-
beta version of the radiology report simlarity
Inspiration
We generate >200k radiology reports yearly at our institution but have no efficient way of harnessing the data because the reports are in free-text format. These reports are linked to patient images and contain valuable information in the form of radiologist's visual description and overall impression. If the report contents (and hence the linked images) can be categorized in hierarchical fashion using standardized medical lexicon, similar to that of ImageNet, and then pooled into a giant database, it can become the next ImageNet of radiology that can revolutionize the way we teach physicians (short term goal), conduct clinical research (mid term goal), and train artificial intelligence / computer vision algorithms (long term goal). We name this database project, R-net.
What it does
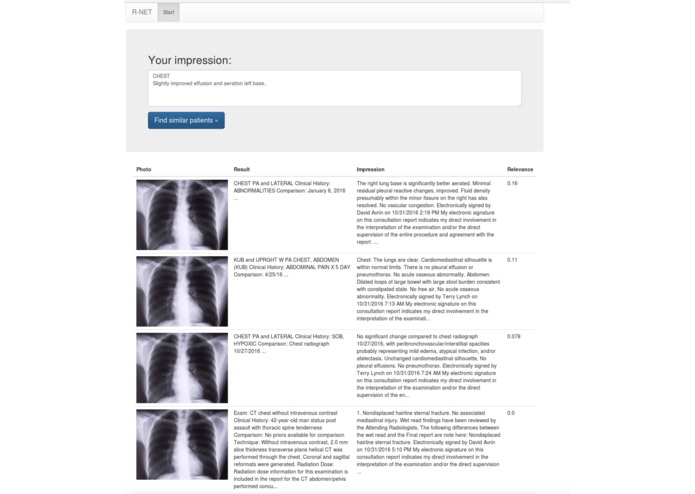
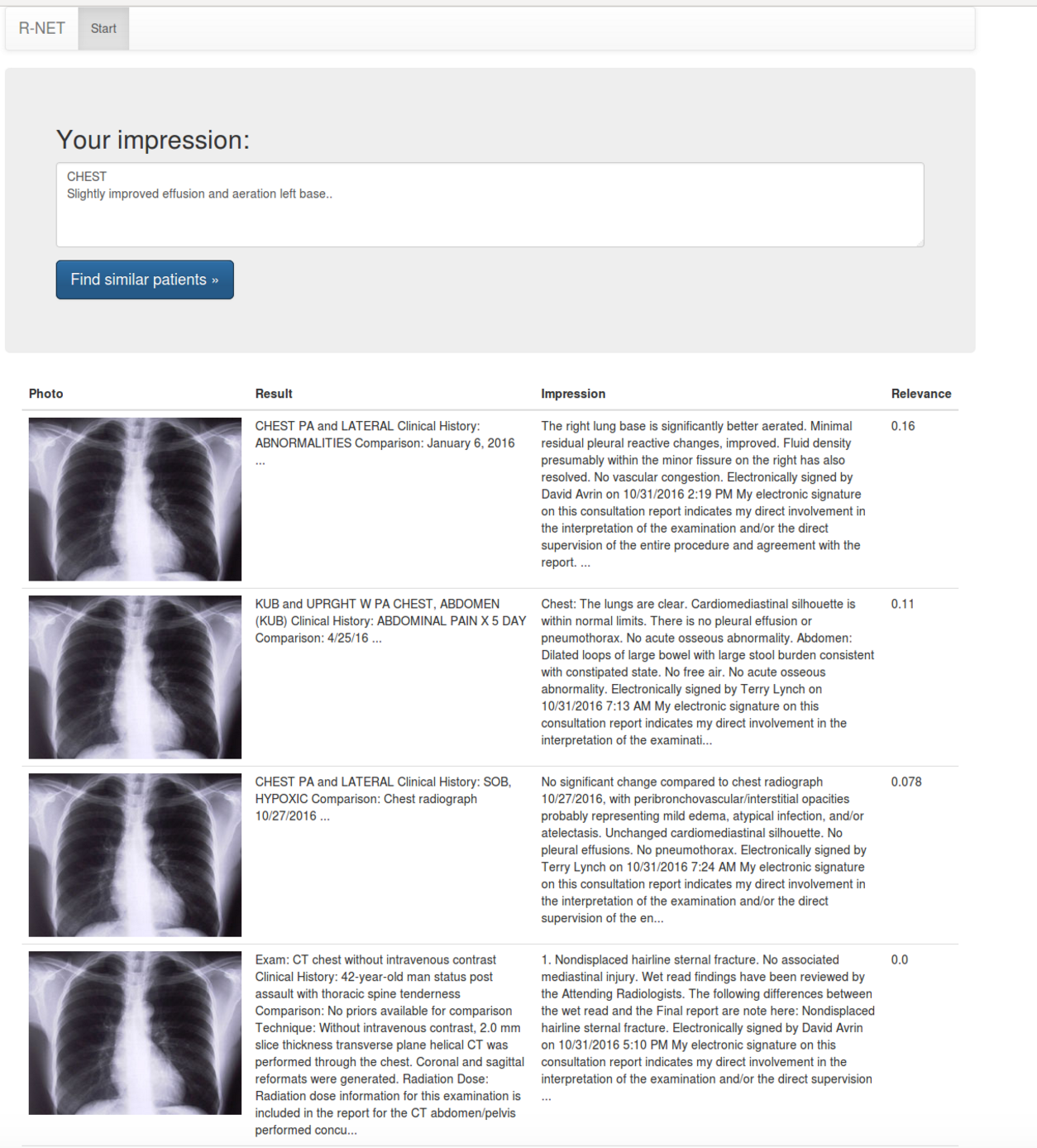
This Hackathon project represents our very first step towards creating hierarchical categorization of radiology reports and images. We created an algorithm that can search for similar contents in ~200k anonymized radiology reports, which in turn will be used to assign specific hierarchical labels in the next phase. Our interface allows the radiologist to input an overall impression, then the back-end algorithm searches for similar reports in the database, and then receive reports + images with sufficient similarity.
How we built it
In order to determine similar radiology reports, we implemented both a backend algorithm and a frontend user application. For the backend software, we accept any user input and return the most similar existing radiology reports. We determined similarity via a “term frequency – inverse document frequency” approach, which means that radiology reports with a large number of common words and phrases are considered similar, while also assigning greater weight to uncommon words and phrases. For the front-end system, we created a simple user interface where a radiologist can enter a particular description and receive the similar reports.
