-
-
Quant Edge Exchange Overview
-
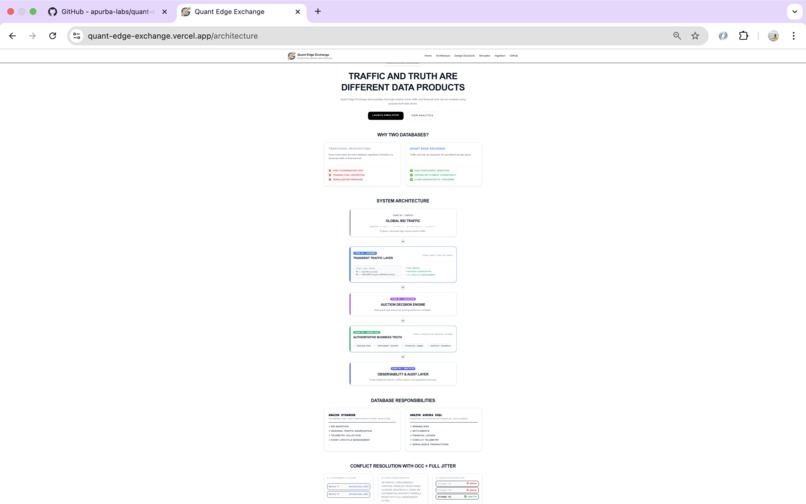
Distributed Architecture separating transient traffic from authoritative business truth.
-
