Title
Improving Dog Breed Classification with Image Segmentation
Who
Allison Hsieh - ahsieh10
Pranav Mahableshwarkar - pmahable
Joseph Dodson - jdodson4
Introduction
We arrived at this topic because image classification was always quite a finicky process, since some pixels (pixels on the object) play more significance than others (pixels in the background). Therefore, we were thinking about whether we could somehow use image segmentation and filter out the background pixels to improve classification. This was also suggested to us by Madhav, our mentor TA, after we had to restart the project very late. This is a classification problem.
Related Work
Yes, there is some previous work on this topic, although more refined than our manual method. This article states that the interplay between object classification and image segmentation is not quite clear, so results are not very clear as of so far. Also, the reason why this methodology is unpopular (despite it being quite an active field of research) is because it is difficult to train an image segmentation model that properly classifies all boundaries of objects. This article also talks about a methodology where several different segmentation algorithms are assessed and the more stable one is used.
Public implementations:
https://github.com/matterport/Mask_RCNN
Data
Segmentation training: Tensorflow oxford_iiit_pet dataset (37 categories, 200 images per category)
Images were resized to 256x256.
Classifier training: Tensorflow stanford_dogs dataset (120 categories, 12000 training images, 8580 testing images of various sizes). Significant preprocessing is needed for this one, since all the images are different sizes and must be resized to the same size, and its backgrounds are set to zeros as well.
Methodology
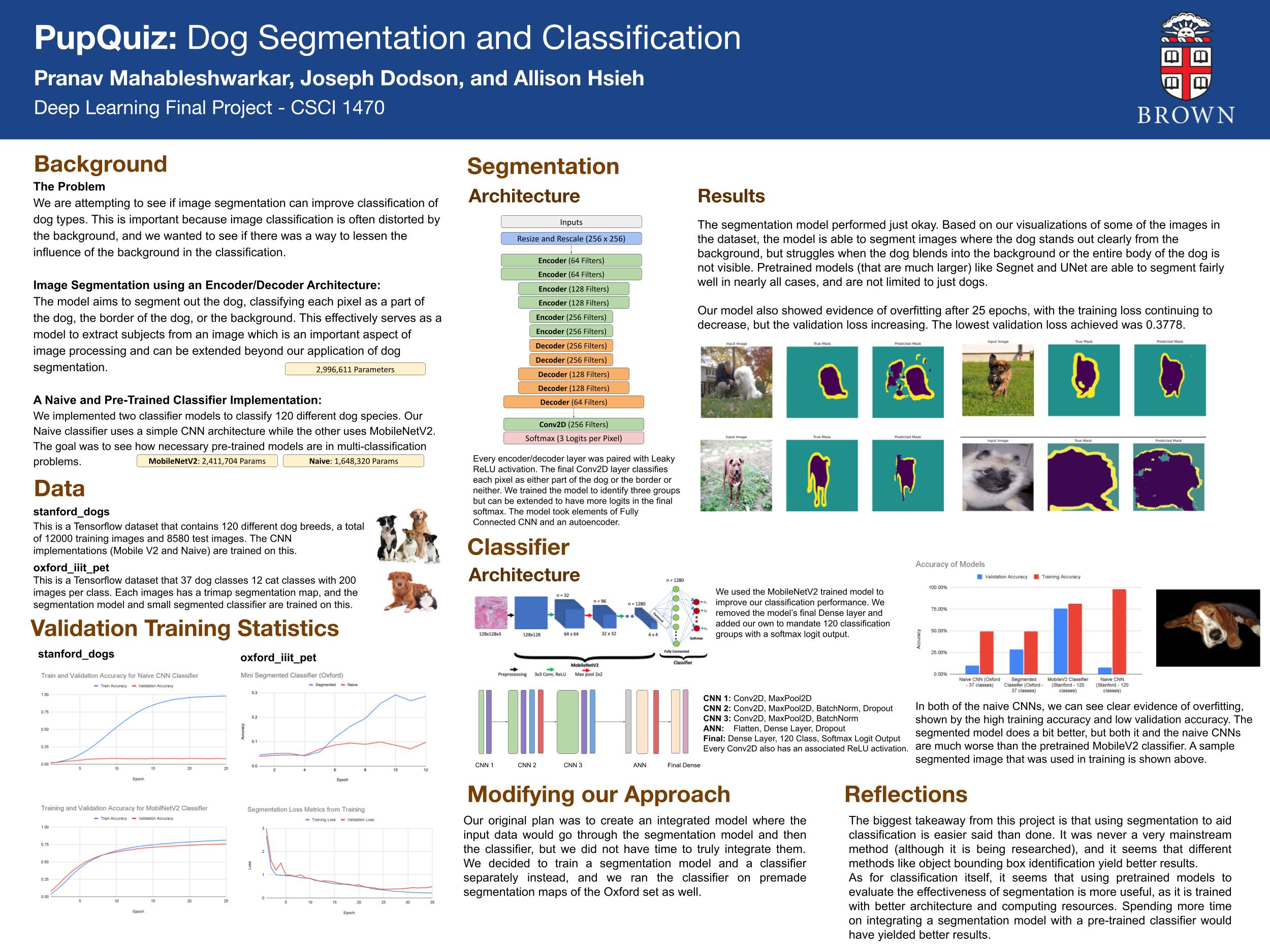
For the naive classifier, we are using a 2D custom sequential convolution model structured like this:
- Masking layer that masks all zeros (this is the background during the validation set)
- Convolution Layers with 16, 32, 64, 128 output channels with leaky relu activation and batch normalization in between + flatten + dense layers at the end.