Challenges we ran into
The biggest challenge was implementing a similarity algorithm that is both comprehensive in this particular medical radiology context but also feasible to build within the weekend. In fact, the first iteration of our model produced results that did not appear similar at all. As a result, we focused on experimenting with several different approaches to determine similarity before settling on the term frequency – inverse document frequency approach.
Accomplishments that we're proud of
- Implemented the first iteration of the similarity algorithm and initial user interface
- Utilized a very large anonymized database of radiology reports with very wide areas of applicability.
- Created step-by-step, feasible, and practical goals for short-term, mid-term, and long-term that will immediately help radiologists, researchers, and entrepreneurs.
What we learned
Close communication among physicians, engineers, entrepreneurs, and designers can bring great innovation.
What's next for R-NET
In order for R-NET to resemble the ImageNet and have similar impacts, it needs to be easily scalable and must be compatible with other hospital records. Therefore, standardized radiological lexicon system must be used to create the hierarchical labels. Then, NLP or search algorithms should be used to divide reports into clusters and automatically assign labels with reasonable accuracy. Human readers will then manually confirm the labels to ensure accuracy (this portion may be outsourced). Other institutions around the U.S. will be contacted for building a similar database using the exact same lexicon system and hierarchical labels so that the databases can one day be pooled across multiple institutions.
Built With
- big-data
- django
- machine-learning
- python








Log in or sign up for Devpost to join the conversation.