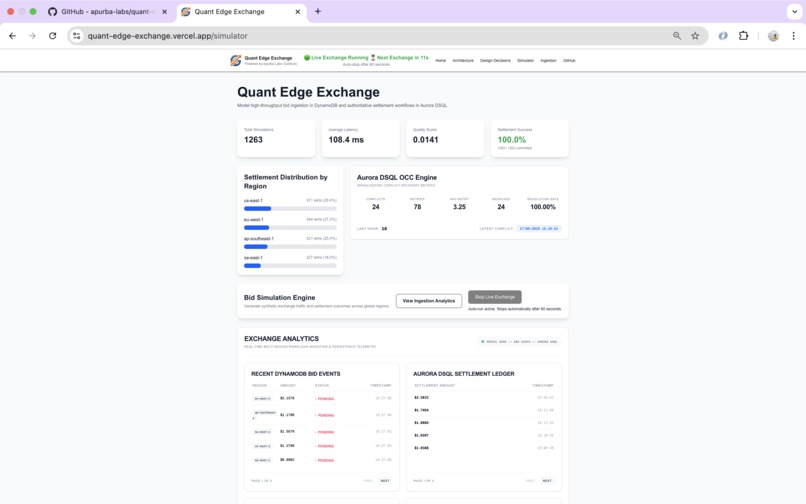
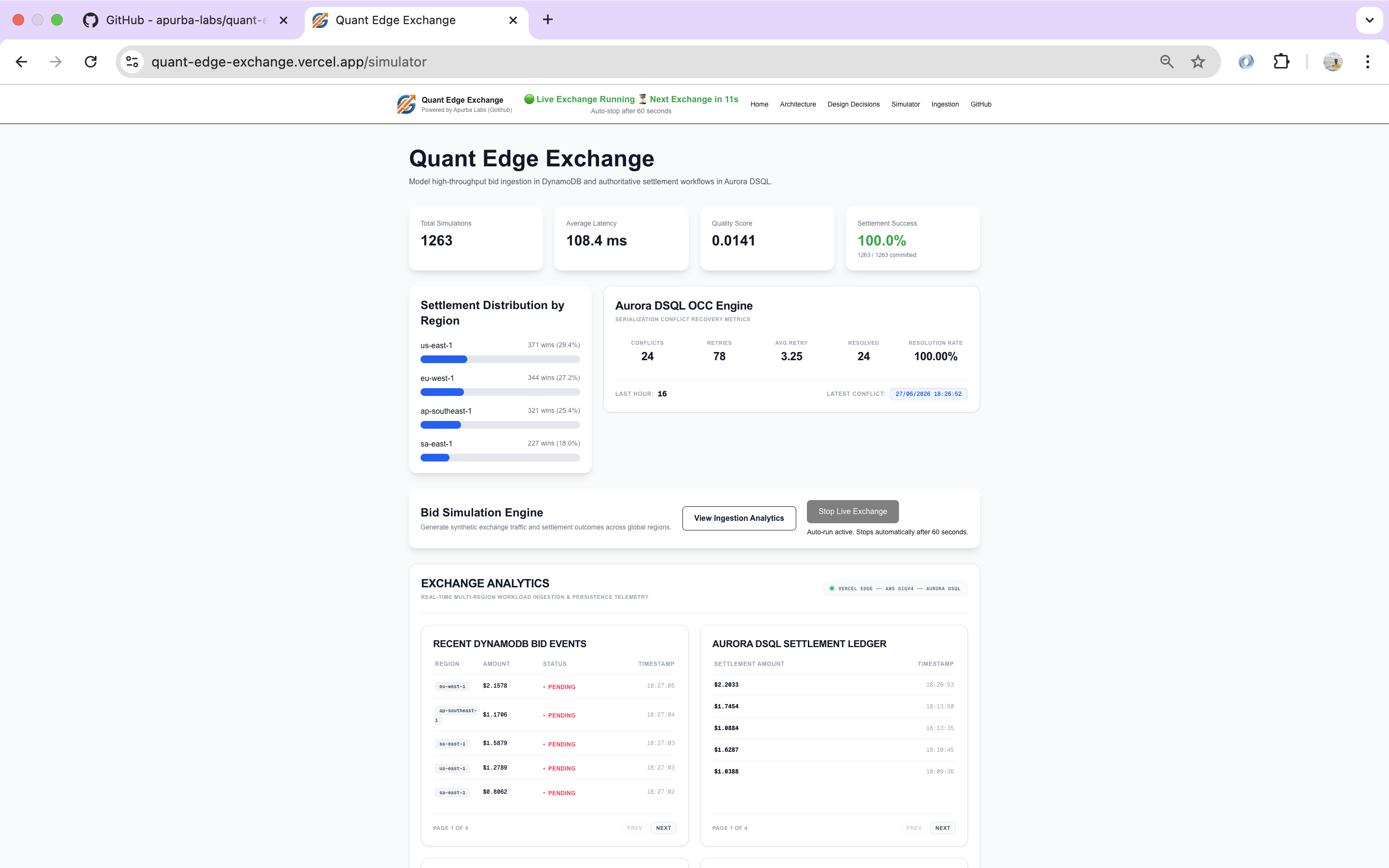
Live auction simulation with Aurora DSQL settlement, conflict recovery, and financial telemetry.
