-
-
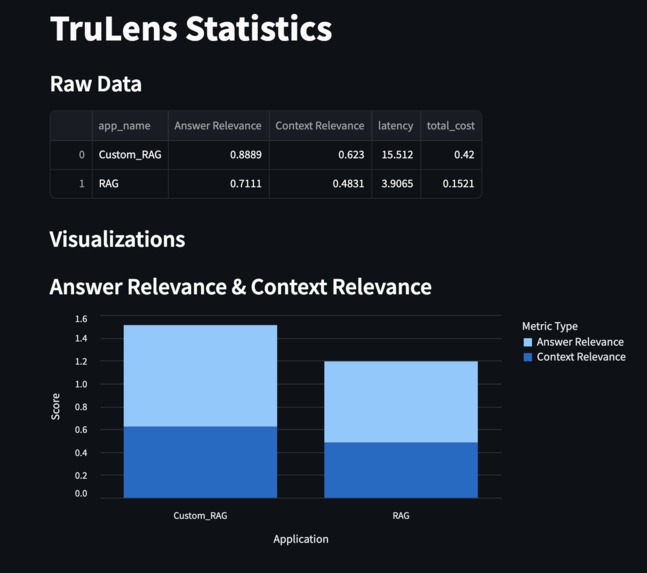
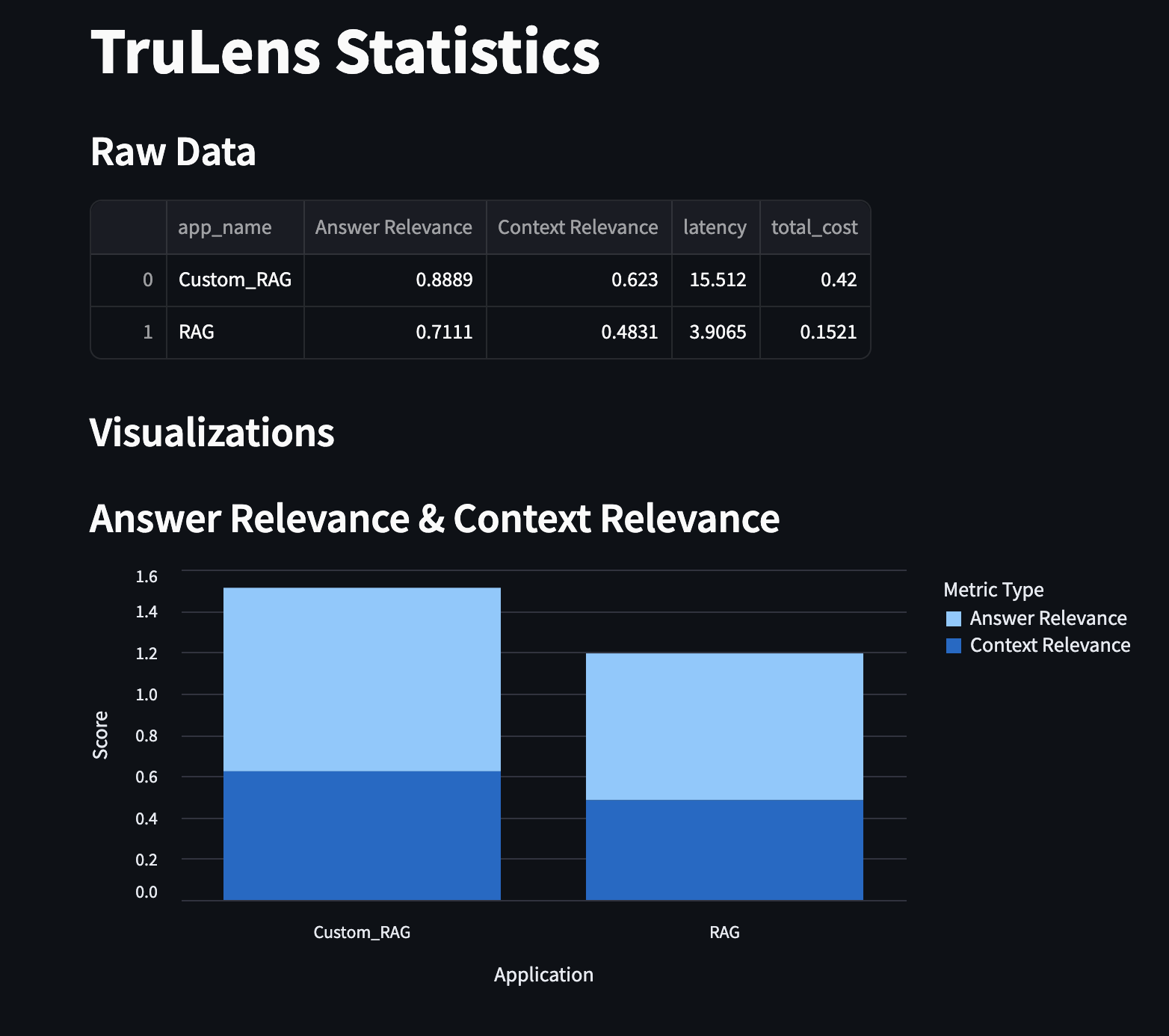
TruLens Statistics
-
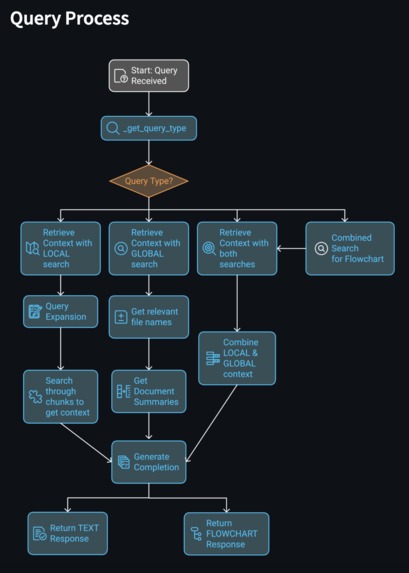
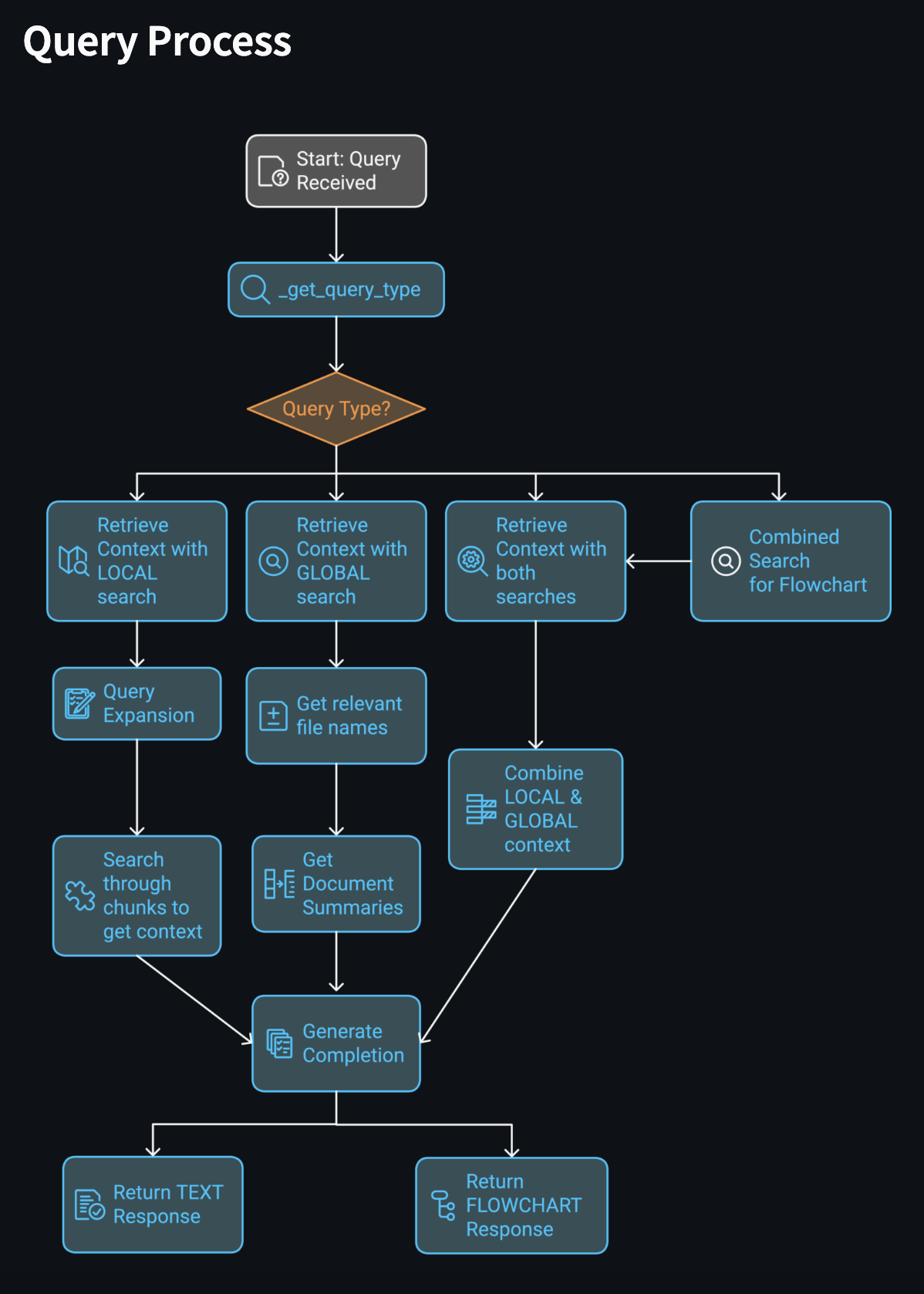
Query Process Flowchart
-
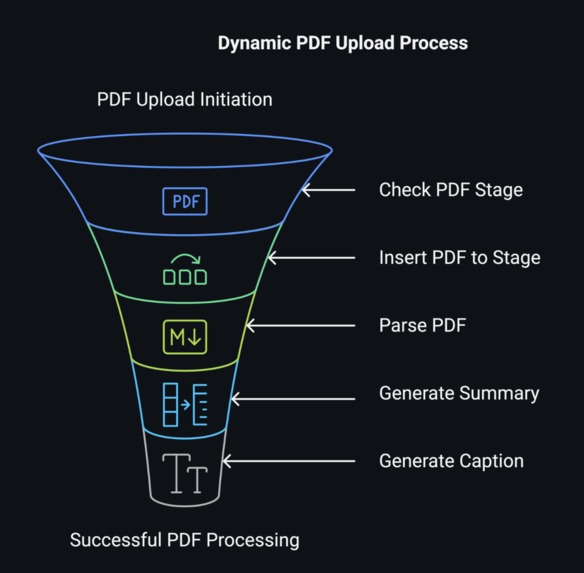
Dynamic Upload Flowchart
-
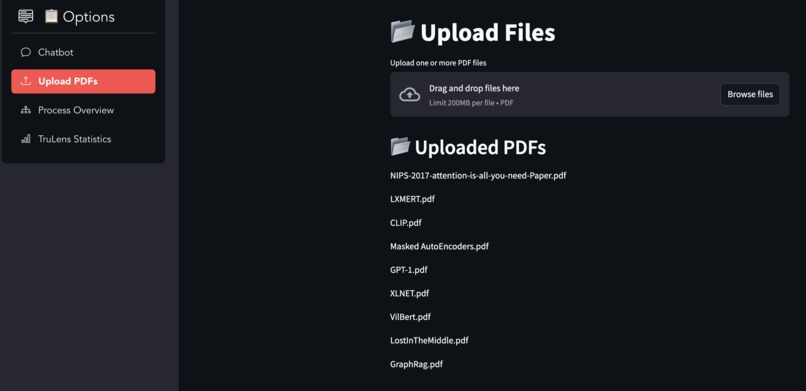
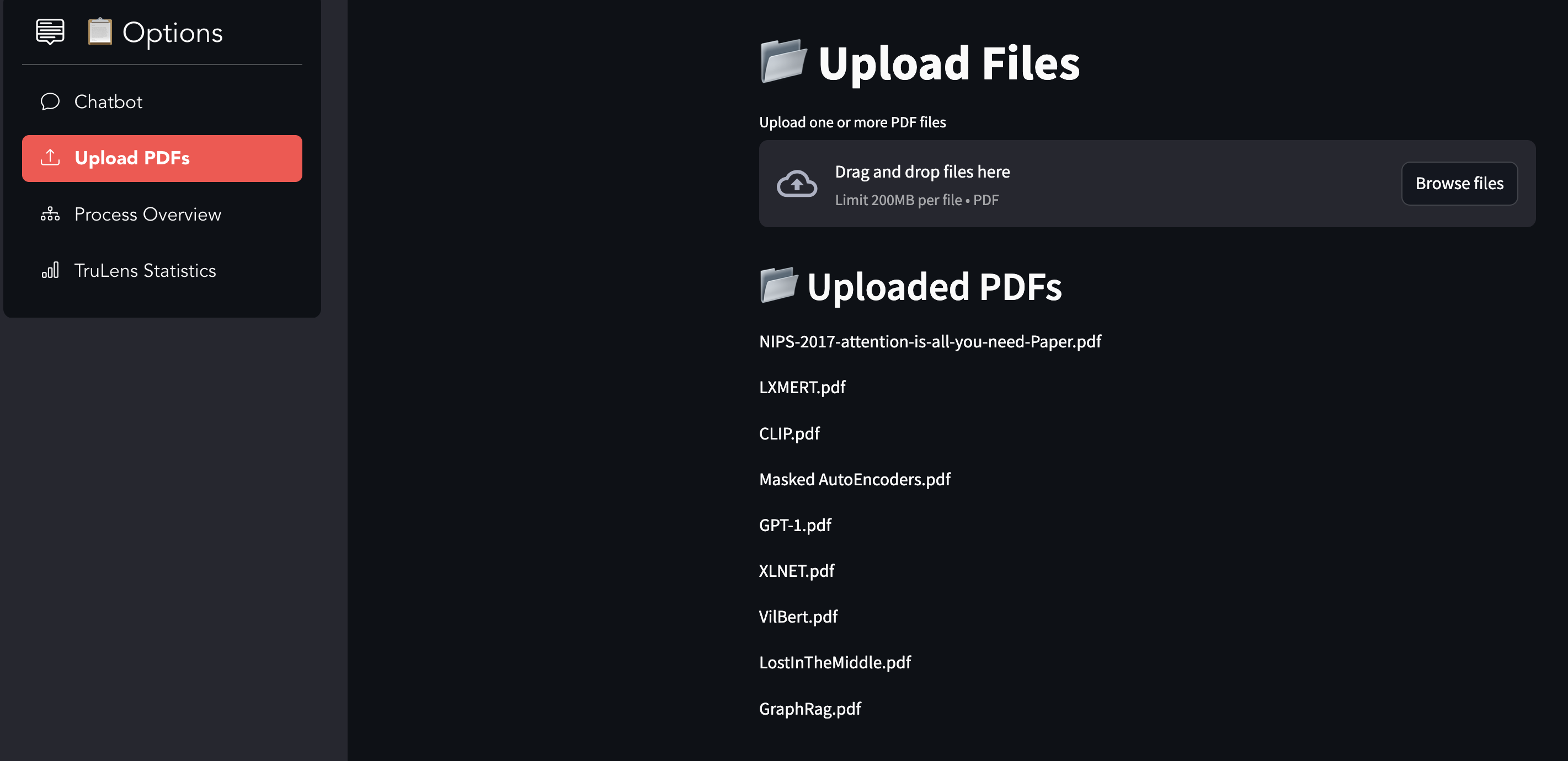
Upload Documents Tab
-
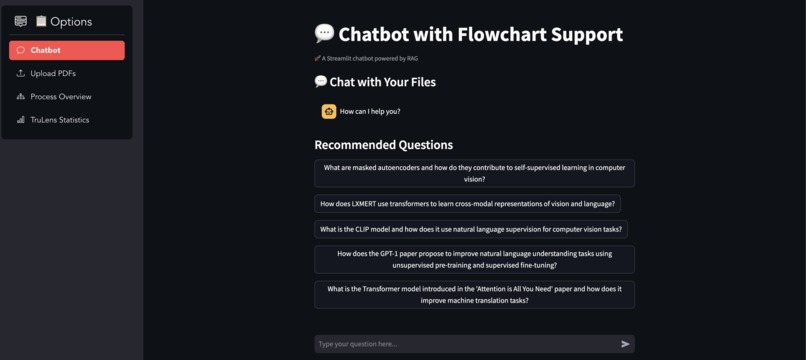
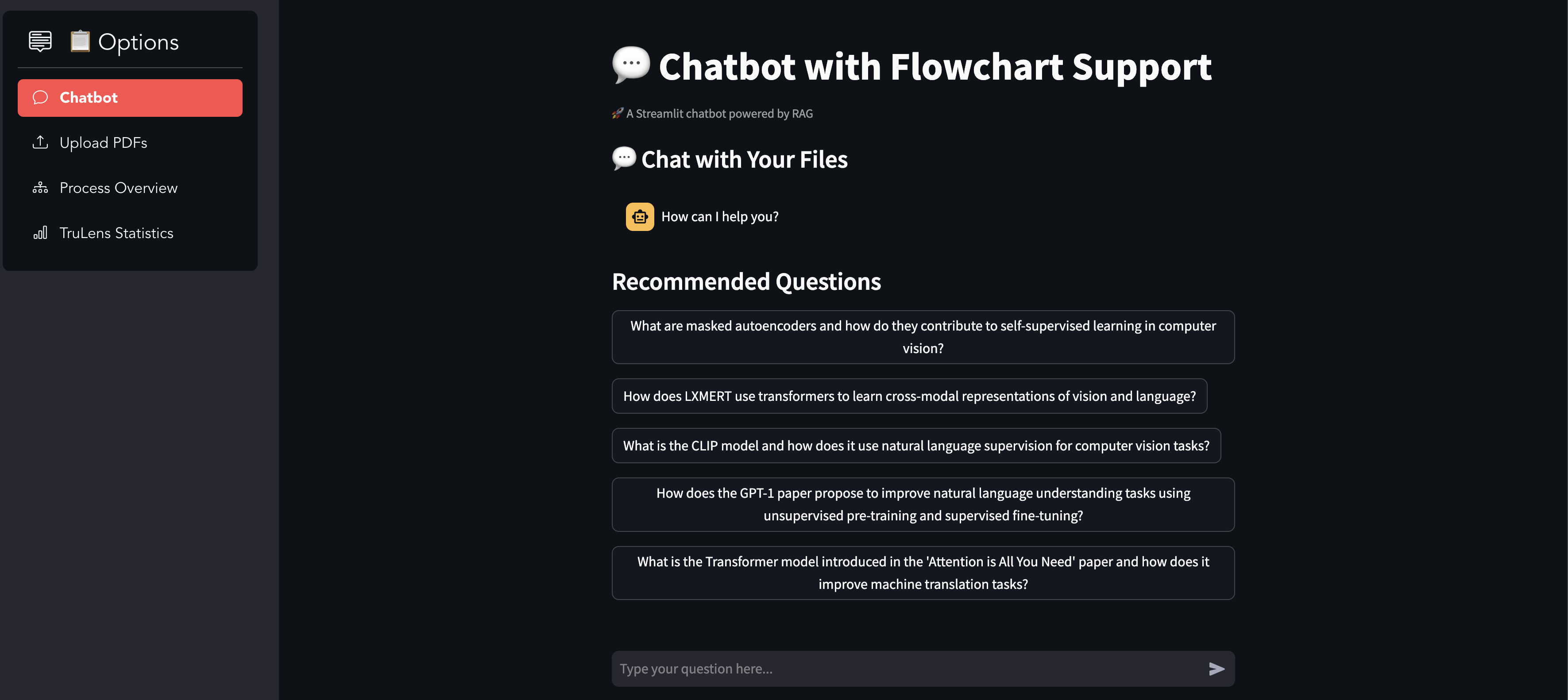
Landing Page for Chatbot
-
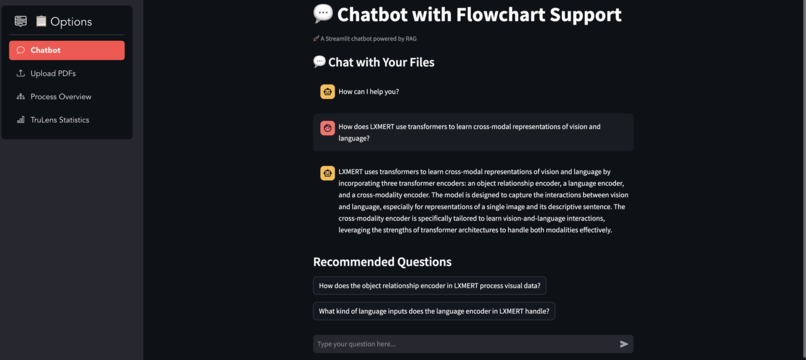
