Inspiration
Every team shipping AI features hits the same wall: the bill and the quota. API quotas get exhausted without warning in the middle of the day. Expensive frontier models get used for trivial, repetitive prompts. A single misbehaving agent loops and burns thousands of tokens before anyone notices. The tooling that exists is reactive — you find out after the overage, from a billing dashboard. We wanted the opposite: a system that watches the spend and the infrastructure in real time and acts on its own, before the damage is done.
What it does
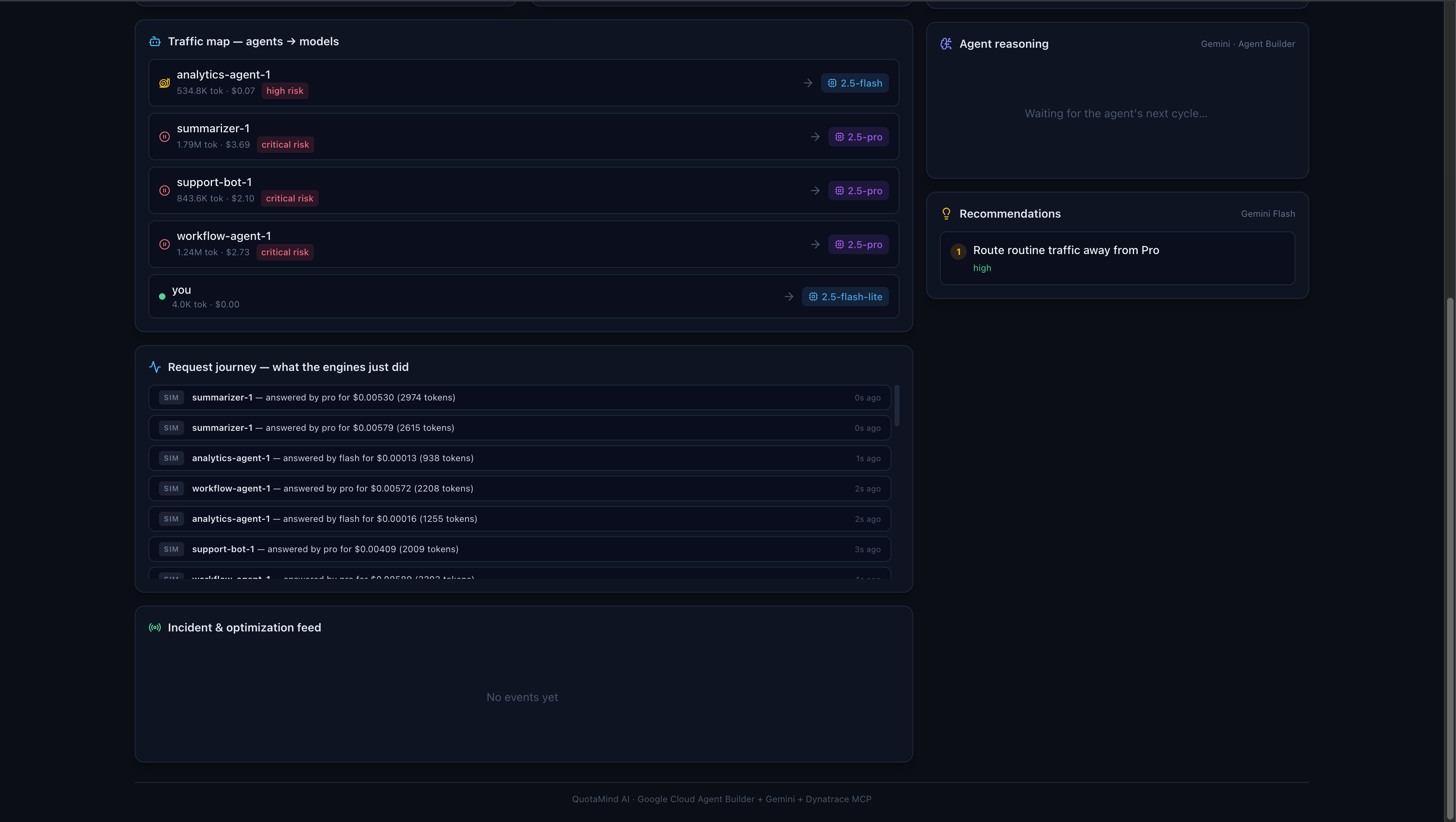
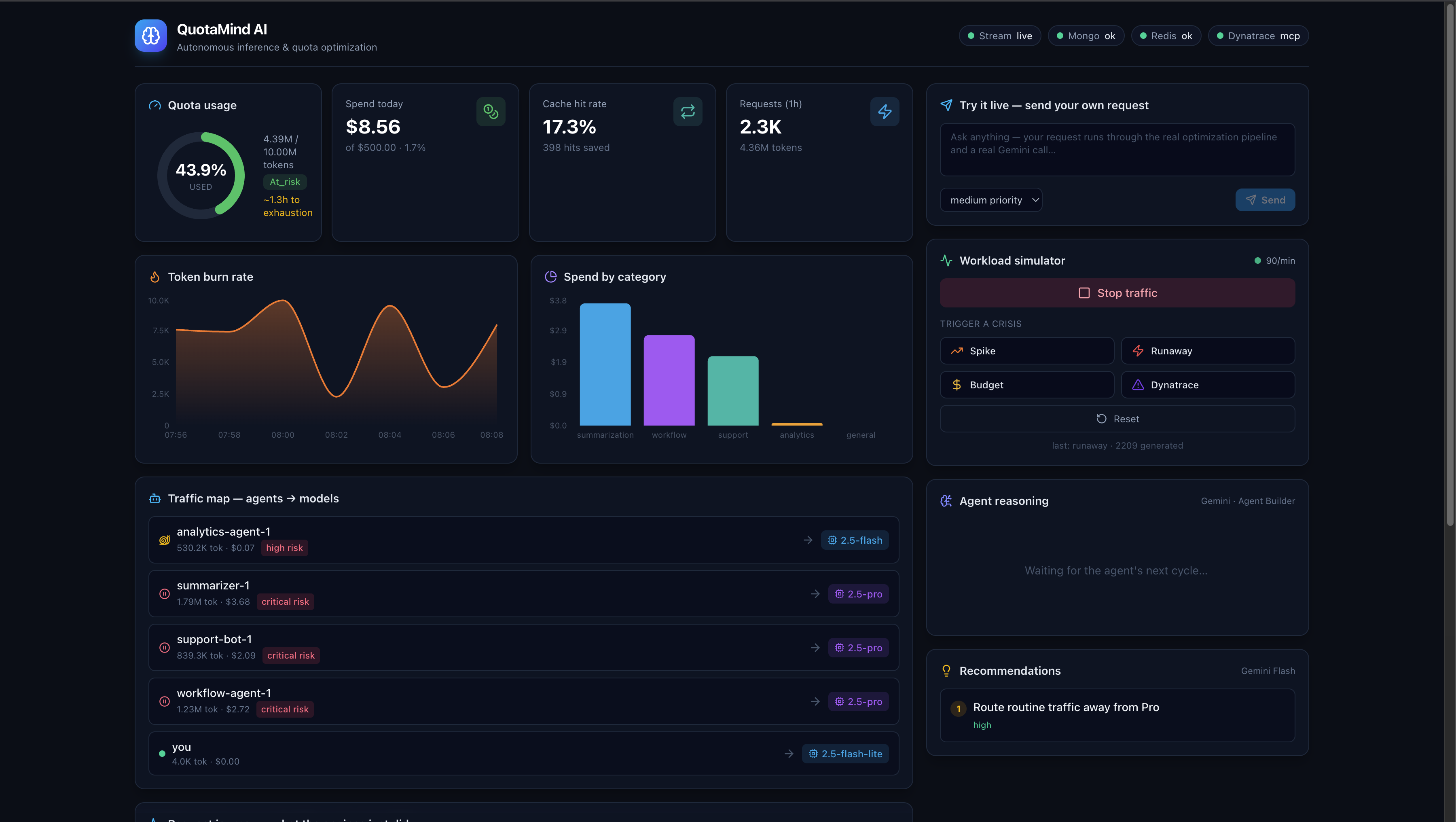
QuotaMind AI is an autonomous inference-optimization agent — not a chatbot. It sits in front of your AI workloads and continuously:
- Reroutes requests to the cheapest model that still satisfies the request's priority (e.g. downgrading Gemini 2.5 Flash to Flash-Lite when full power isn't needed), with a guaranteed priority floor.
