-
-
Group Poster
Who:
Andrew Kent (akent7) Ilija Nikolov (inikolov) Jikai Zhang (jzhang72)
Inspiration
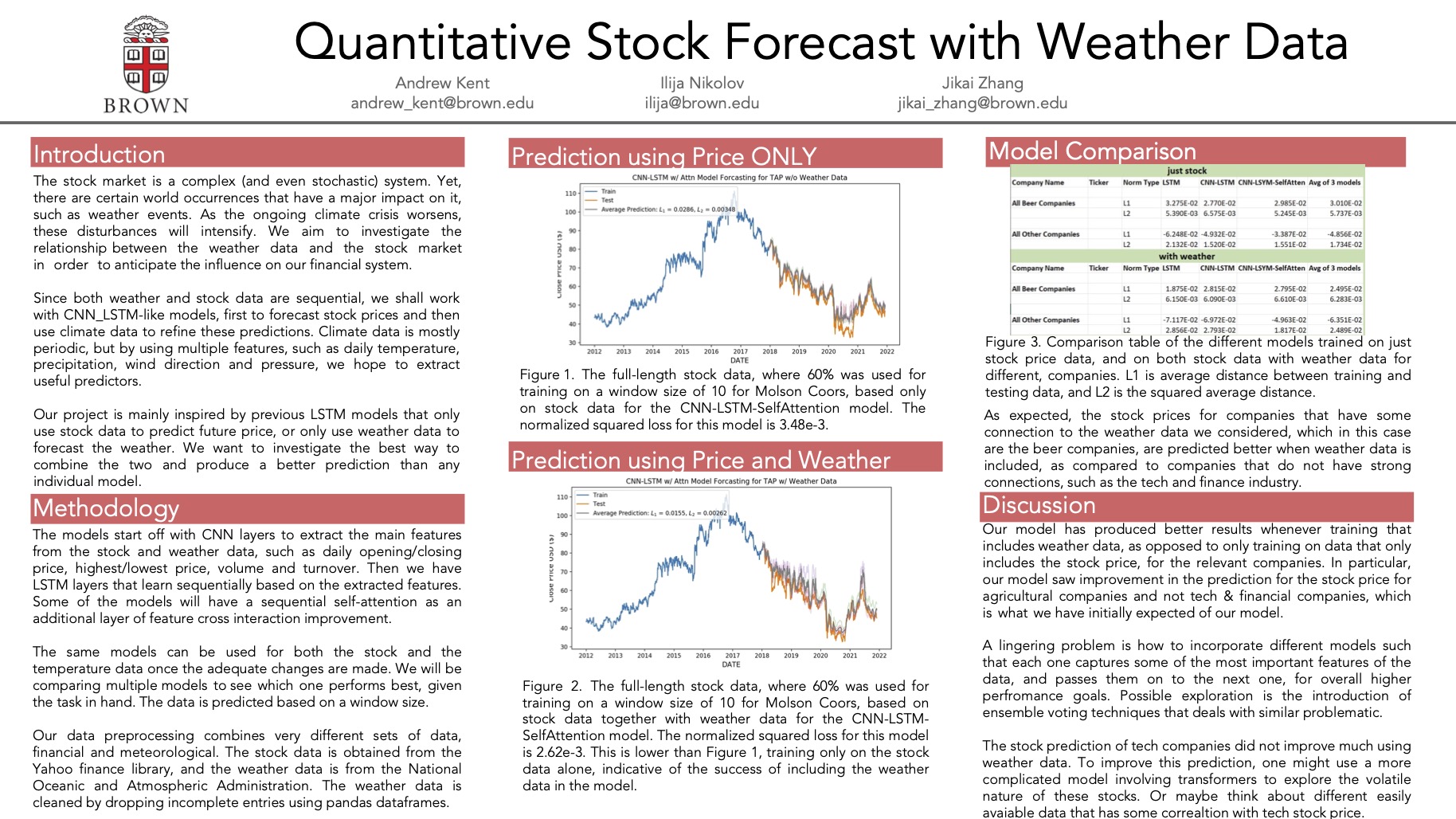
The stock market is a complex (and even stochastic) system. Yet, there are certain world events that have a major impact on the process. In the upcoming years, we will be faced with the consequences of the climate crises, such as more intense droughts, hurricanes, tornadoes and other weather storms. For these reasons, it might be beneficial to see to what extent the weather data in related to the stock market in order to get a sense of how climate change might impact our financial system in the future.
What it does
Predict stock prices using a CNN-LSTM, and also using weather data to refine the predictions: We are interested in helping financial institutions produce better forecasts. Certain major weather events certainly have an impact on the stock market, and in a way we are set forth to investigate this potential relationship.
Related Work
There is a lot of work in this subject, all major quant firms use neural networks to forecast stock prices and some use satellite images to refine those models.
We are primarily inspired by a paper titled “A CNN-LSTM-Based Model to Forecast Stock Prices” which uses a CNN to first get features of the data relating to the daily stock price like high, low, volume, etc., and then passes that to a LSTM which is then able to predict the future price very well.
There is also some work in using weather forecasting using neural networks to then infer and predict changes in relevant stock prices. Another paper we will be working out of for this part of the project, titled "Transfer Learning Application for Berries Yield Forecasting using Deep Learning", used temperature and soil reflectivity from satellite images. Yet another paper uses temperature weather data to directly predict the price of the stock and then prove the initial prediction.
Data
For stock data we will use the Yahoo Finance Python library, which provides us with parameters like opening price, highest price, lowest price, closing price, volume, turnover, ups and downs, and change.
