-

Title
-

The Problem
-

The Solution
-

How It Works
-

Key Features
-
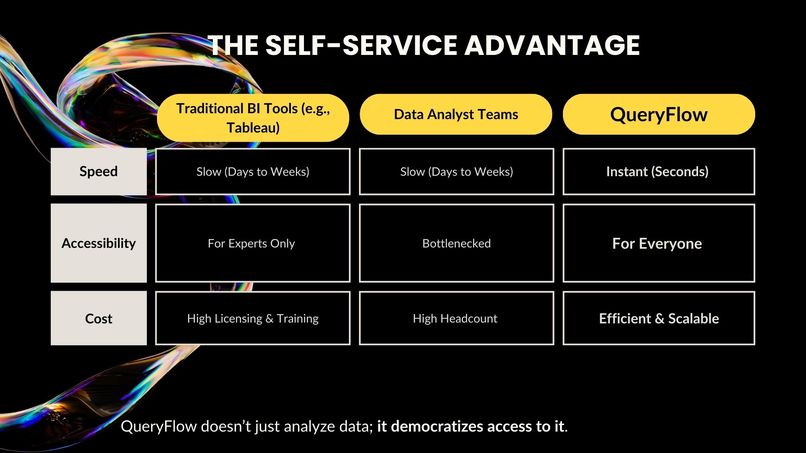
The Competitive Edge
-

Market Opportunity
-

The Impact
-

Thank You








Inspiration
As a data science student, I've repeatedly seen the disconnect between the people with the questions (the business and marketing teams) and the people with the answers (the data analysts). Business moves at the speed of thought, but data analytics is often stuck in a queue, waiting for a technical expert to write a SQL query. This bottleneck doesn't just slow down projects; it stifles curiosity and prevents a true data-driven culture from forming.
This project was directly inspired by my work on a Natural Language-to-SQL Copilot, where I saw a clear opportunity to build a full-stack application that could put the power of data directly into the hands of those who need it most.
What it does
QueryFlow is a self-service analytics platform that allows non-technical users to have a conversation with their data. Instead of writing complex code, users can simply ask questions in plain English, like "What were our top 5 selling products in the last quarter?" and receive an instant, interactive visualization of the answer. It’s designed to democratize data access and make every team member feel empowered to make data-driven decisions.
How it was built
QueryFlow is built on a modern, open-source AI stack.The core of the application is a multi-stage query generation pipeline engineered in Python.
Backend: LangChain and Hugging Face Transformers were used to orchestrate the interactions with a Large Language Model (LLM). Core Logic: The real innovation lies in using vector search on schema embeddings. The vector representations of the database schema, which allows the AI to understand the context and relationships within the data, leading to more accurate SQL generation. Frontend: The interactive dashboard was prototyped using Streamlit to create a simple and intuitive user experience.
Challenges
The primary challenge was achieving high accuracy in the SQL generation. Translating the ambiguity of human language into the precise, unforgiving syntax of SQL is incredibly difficult. Early iterations struggled with complex queries involving multiple joins or specific date formatting. Overcoming this required engineering a more sophisticated, context-aware prompt pipeline and focusing heavily on how we represented the database schema to the model.
Accomplishments to be proud of
First and foremost, building a functional, end-to-end prototype that validates the vision. The most significant accomplishment, however, is the measurable impact on efficiency. Based on the performance of the underlying model, we established a rigorous evaluation framework that showed our system could cut the query time for analysts by an estimated 90%. This proves that QueryFlow isn't just a convenience, it's a massive productivity tool.
What was learned
This project reinforced that in AI, the backend model is only half the story. We learned that the user experience is paramount; if the tool isn't intuitive, no one will use it, no matter how powerful the AI is. Technically, we learned how crucial schema-aware context is for the LLM's reasoning process. Simply passing table names is not enough; the model needs a deep understanding of relationships, data types, and business logic to be effective.
What's next for QueryFlow
The vision for QueryFlow is to become the go-to conversational analytics tool for growing businesses. The roadmap includes:
Expanding Database Integrations: Adding native support for more databases like PostgreSQL, BigQuery, and Databricks. Advanced Visualizations: Allowing users to customize charts, create multi-panel dashboards, and share their findings. Enhanced Evaluation: Continuing to benchmark our model's execution accuracy against industry standards like the Spider benchmark to ensure best-in-class performance.


Log in or sign up for Devpost to join the conversation.