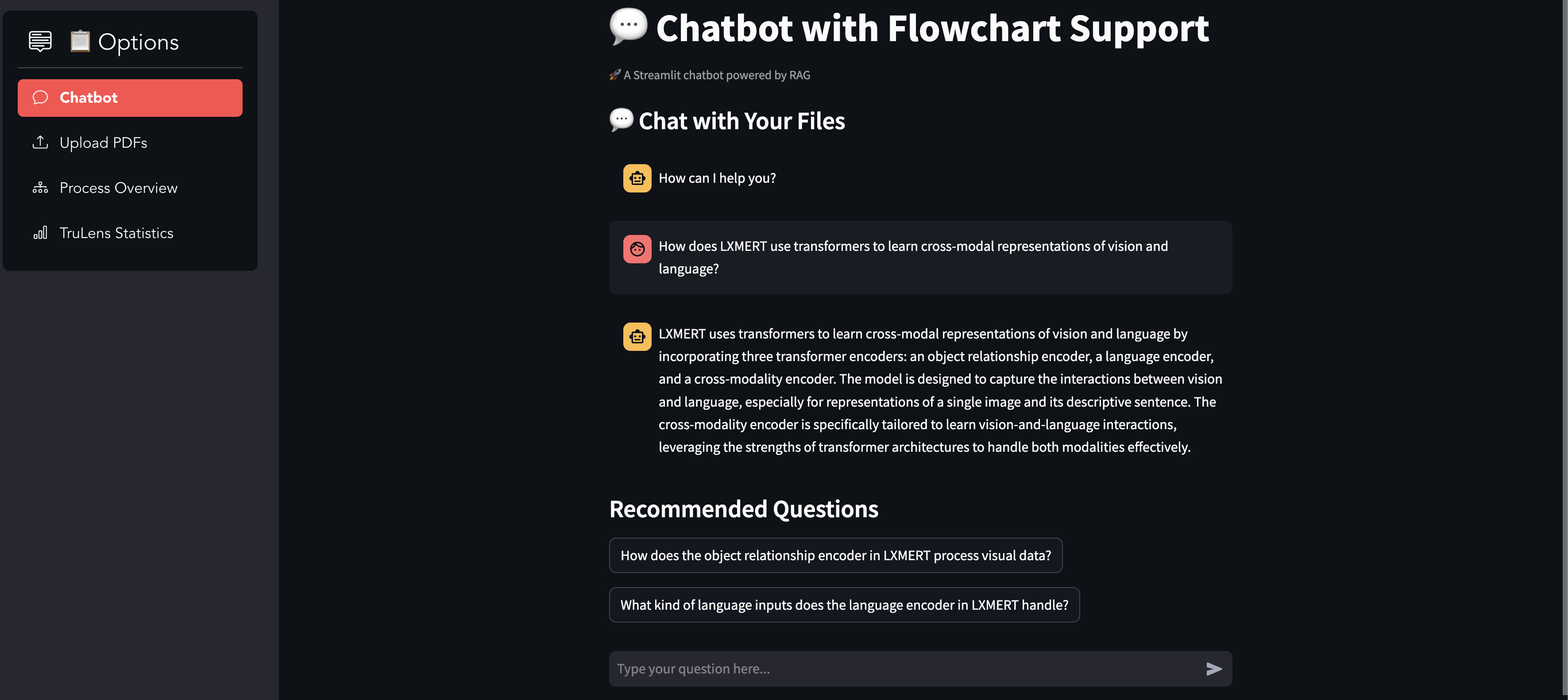
Query Answered
-
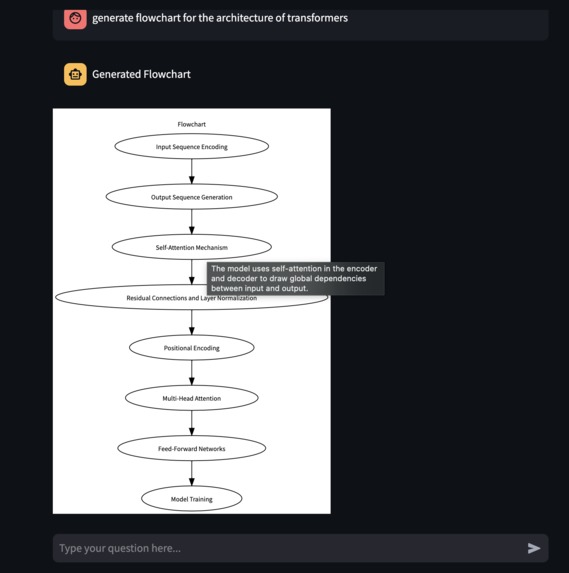
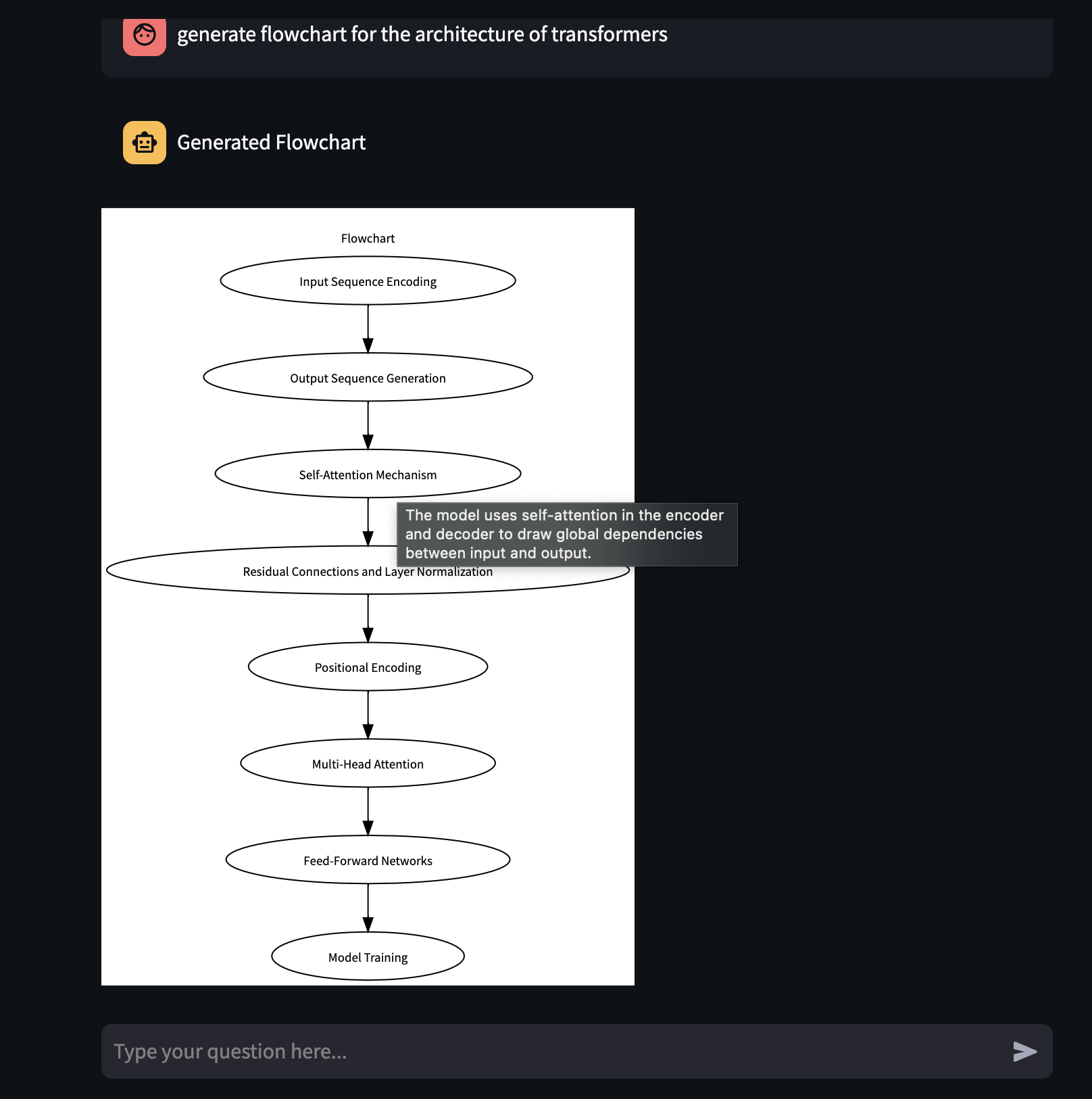
Flowchart Generation with hover feature

Inspiration
The rapidly evolving fields of transformer architectures and multimodal large language models are unlocking unprecedented possibilities. However, the sheer volume and complexity of landmark research papers often make it challenging to distill valuable insights. We wanted to create a solution that simplifies this process, providing accurate, detailed, and interactive answers to queries while catering to both textual and visual learners.
