-
-
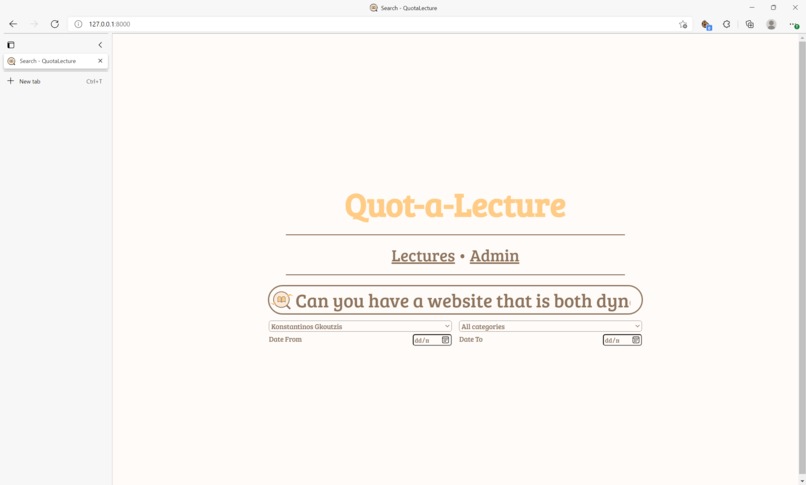
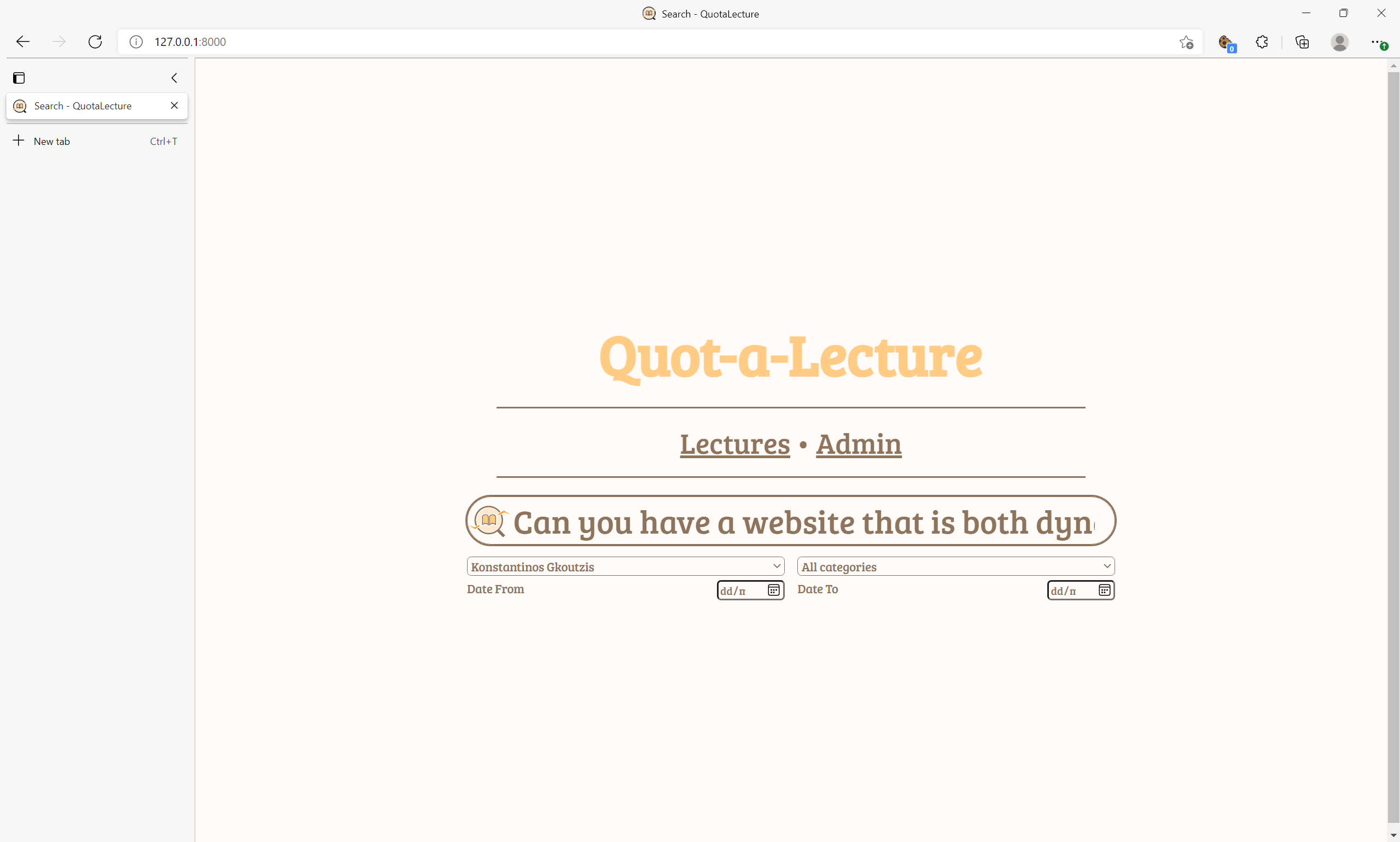
The main search page
-