-
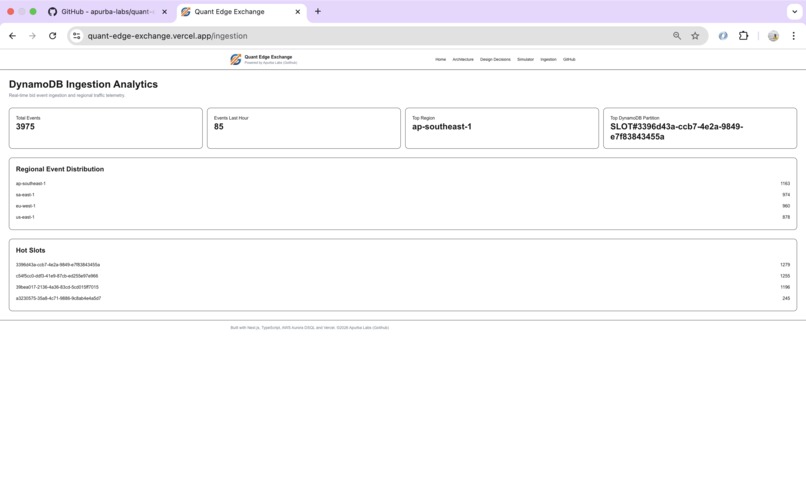
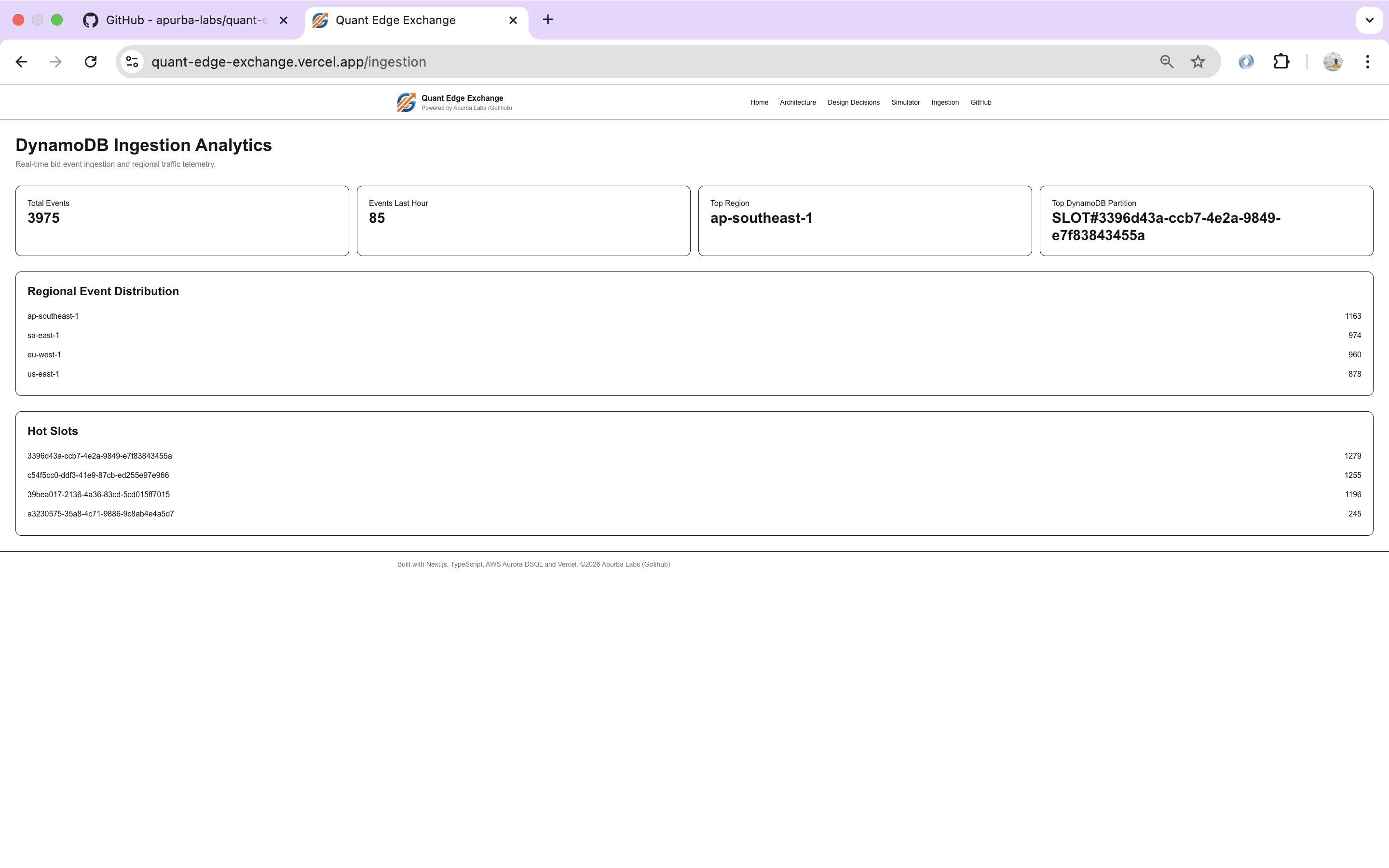
Amazon DynamoDB regional ingestion analytics and hot partition monitoring.