What it does
QueryVerse is an AI-powered Retrieval-Augmented Generation (RAG) system designed to:
Answer specific and complex questions from landmark research papers. Distinguish between local queries (specific data points) and global queries (synthesized insights across documents). Offer responses in text and visual formats, such as flowcharts. Allow users to upload their own research papers for custom query handling. Suggest follow-up questions to enhance the conversational flow.
How we built it
Backend: Cortex LLM powered by Mistral Large-2 LLM handles query classification and response generation. Frontend: A conversational chatbot interface implemented for smooth user interaction. Processing Workflow: Queries are classified into local, global, or hybrid types. Local queries trigger context fetching with query expansion, while global queries utilize pre-stored document summaries. Integration: PDF document uploads enable custom learning, enhancing versatility.
Challenges we ran into
Query Classification: Fine-tuning the system to correctly distinguish between local, global, and hybrid queries. Data Preprocessing: Ensuring efficient summarization, efficient chunking stratergies and context extraction for large, complex documents. Visual Representation: Developing a reliable pipeline for generating flowchart-style responses. Scalability: Optimizing the application to handle a wide range of documents and queries without compromising performance.
Accomplishments that we're proud of
Our Custom RAG scored significantly higher in Answer Relevance (0.8889) and Context Relevance (0.623) compared