The results page
-
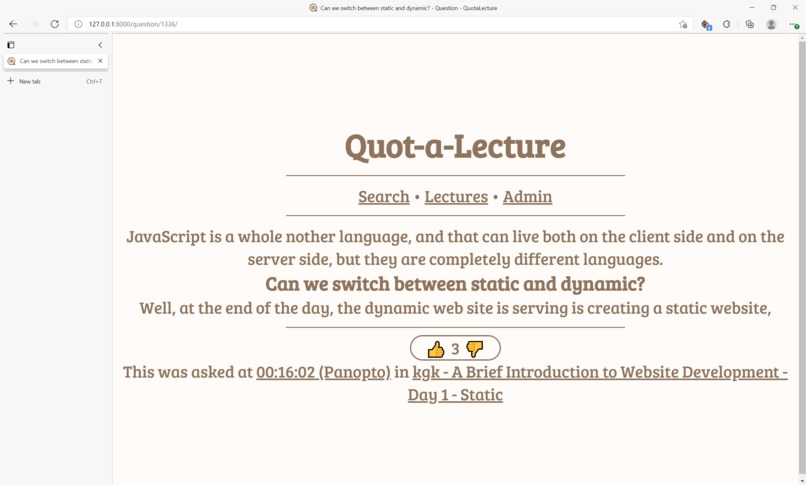
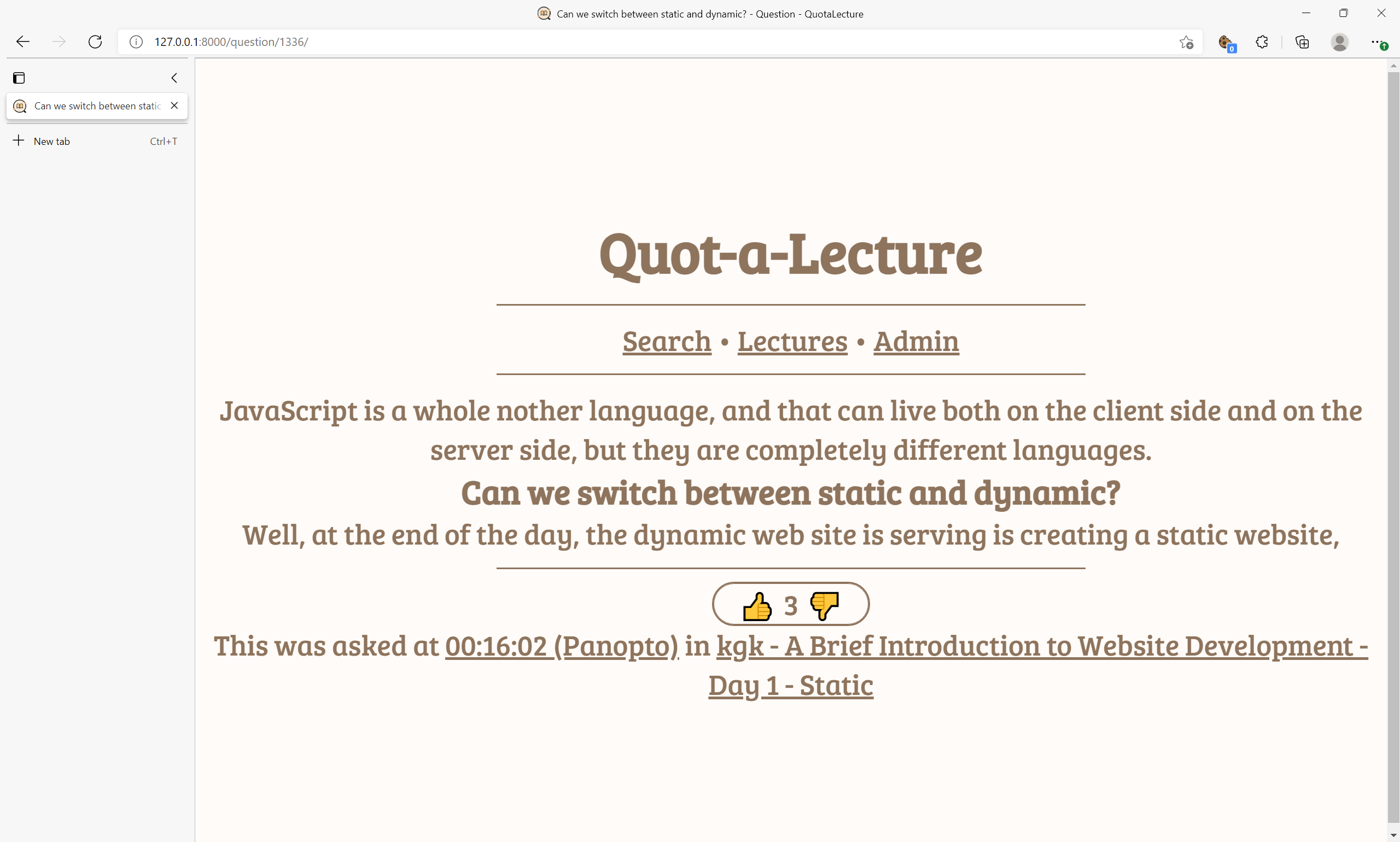
Detailed result
-