-
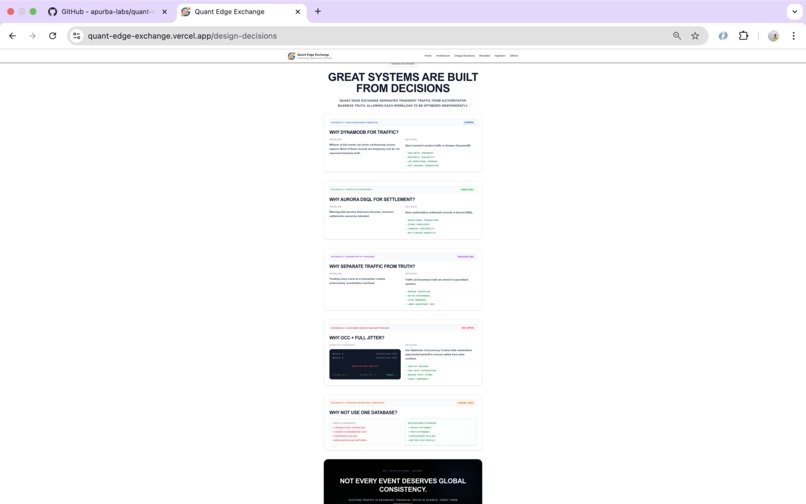
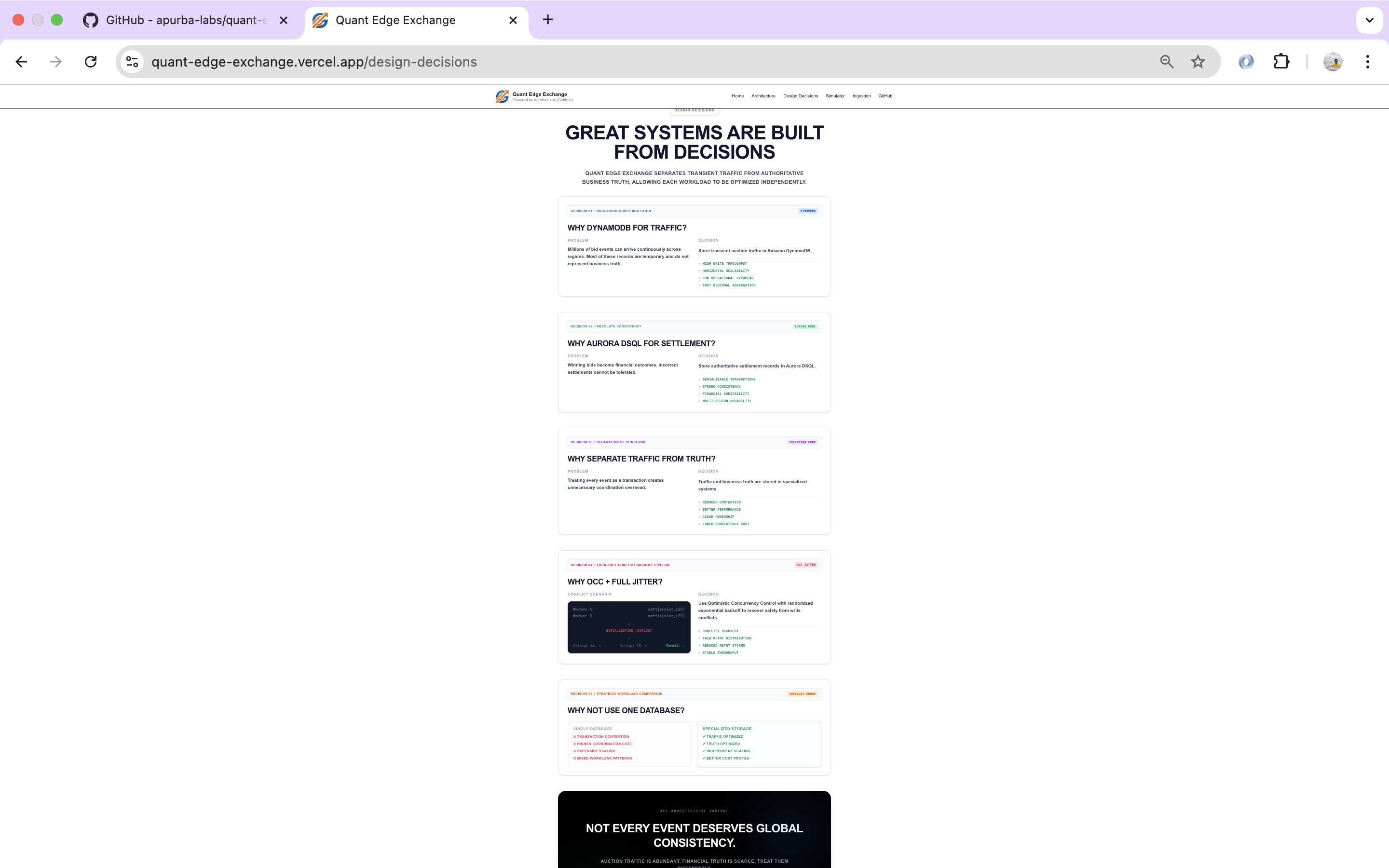
Engineering decisions explaining workload separation, consistency, and conflict recovery strategy.
Inspiration
This project didn't start during the hackathon.
It started while I was working on ThreatIDR, a cybersecurity platform that processes millions of DNS and security logs every day.
As the platform grew, so did our PostgreSQL database. We introduced TimescaleDB partitions, optimized indexes, improved retention policies, and spent a lot of time trying to balance storage growth with query performance.
Those improvements helped, but one question kept coming back.
Why are we treating every event as if it deserves the same level of consistency?
Most of the logs entering the system were completely normal. They were useful for monitoring, dashboards, and analytics, but they would never become a security incident.
Only a very small percentage would eventually be classified as real threats requiring investigation, long-term retention, and auditing.
Later, I realized the same pattern exists in many other systems.
Food delivery platforms receive thousands of orders, but many are cancelled before payment. E-commerce platforms process countless shopping carts that never become purchases. Advertising exchanges evaluate thousands of bids, yet only one becomes the final financial settlement.
Different industries, but the same architectural question.
Most events are temporary. Only a small percentage become permanent business records.
Around the same time, I started learning about Aurora DSQL and its globally consistent transaction model.
Instead of asking, "Can Aurora DSQL replace PostgreSQL?", I found myself asking a different question:
Which data actually deserves Aurora DSQL?