- Caches semantically duplicate requests in Redis and serves repeats in milliseconds for $0.
- Throttles and blocks low-priority calls as spend approaches the daily budget, so you never blow past the quota.
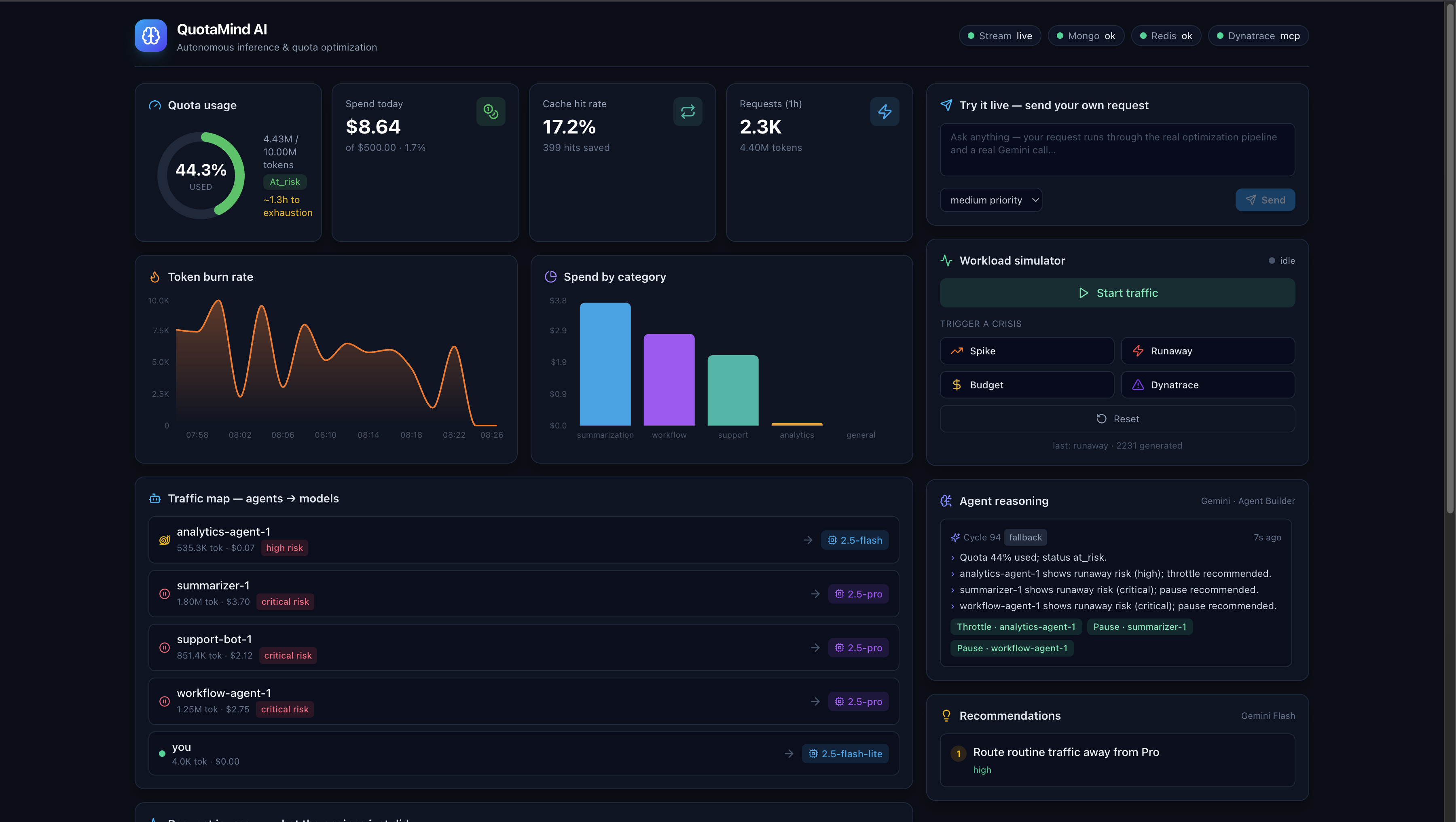
- Forecasts when you'll exhaust quota or budget at the current burn rate.