For the weather data, we plan to use the Climate Data Online (CDO) tool provided by the National Oceanic and Atmospheric Administration (NOAA) which give free access to NCDC''s archive of global historical weather and climate data. These dataframes include hourly pressure readings, dew point and wet bulb temperature data, as well as wind direction and precipitation hourly recordings.
Methodology
We will first be using a CNN to extract features from our stock data which includes daily values of opening price, highest price, lowest price, closing price, volume, turnover, ups and downs, and change and then passing those extracted features to a LSTM. Some of the models we consider will have a sequential self attention layers.
The second part of our project will be using temperature and soil reflectance data to refine our prediction of stocks which are intimately related to those types of changes, to do this we will be looking over one region of the country - passing the weather data per day through a CNN & sequential self attention and then passing the result through a LSTM.
Metrics
Success is easy to quantify for this kind of project, we will aim to predict the stock price at least a week out for the initial stock predictor and success in the second part will mean that we are able to refine our predictions for stocks which may be affected on a regular basis by changes in weather. Lastly, convince ourselves that companies that are not related to the weather conditions in a region won’t be refined.
Our stretch goals would be to be able to accurately predict the price of stocks more than a few weeks into the future.
Accuracy for us will be to minimize the difference between our predictions and the real stock price.
- Lastly, convince ourselves that for companies that are not related to the weather conditions in a region, their stock prices won’t be refined.
Ethical Considerations
- Why is Deep Learning a good approach to this problem?
This project focuses primarily on data that does not involve people directly. The privacy concerns that other projects usually have are not present in this project. For that reason, DL is a good approach because even if we do not completely understand how the network actually works, the stakes are not as high as when people are directly involved. Nevertheless, we must be cautious about the impact this algorithm might have on companies whose stock prices we are predicting. Even though we want to help financial institutions to be better informed about the stock market decisions, we also need to take into consideration the “fate” of the companies that we focus on and make sure that our DL model does not hurt specific types of firms. For instance, if there are major storm events, it is expected that agricultural firms’ produce is impacted, and likewise the DL model might show that. However, we need to ensure that these firms are not targeted whenever there are not major storm events.
- What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain?
In our project the data is collected from the publically available Yahoo Finance (yfinance Library). In essence, this dataset is not considered biased because it is simply recording the stock market at certain points in time. What is more, the accessibility of the stock market to the general public would in principle guarantee that the data is available to everyone, so there shouldn’t be any ethical considerations about the collection of the data. However, there might be certain biases regarding what data is publicly available, that is, how refined the data is. In other words, if everyone is guaranteed free access to the market, it is rather strange that to get more detailed data, one must pay. This is certainly biased toward people with greater financial capability and is in disagreement with the idea of information availability.
Division of labor
- Andrew Kent: CNN-LSTM Model for Stock Prices
- Ilija Nikolov: Include weather data in the model (preprocess weather data and incorporate it)
- Jikai Zhang: Fine-tune the CNN-LSTM model to decrease the possibility of overfitting
We will be working together on all these parts to make sure that everyone understands each part of the model.
CS 2470 Final Project Checkin #2
Introduction:
The stock market is a complex (and even stochastic) system. Yet, there are certainly certain world events that have a major impact on the process. In the upcoming years, we will be faced with the consequences of the climate crises, such as more intense droughts, hurricanes, tornadoes and other weather storms. For these reasons, it might be beneficial to see to what extent the weather data is related to the stock market in order to get a sense of how climate change might impact our financial system in the future.
Challenges: What has been the hardest part of the project you’ve encountered so far?
Developing a model to do exactly what we have envisioned is a big challenge because it is a specific task that not many people have thought about before. This includes trying out different types of neural networks, such as convolutional neural networks, different types of recurrent neural networks, LSTMs as well as the famous transformers. Creating models that put these layers in the right order is a painstaking task and it requires a lot of thinking but also trying out because it is almost impossible to predict how the neural network will actually behave and which model is the best without testing it. One of the most difficult parts of this project is obtaining relevant data regarding a specific company’s stock prices and weather information. In order for the model to be able to have good training and predictions, the data needs to be high frequency and high fidelity. This in turn means that we would have a huge amount of data that requires bigger processing power for the model. Nevertheless, the model might be overfitting if we provide it with a lot of data. Thus, one must find a good balance between the high data volume, processing power and overfitting. This is a process that requires hyperparameter fine-tuning, including the learning rate, hidden dimension size as well as the number of hidden layers and other layer types.
Insights: Are there any concrete results you can show at this point?
Yes, we’ve been able to predict both future dewpoint temperature very well using many different pieces of weather data as well as being able to predict future stock prices using just the closing price. .
Plan: Are you on track with your project?
What do you need to dedicate more time to? We are able to predict future stock prices based on past stock data, as well as predicting dew point temperature data of a region from various climate parameters. We plan to further predict the yields of specific crops and also the stock price of agriculture companies in the region. Then we will train another model that takes in the price predictions from the two models and ensemble for a better prediction. What are you thinking of changing, if anything? Right now we’re working on making the code more easily digestible so that when we add more things on we have a very solid foundation on which to build. We are working on letting the model use ground truth information for a certain window size and then predicting one value after that, and also letting the model predict future values based off of its own predictions, right now the code is being changed to better accommodate switching between both modes.
What's next for Quantitative CNN-LSTM Stock Forecast with Weather Data
Implement different ideas to refine the prediction.
Final Write-up Google docs link
https://docs.google.com/document/d/1_DC--WIpb3J4CAQBGx2meOpaJkm-t7ACGZCseZ6Wc-Y/edit?usp=sharing



Log in or sign up for Devpost to join the conversation.