Rabak
Project Description
People repeat certain words without even realising it and once you notice it, you can’t unhear it, especially when it gets annoying.
So, we built Rabak, a speech-analysis tool that helps Singaporeans become aware of the Singlish words they repeat unconsciously.
By recording conversations, Rabak analyses the audio and delivers a humorous breakdown of Singlish usage by each person, revealing those subtle (and sometimes annoying) speech habits we never knew we had.
Inspiration
“Eh, can you stop saying walao? It’s very unattractive and it’s such a turn-off.”
That sentence alone inspired Rabak.
We realised something unsettling: people repeat certain words without even realising it, and sometimes, that repetition can be very annoying.
In Singapore, the clearest example of this is Singlish, the lahs, lors, walaos, and sias that slip into our speech automatically.
What It Does
Rabak records real conversations and automatically identifies the different speakers present.
Once the recording ends, it analyses the audio to produce:
- an overall summary of Singlish usage across the entire conversation
- a breakdown highlighting the most frequently used words
Rabak also generates individual summaries for each speaker, showing:
- their personal “favourite words”
- usage frequency
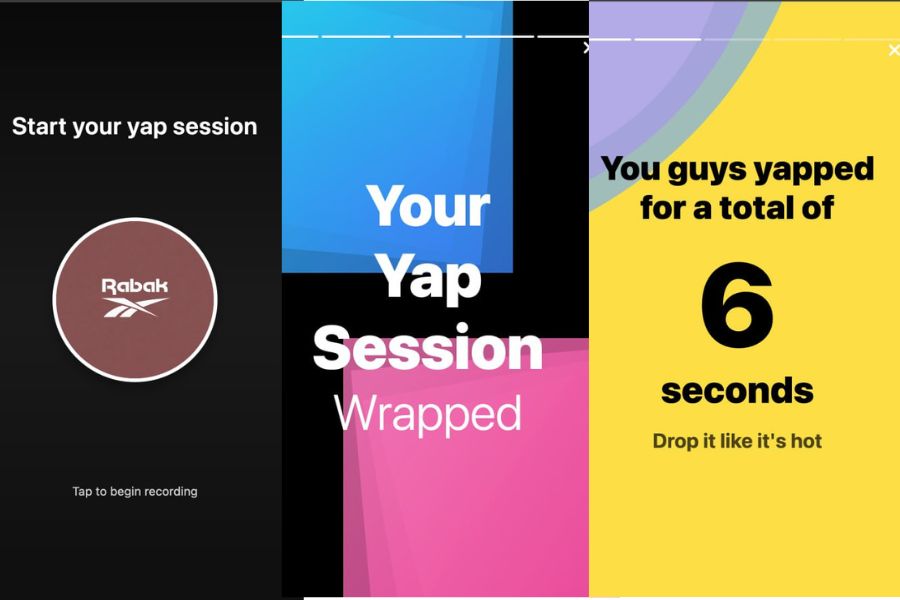
These insights are presented in a familiar Spotify Wrapped–style format 🎧, making the results intuitive, visual, and fun to explore.
Speakers can then name and identify their own summaries, which can be easily shared.
How We Built It
Rabak is powered by an end-to-end speech analysis pipeline designed to work with real-world, informal conversations.
Our system consists of:
- Speaker diarization to separate and identify different voices within a single conversation
- Automatic speech recognition (ASR) to transcribe spoken audio into text
- Custom Singlish word detection, layered on top of standard ASR outputs
- Post-processing analytics to aggregate results and generate speaker-level and conversation-level summaries
Challenges We Ran Into
One of our biggest challenges was language coverage.
- Existing speech-to-text models struggled to accurately transcribe Singlish particles and colloquial expressions
- Many Singlish words were either mistranscribed as standard English words or ignored entirely
- Fine-tuning and post-processing involved significant trial and error, especially when working with limited audio samples
- We had to manually correct and map mistranscribed outputs back to their intended Singlish words using a custom dictionary
Accomplishments We’re Proud Of
- Achieved high transcription and detection accuracy for commonly used Singlish words
- Built a custom Singlish dictionary supported by sample audio recordings
- Successfully mapped standard ASR outputs to their corresponding Singlish forms through post-processing
- Delivered a working, end-to-end system that performs reliably on real conversational audio
What We Learned
- How to integrate multiple machine learning models into a single, functional API pipeline
- How to debug and work around dependency conflicts and environment incompatibilities
- How to operate under tight resource and time constraints
- Due to hardware limitations, we ran our ML models externally on Google Colab and exposed them via APIs, which were then consumed by our browser-based application
What’s Next for Rabak
- Extend detection to other forms of slang, dialects, and conversational lingo
- Track an individual’s most frequently used expressions over time
- Provide broader insights into personal speech habits, not limited to any single language or region
Built With
- expo.io
- fastapi
- firebase
- meralion-2-10b-asr
- postgresql
- pyannote
- python
- react-native
- redis
- supabase

Log in or sign up for Devpost to join the conversation.