-
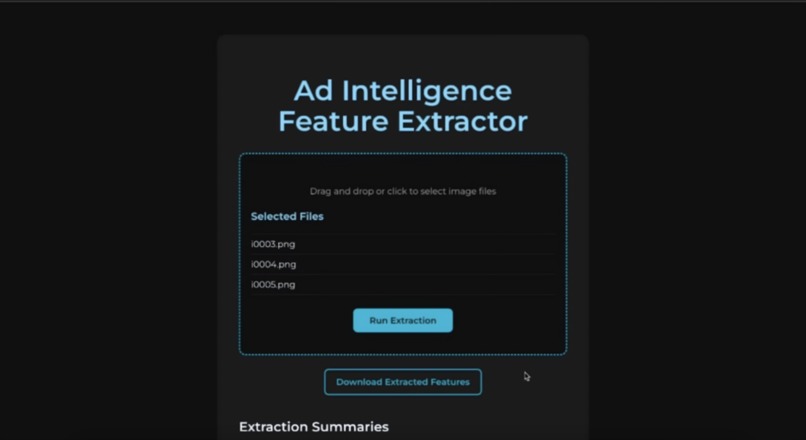
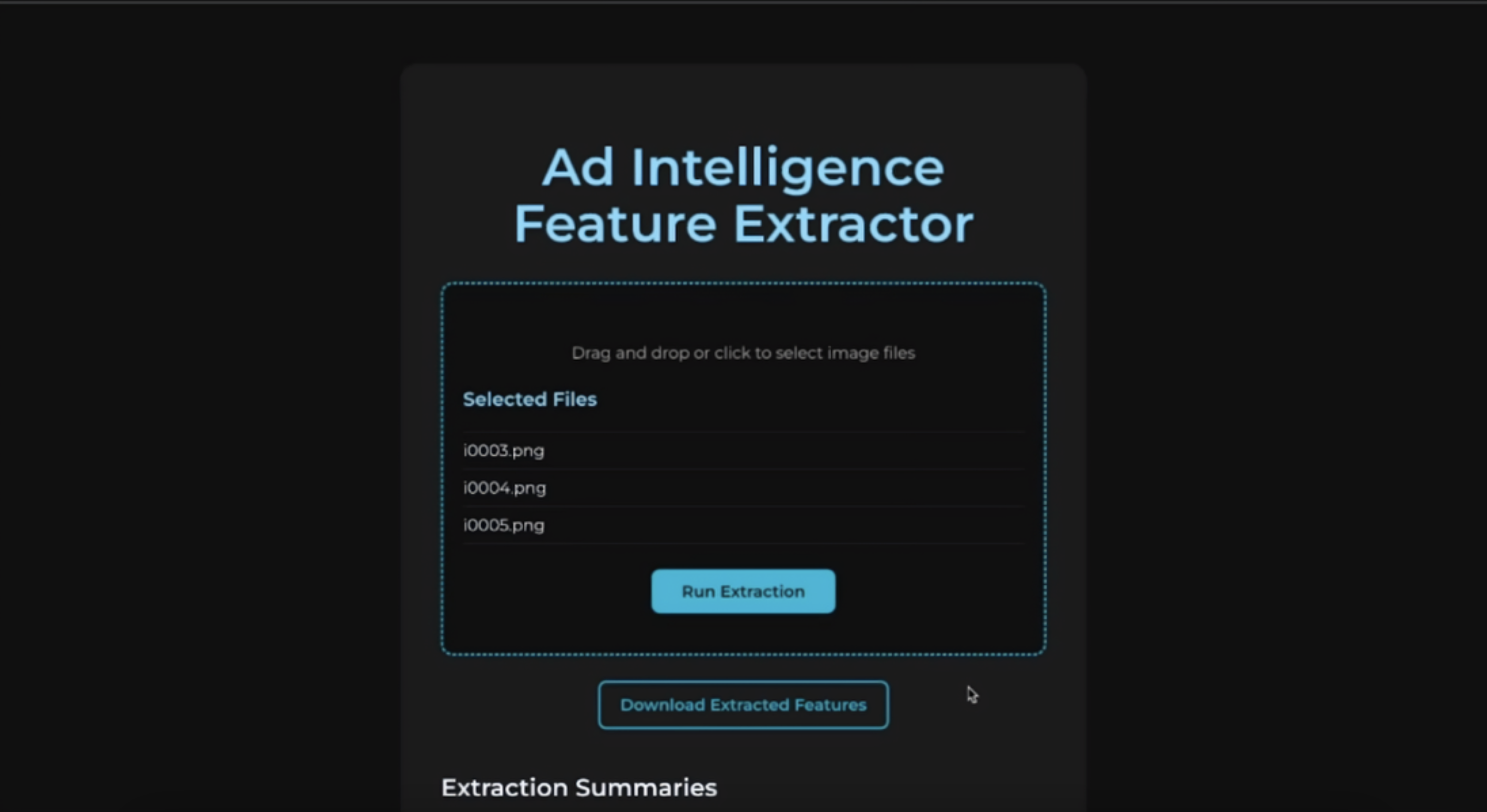
home page.
-

