-
-
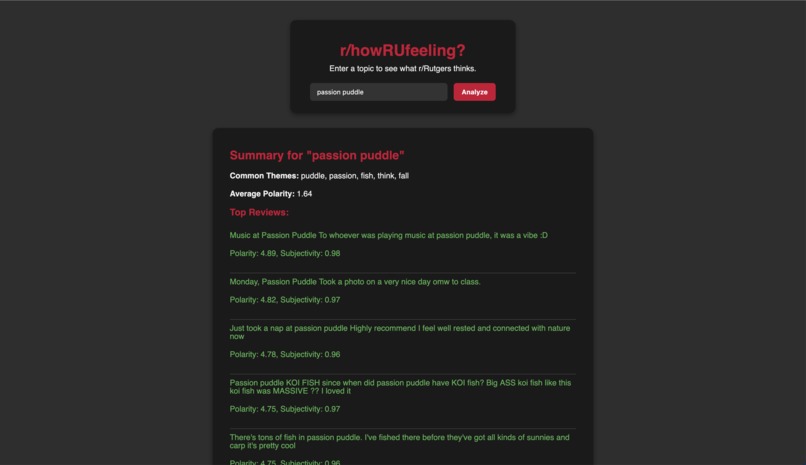
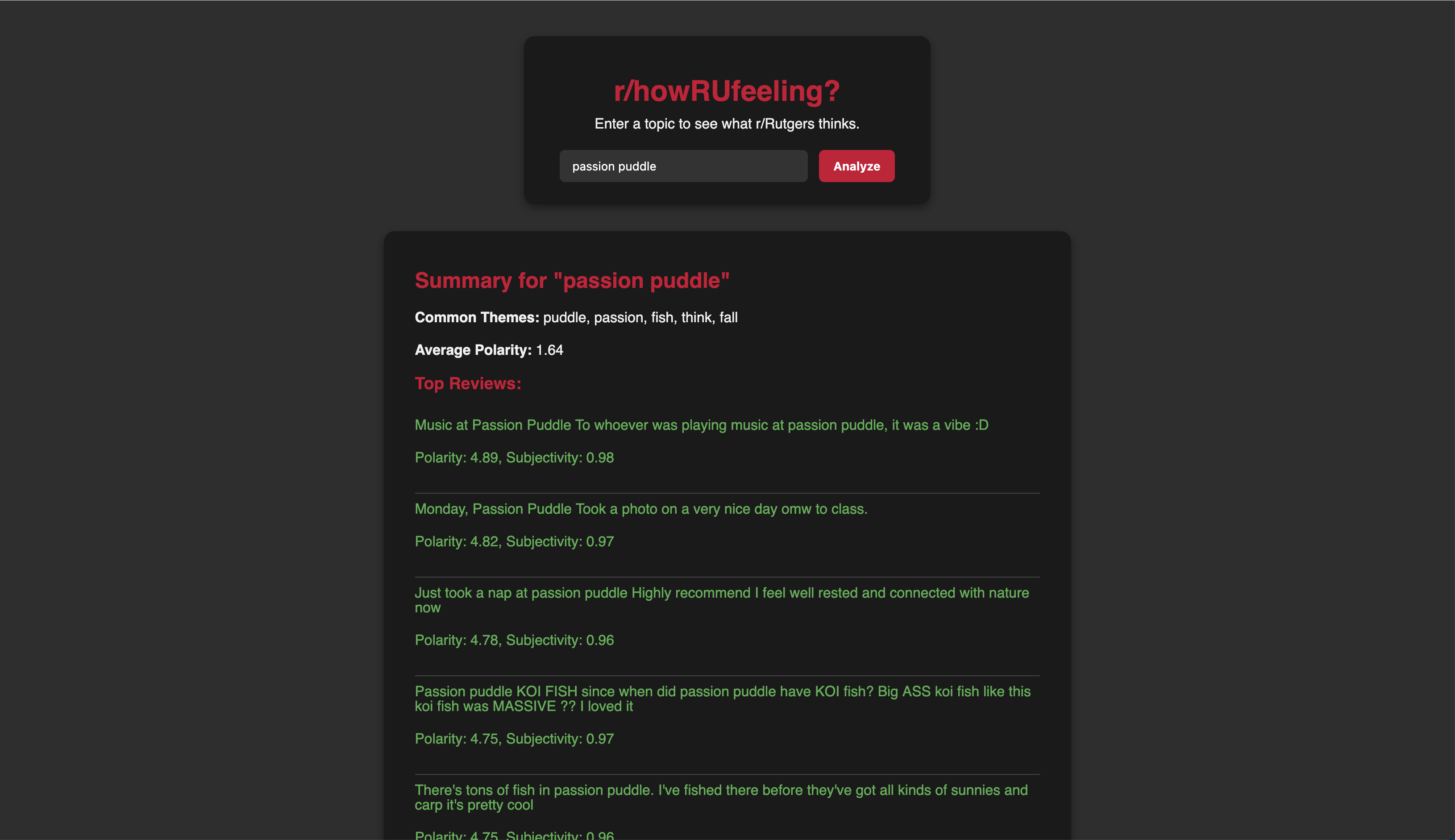
What people at Rutgers think about Passion Puddle!