List of lectures by date
-

An iconic remark by an iconic person
-

GUI app for extracting Panopto transcripts from recordings




Inspiration
As students, we are frequently frustrated by the way questions and answers are handled in lectures. The same questions are brought up again and again, and it's hard to pinpoint where your queries are addressed by lecturers in recordings. Could we use NLP to automate this for us and access this information much faster?
What it does
We created a program to scrape transcripts and metadata from lectures uploaded on Panopto, and used NLP to extract questions from that data, similar to the one asked by the user. For each result, the user can click a link that directs them to the exact point in the video that the question was asked. It is also possible to sort by lectures and lecturers, for example, you can see all the questions asked in one lecture or filter out results based on the lecturer.
How we built it
We approached the task with the mindset of creating a prototype "minimum viable product" which demonstrates the main features and future potential of the service we envision. We used Selenium to scrape the Panopto website for transcripts and metadata, TkInter for a GUI app to make this process more convenient, NLTK and other NLP libraries in Python to analyse the raw data and determine similarities between questions, and Django to tie it all together.
Challenges we ran into
Unable to use the Panopto API due to lack of admin privileges, we improvised by using Selenium to scrape the website. It was surprisingly difficult to detect questions, and we used a relatively naive (but very effective) method for this in the end. It was also very hard to ensure that queries could be processed in a reasonable amount of time and returned relevant results, which we tackled using pre-calculated results and heuristics.
Accomplishments that we're proud of
It works surprisingly well! We were really happy to have created something that we (and others we spoke to) would actually use to make our learning easier.
What we learned
We learned how to use technologies such as Django, NLTK and Selenium. We also learned how to use Git effectively as a team working rapidly and simultaneously.
What's next for Quot-a-Lecture
We want to be able to incorporate user-driven ratings into the result rankings. We would also like to gain access to the Panopto API so that we can process lectures as they are uploaded, without the temporary solution of web scraping, so that we can work towards a more polished final product. We want to work on making queries more efficient using better methods for indexing.






Log in or sign up for Devpost to join the conversation.