to the baseline RAG (0.7111 and 0.4831 respectively), while maintaining a focus on balancing operational cost and performance, as reflected in the metrics shown. We achieved better context relevance even in traditional RAG due to customised - markdown styled chunking strategy. Successfully integrating a hybrid query-handling approach that adapts dynamically to user needs. Implementing multimodal response capabilities, bridging the gap for visual learners. Allowing real-time learning from user-uploaded documents, enhancing the application’s versatility. Creating a seamless, user-friendly chatbot interface for both casual and technical users.
What we learned
The importance of query classification in generating accurate and contextually appropriate responses. Techniques for optimizing LLM performance on complex document-based queries. The value of catering to diverse learning styles by offering both textual and visual outputs. How to balance system efficiency with scalability for large-scale applications.
What's next for QueryVerse
Expanded Dataset Support: Broaden compatibility to include more research domains and document formats. Enhanced Visual Outputs: Add more visual formats like graphs and diagrams for complex answers. Language Support: Extend functionality to support multilingual queries and documents. Real-Time Collaboration: Enable collaborative query handling for teams and research groups. Open Access: Provide an open-source version for educational and research purposes, fostering community-driven improvements.
Built With
- cortex
- langchain
- mistral-large2
- streamlit
- trulens

Log in or sign up for Devpost to join the conversation.