
Inspiration
We were inspired by one of our group member's parents, who runs a small business that frequently struggles to manage revenue and expenditure. We designed Quantiflow to help with these issues while also adding extra features to make running the business easier.
What it does
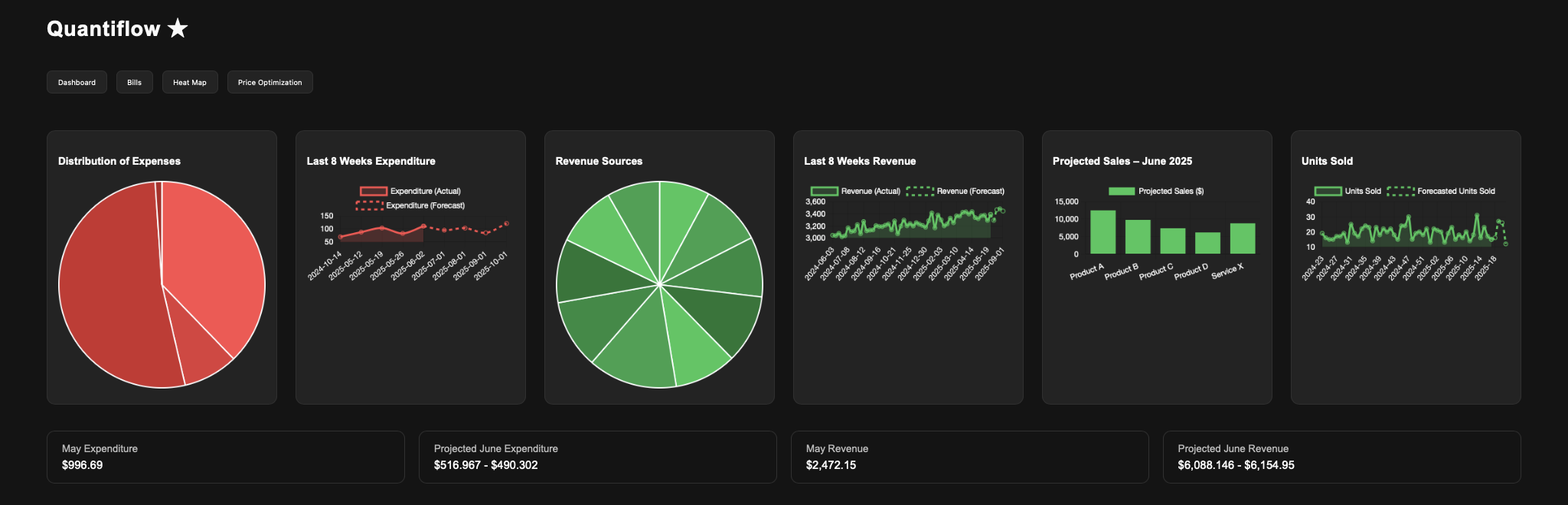
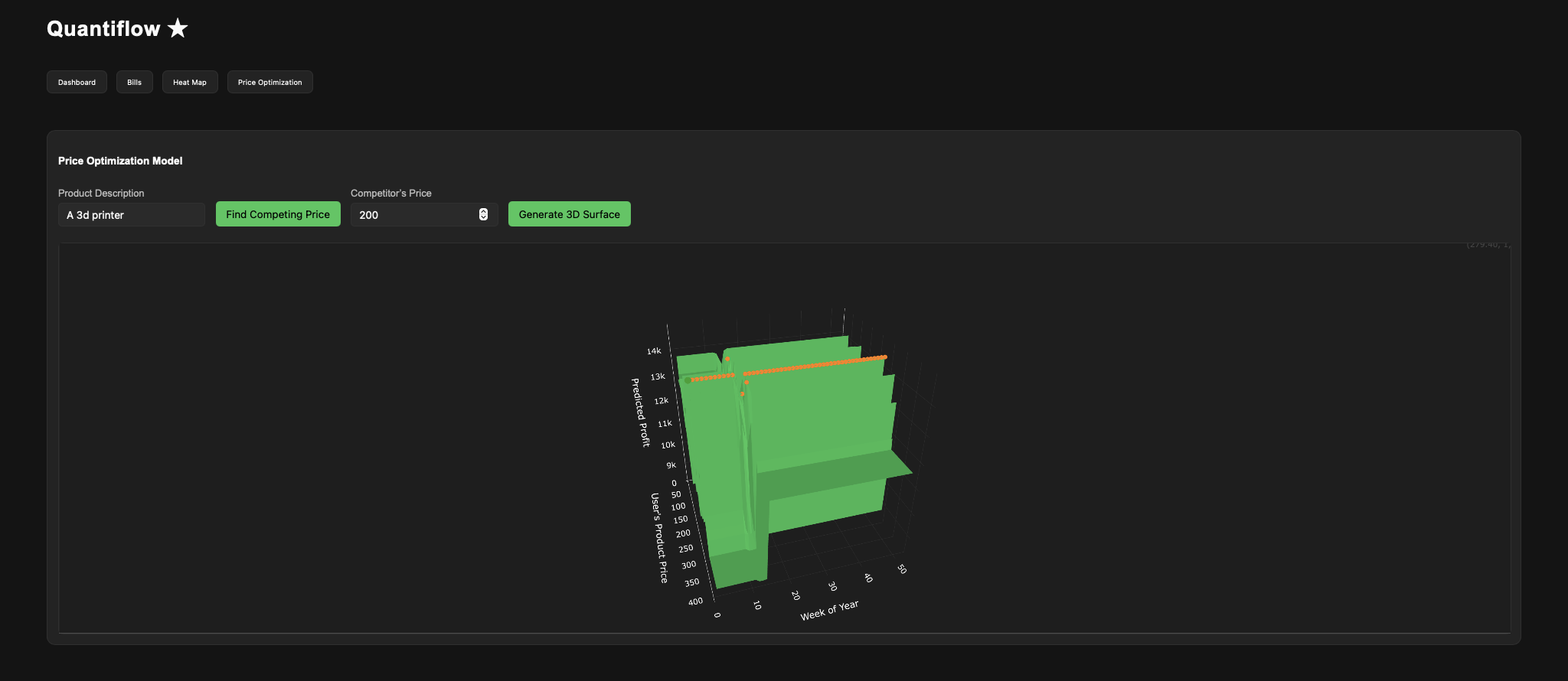
Quantiflow is a revenue and expenditure tracker that displays data simply with pi charts and graphs. Quantiflow also provides projected sales using prophecy, a statistical time series model to forecast potential sales. It can also use LLM(Large Language Models) to scrape the web to find the most competitive prices for any specific product. As a bonus, we can use location-based tracking to find the areas that the most buyers come from.
How we built it
We used a combination of OCR(optical character recognition) which reads the image, and LLM ( Large Language Model) which interprets the text that the OCR finds and presents it in a displayable format.
Challenges we ran into
- Our optical Character Recognition was not working consistently, so we came up with a preprocessing pipeline to increase the signal/noise ratio
- The RNN we tried to use to forecast was not stable, so we used a pre-trained Prophecy, which works well with seasonal data and random events
- Extracting data from LLM outputs was not stable, so we removed stochasticity from the outputs (heat=0) and used more forgiving regex patterns
- Perceptron models did not predict profit well, so we used random forest models, which are more powerful
- Random forest model constantly overfitted, so we used more input values (week of year, competitor price, proposed price) and tuned hyperparameters to reach R2 = 0.9
Accomplishments that we're proud of
Improved OCR Consistency
