-
Home Page
-

Our inspiration, Dr. Heinz Doofenshmirtz of Doofenshmirtz Evil Inc.
-
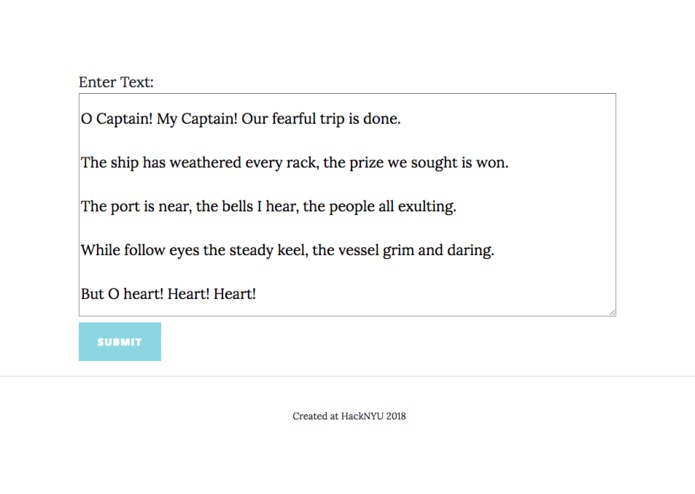
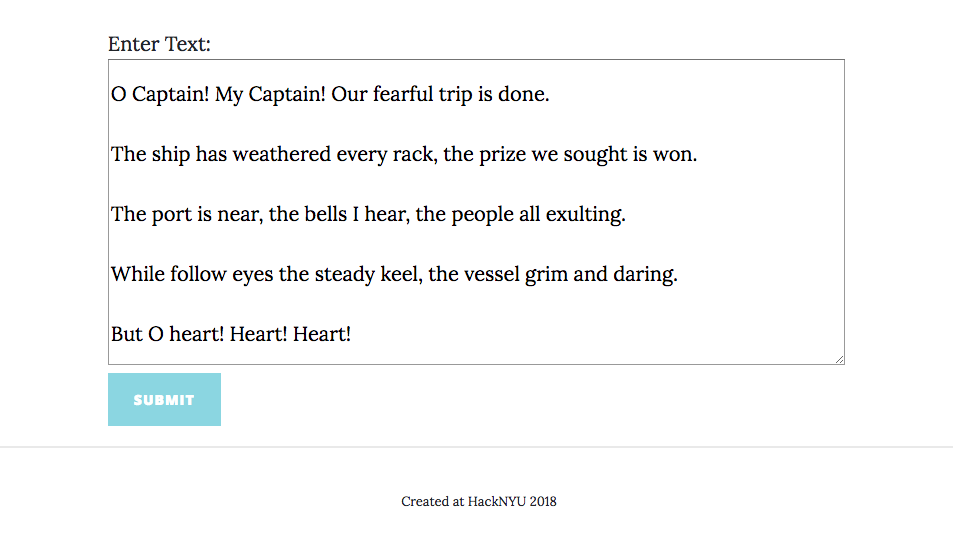
Entering a sample text
-

