of the model.
Thanks to Kiro for making this possible!
This project consist of 13,059,722 lines of code. That is around 13.6 Million lines of codes.
Built With
- chromadb
- docker
- fastapi
- langchain
- mongodb
- nextjs
- python
- redis
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.