- Reacts to live production health through the Dynatrace MCP server — when Dynatrace reports a real problem or latency spike, the agent adjusts routing to protect the system.
An autonomous orchestrator runs every few seconds, inspects live traffic, cost, quota, and Dynatrace signals, and makes decisions — each one streamed to the dashboard with the reasoning behind it. No human in the loop.
How we built it
- Backend: FastAPI (Python 3.12), structured as independent optimization engines (routing, deduplication/cache, budget guard, compression) behind a request-ingest API. A background orchestrator loop reasons over live state using Google Cloud Agent Builder (Dialogflow CX) and Gemini.
- Real-time layer: A Redis pub/sub event bus fans out every decision and request to the frontend over Server-Sent Events, so the dashboard is a live view of the agent thinking.
- Observability as an input: We integrated the official
@dynatrace-oss/dynatrace-mcp-serverover stdio via the Model Context Protocol, with a REST fallback. The agent consumes Dynatrace problems and latency metrics as decision inputs — not just for display. - Data: MongoDB Atlas for persistence, Redis (Redis Cloud) for the cache and event bus.
- Frontend: A React + Vite + TypeScript dashboard styled with Tailwind CSS, featuring a live agent-decision feed, a request-journey view, and an interactive "Try it" panel that sends real requests through the system.
- Deployment: Both services run on Google Cloud Run. The backend image bundles Node so the Dynatrace MCP server runs in-container; the service-account key is injected via Secret Manager; images build through Cloud Build.
Challenges we ran into
- MongoDB Atlas vs. Cloud Run's dynamic IPs. The backend booted fine locally but crash-looped in Cloud Run with a cryptic
TLSV1_ALERT_INTERNAL_ERROR, Atlas was rejecting Cloud Run's egress IPs at the TLS layer. We traced it to the IP access list and opened network access for the serverless egress. - Running an MCP server on a serverless filesystem. The Dynatrace MCP server is launched via
npx, which needs a writable cache — something Cloud Run doesn't provide by default. It silently fell back to REST until we pointed npm's cache and home directory at a writable path. - Per-instance agent state. The MCP session and the SSE event bus live in process memory, so multiple Cloud Run instances made the health status flap between "mcp" and "rest." We pinned the service to a single warm instance for consistent, demoable behavior.
- Free-tier model quotas. Our Gemini key had zero quota on some model tiers, which silently broke routing for high-priority requests. We rebuilt the tier map around models the key could actually serve and adjusted the priority floor accordingly.
Accomplishments that we're proud of
- A real, live Dynatrace MCP integration — connected to an actual Dynatrace environment over stdio, not a mock — feeding the agent's decisions.
- A genuinely autonomous loop: the orchestrator reroutes, caches, throttles, and forecasts with zero human input, and shows its reasoning live.
- End-to-end deployed and verified on Google Cloud Run — we confirmed a real Gemini call, a live model downgrade, and a $0 Redis cache hit against the hosted URLs.
What we learned
- How to wire the Model Context Protocol into a production agent so observability becomes an actuator, not just a chart.
- The real operational gaps between "works on my machine" and "runs on serverless" — TLS allow-lists, read-only filesystems, and stateless instances each broke us in a different way.
- Designing an agent loop that is legible - every autonomous decision carries its reasoning, which turned out to matter as much as the decision itself.
What's next for QuotaMind AI - Autonomous Inference Optimization
- Support more model providers (OpenAI, Anthropic, Vertex) behind the same routing layer.
- Learned routing - use historical outcomes to predict the cheapest model that will still satisfy a request, instead of static tiers.
- Multi-tenant budgets and per-team quota policies.
- Deeper Dynatrace actions: open problems, annotate deployments, and close the loop from detection to automated remediation.

Log in or sign up for Devpost to join the conversation.