- This design was mainly the result of trial and error; at first, we fed the validation set with the zeroed out background straight into the CNN, which created quite a lot of instability in the validation accuracy. Later, we decided to feed in the training set with removed backgrounds as well. As for the convolutional model structure, it was mainly taken from the lecture (convolution with activation + batch normalization), and this was the most convolution layers that we could stack on before the model started yielding results that were not ideal (very low accuracy).
Our segmenter used an encoder-decoder approach. Our model has the following structure:
- 6 Conv2D encoder layers, which learn 64 (x2), 128 (x2), and 256 (x2) filters, reducing the image size from 256x256 to 32x32. Each layer uses a leaky ReLU activation function with SAME padding.
- 5 Conv2DTranspose decoder layers, which deconvolve the output of the encoder into a 256x256 image. - Each layer uses a leaky ReLU activation function with SAME padding. The decoder filters mirror the encoder filters.
- 1 Conv2DTranpose layer with 256 filters.
- 1 final Conv2D layer that learns 3 filters and a softmax activation. This layer assigns each pixel a probability for each class (background, border, or part of the cat/dog).
##Results - The results on the oxford dataset itself with the given trimaps was quite good. The naive CNN implementation yielded a validation accuracy of 15-18 percent, while the version with the background removed yielded a 28.62 percent accuracy. Reducing the background seems to have created significant improvement.
- The segmentation model performed just okay. Based on our visualizations of some of the images in the dataset, the model is able to segment images where the dog stands out clearly from the background, but struggles when the dog blends into the background or the entire body of the dog is not visible. This makes sense, as those images are harder to classify, but also shows the limitations of using a custom model. Pretrained models (that are much larger) like Segnet and UNet are able to segment fairly well in nearly all cases, and are not limited to just dogs. Our model also showed evidence of overfitting after 25 epochs, with the training loss continuing to decrease, but the validation loss increasing.
- The naive CNN unfortunately did not perform as well on the stanford_dogs dataset. It was very overfitted, where the training accuracy was in the 90s and the validation accuracy was about 9 percent.
- The pretrained MobileV2 model performed quite well on the stanford_dogs dataset, yielding a 75% validation accuracy. This is expected, as the model was trained via better computing resources.
Challenges
This was actually not our first project idea. Our first project idea was also related to image segmentation, but we were planning to reimplement a paper on brain tumor segmentation. That did not work out because the paper was a bit out of scope in terms of complexity and the dataset ended up not being available when we tried starting on the model.
The classification model created in this project does not have a very high accuracy (probably because the images are all different sizes and were resized accordingly), so the results are not very satisfying.
We were planning to make a bounding box preprocessor where the images were cropped down to their respective bounding boxes. However, the oxford dataset did not provide this for their entire dataset (although it said so in their documentation), so it was impossible to have a proper validation set.
We had some difficulty integrating the segmentation model and the classifier together. Semantic segmentation pretty much discards the original image, which does not necessarily make classification better.
Our rudimentary segmented classification model was unable to handle the size of the stanford_dogs dataset, and zsh would kill the process because it was taking too long. Therefore, we switched to a pretrained image classification model instead for our final result, but we decided to keep the Oxford-trained model to demonstrate a smaller case.
Reflection
Our project turned out to be okay: not as good as expected, but it still did achieve the desired results. Our base goal was just to have a working segmentation and target model trained to pre-made segmentations, our target goal was to integrate the two together, and our reach goal was to make something that could significantly improve classification. We would say that our base goal is reached, definitely not our target or reach goal because our segmentation model and classification model are still not very refined, and we have not been able to have time to integrate the two models together.
Our approaches actually changed massively over time. As stated above, we were coding a segmentation model and classification model separately. We had tried utilizing the bounding box object in the stanford_dogs dataset, but we realized that we would probably have to code a separate object detection model for this. Therefore, we decided to just stick to making the segmentation model and classification model work. If we were to do the project again, we probably should have looked for a pre-trained ResNet classification model and just worked on segmentation + object identification. Our accuracy was not very good overall because our classification model was manually trained with a small data set. If we had more time, we could definitely look into training an object identification model, since it turns out that cropping the image to the background yields the greatest accuracy. Also, if we had more time, we could probably truly integrate the segmentation and classification model together.
The biggest takeaway from this project is that using segmentation to aid classification is easier said than done. It was never a very mainstream method (although it is being researched), and it seems that different methods like object bounding box identification yield better results.
Built With
- cnns
- encoder-decoder
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.