Inspiration
We were inspired by platforms like RateMyProfessor.com and product review sites that try to capture public opinions — but often fall short.
For instance, RateMyProfessor restricts reviews with strict word limits, which prevents students from fully expressing their experiences and emotions.
We wanted to explore a more expressive, open space: Reddit.
Here, people share authentic, unfiltered opinions — not just short blurbs.
That inspired us to build a tool that can analyze these conversations and summarize what the community truly feels.
What it does
The user inputs any topic, person, product, or event, and the app scrapes Reddit discussions related to that query.
Using sentiment analysis, it evaluates each post’s polarity (how positive or negative it is) and subjectivity (how opinionated it is).
The app then:
- Filters out irrelevant or question-like posts
- Calculates an average sentiment score
- Highlights the most common discussion themes
- Displays color-coded examples of the top posts
Originally designed for professors at Rutgers, it has since evolved into a general-purpose Reddit sentiment analyzer that can interpret community mood across a wide range of topics.
How we built it
We built the backend with Python and Flask, connected to the Reddit API using PRAW to fetch posts and comments dynamically.
The sentiment analysis is performed using a transformer-based model.
The frontend is a lightweight HTML/CSS/JavaScript interface that interacts with Flask’s /analyze endpoint.
We also implemented a caching system so that repeat searches for the same topic load instantly without re-scraping or reprocessing data.
Challenges we ran into
- Ensuring that posts are actually relevant to the intended topic (especially for people with common names).
- Avoiding question-like posts (“Should I take this class?”) that aren’t true reviews.
- Improving the accuracy of polarity scoring, since some sarcastic or mixed posts can confuse simpler models.
- Maintaining performance while using more advanced transformer-based sentiment models.
Accomplishments that we're proud of
- Building a fully functional Reddit analyzer that scrapes, filters, analyzes, and visualizes data end-to-end.
- Implementing a cache system that makes repeated analyses significantly faster.
- Creating a clean, intuitive web interface for non-technical users.
- Expanding from a niche use case (professor reviews) into a scalable, general-purpose sentiment tool.
What we learned
- How to work with real-world unstructured data and clean it effectively.
- How to combine NLP techniques (sentiment, subjectivity, normalization) into a cohesive system.
- The power and limitations of lexicon-based sentiment models like TextBlob compared to transformer-based models.
- How caching and API rate limits shape real-world application design.
- That Reddit data can reveal surprisingly accurate public sentiment when properly filtered.
What's next for Reddit Sentiment Analyzer
- Integrate transformer-based summarization (e.g., BART or T5) to generate natural-language summaries.
- Add visual analytics, such as sentiment-over-time charts or keyword clouds.
- Support multiple data sources (Twitter/X, YouTube comments, product reviews).
- Expand the cache system into a persistent storage database (like SQLite or Redis).
- Time based support for when to clear cache.
- Improve topic relevance filtering using semantic similarity models (e.g., sentence embeddings).



Log in or sign up for Devpost to join the conversation.