- Developed a custom preprocessing pipeline to increase the signal-to-noise ratio, stabilizing Optical Character Recognition results.
Enhanced Forecasting Reliability
- Switched from an unstable RNN to a pre-trained Prophecy model, which handles seasonal patterns and random events effectively.
Stabilized LLM Output Parsing
- Eliminated stochasticity by setting temperature to 0.
- Applied more forgiving regex patterns to reliably extract structured data from LLM responses.
Upgraded Profit Prediction Models
- Replaced underperforming perceptron models with robust random forest models.
- Enhanced model input with additional features (week of year, competitor price, proposed price).
- Tuned hyperparameters to achieve a strong predictive performance (R² = 0.9).
Resolved Heat Map Integration Issues
- Bypassed Folium’s HTML compatibility issues by rendering the map with Selenium and displaying the output as an image.
What we learned
We learned how to systematically debug and enhance machine learning workflows by identifying root causes of instability and applying targeted solutions. We discovered the importance of data preprocessing in improving OCR accuracy, the value of selecting models suited to specific data characteristics like seasonality, and techniques for making LLM outputs more deterministic and parseable. Additionally, we deepened our understanding of model evaluation and tuning by transitioning to more powerful algorithms and enriching feature sets to significantly boost predictive performance.
What's next for Quantiflow
We plan to improve the accuracy of our random force model and add an authentication system like a login. We also plan to add a tax calculating feature for the profit recorded on the app. We could also add automated restock alerts connected to inventory thresholds.



Log in or sign up for Devpost to join the conversation.