Questions are automatically generated
-

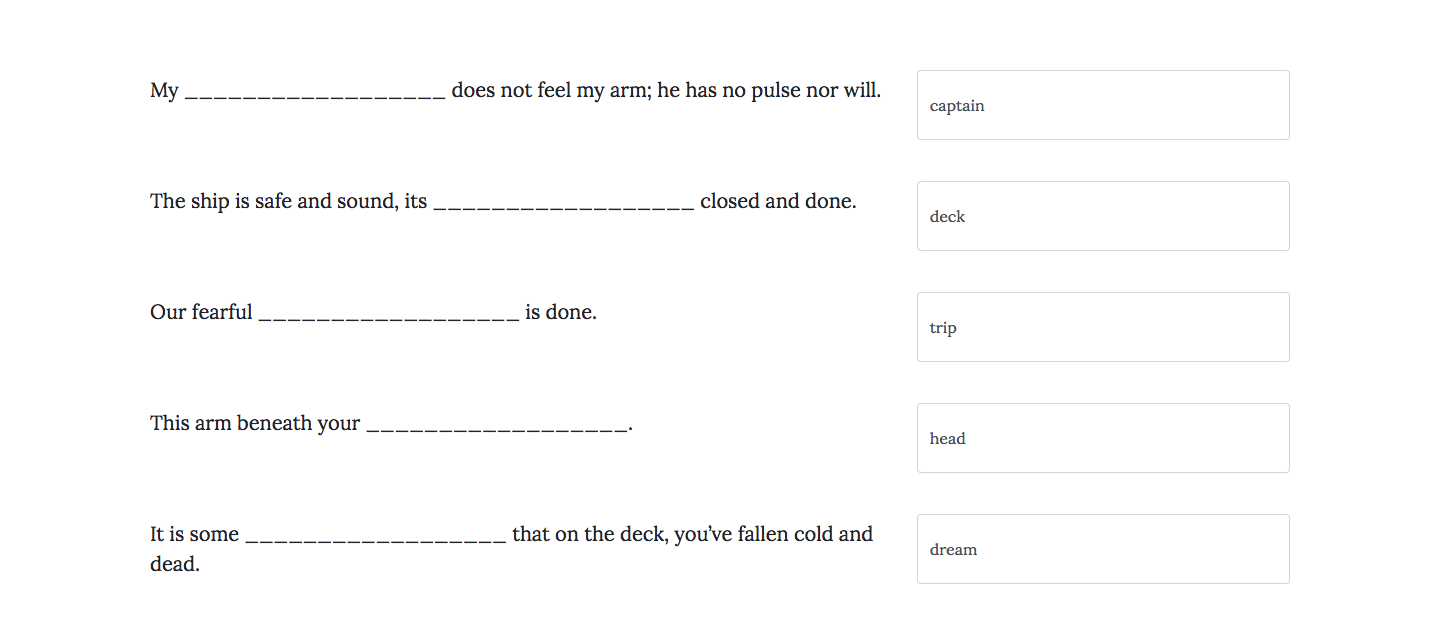
Answering the fill in the blank questions
-
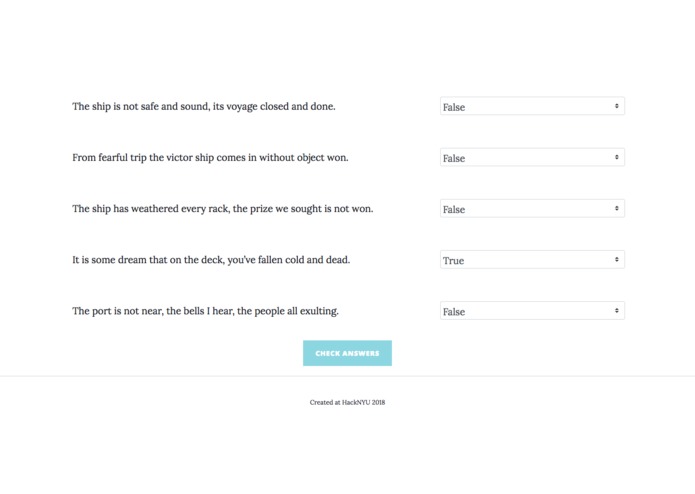
Answering the true/false questions
-