part of analysis---predictive gaze modelling
-
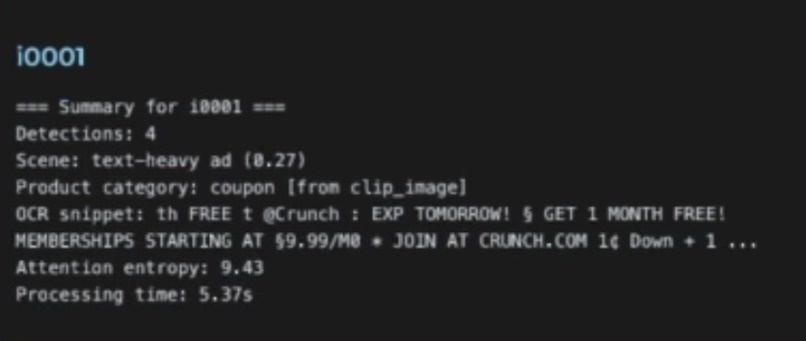
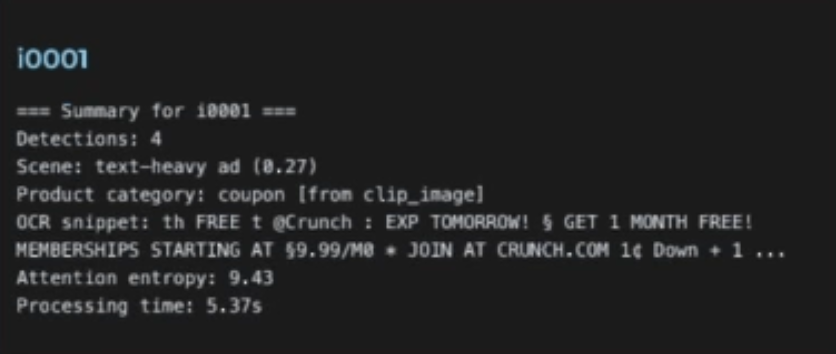
sample image summary

Inspiration
Creative teams guess which ads work; we'd much prefer fast, explainable signals across video, image, and audio to pick winners before spend.
What it does
Extracts features from images, videos, and audio.
Merges video+audio per video; outputs JSON with interpret-able metrics (shots, motion, text/CTA timing, product reveal, end-card, thumbnails, faces, color, clutter, platform fit, loop-readiness, audio speech/music).
How we built it
We created a modular pipeline:
image/: visual semantics, attention maps, OCR, optional LLM captioning. videos/: per-metric modules with parallel per-video execution and dependency waves. Sub-tasks are parallelize-able audio/: separation, ASR, speech/music/text analysis.
Orchestrator that runs image, and in parallel runs video and audio, then merges by filename stem.
Challenges we ran into
- Hitting sub‑second per-metric latency without GPUs. Aggregation can almost entirely be parallelized so the result will only take the longest of each metric, summed if dependencies exist.
- Avoiding redundant computation across steps (saliency/gray/MSER reuse).
Accomplishments that we're proud of
End‑to‑end, explainable feature set with per‑metric breakdowns, parallel per‑video tasking and A/V concurrency, tweakable speed/quality knobs and weights, simple JSON outputs ready for ranking/ML.
What we learned
- Lightweight CV proxies (saliency/MSER/flow) are strong baselines.
- Caching + downsampling matter more than we expected.
- Clear dependency waves simplify parallelism and debugging.
What's next for AdJacent
We still need to add lightweight logo/face detectors and text OCR keywords for CTAs. For full functionality, we should train a learned ranker on historical performance. We also need to add web UI for previews, breakdowns, and A/B comparisons.
Integrating this with AppLovin would be the ultimate step!


Log in or sign up for Devpost to join the conversation.