Checking the answers to the fill in the blank questions
-
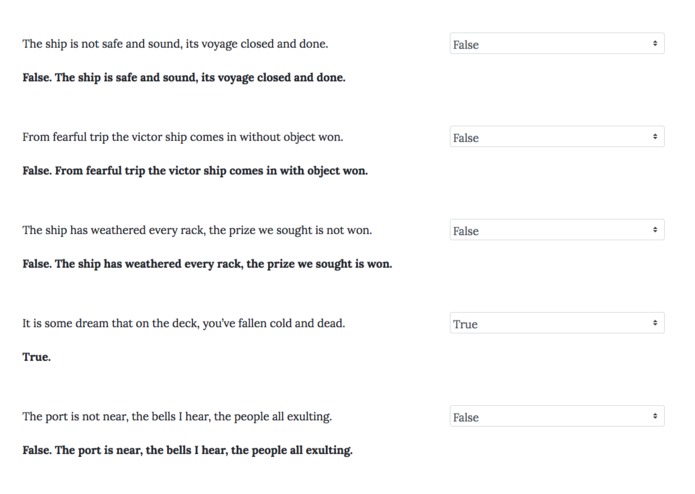
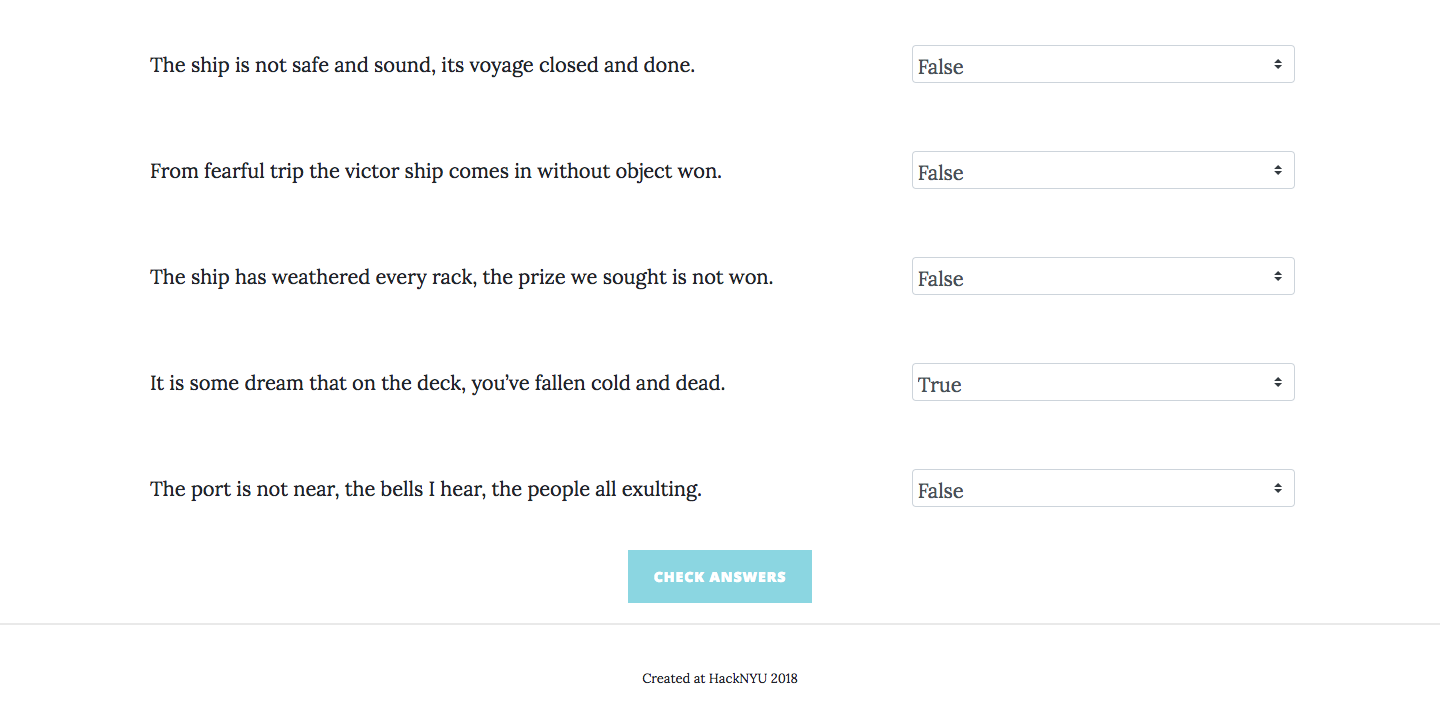
Checking the answers to the true/false questions




Inspiration
As students, we realize that studying isn't always easy. Sifting through lots of material in your textbook can be tiring. Therefore, we wanted to create a website that would solve this problem by automatically generating questions from a given text.
What it does
The Questionator 3000 automatically generates fill in the blank and true/false questions after the user submits text. Then, the user can attempt to answer these questions and check their answers.
How we built it
The website design was done with HTML, CSS, and bootstrap. Then, to generate the fill in the blank questions, we used the TextBlob package in python, which takes advantage of the NLTK library. To create true/false questions, we created our own python program, which works by searching for keywords and generating statements which can be true or false based on the keywords. After the user submits their answers, the website uses jquery and basic javascript in order to display the correct answers to the user. We also used the socket, a low-level networking interface, in order to integrate all the parts of our website together.
Challenges we ran into
This was our first time trying to develop a dynamic website, so we had lots of trouble learning how to integrate all the different parts of our website. However, learning how to do so was a great experience and we are proud of the final result.
Accomplishments that we're proud of
We successfully used libraries such as the NLTK library in order to generate simple questions for the user and integrated this functionality into a website. We think this is a great accomplishment, especially considering that this was our first hackathon for some of us.
What we learned
It was our first time trying to work with natural language processing, so it was our first time using resources like textblob and NLTK. It was also our first time developing a dynamic website, so we learned how to use socket in order to do so.
What's next for Questionator 3000
One of the things we wanted to have for Questionator 3000 was a function to generate questions based on a PDF. We were already able to use a library called pdfminer to convert the contents of a pdf into text, and from there generate questions in python. However, we were unable to implement this functionality into the website due to time restrictions. If we had more time, we would also like to experiment with technologies such as Amazon Rekognition to get text from images as well as PDF files, and also to use word sense disambiguation to generate higher quality questions.

Log in or sign up for Devpost to join the conversation.