That changed how I think about distributed systems.
Some data simply needs to be collected quickly, analyzed, and eventually discarded.
Other data represents money, ownership, or business truth, and that's where strong consistency really matters.
To explore that idea, I built Quant Edge Exchange.
Advertising auctions turned out to be the perfect demonstration because everyone immediately understands the workflow. Thousands of bids compete for the same advertising slot, but only one becomes the official settlement.
The project isn't really about advertising.
It's about a design philosophy that grew out of real production experience:
Traffic and truth are different data products.
Distributed systems become easier to scale when coordination is applied only where business truth actually requires it.
What it does
Quant Edge Exchange is a distributed advertising exchange simulation that demonstrates one simple architectural idea:
Transient traffic and authoritative business records should not always be handled by the same database.
The platform simulates the complete lifecycle of an online auction—from thousands of incoming bids to a single financial settlement.
Throughout the workflow, engineers can observe:
- High-volume bid ingestion
- Regional traffic distribution
- Winner selection
- Settlement conflicts
- Retry behavior
- Financial ledger updates
Rather than focusing only on the winning bid, the platform visualizes how data changes in value as it moves through a distributed system.
Transient Traffic
Incoming bids are treated as short-lived events.
us-east-1 → $5.20
eu-west-1 → $5.30
ap-southeast-1 → $5.40
sa-east-1 → $5.35
Thousands of bids may compete for the same advertising opportunity.
Most are temporary signals.
Authoritative Settlement
Eventually only one outcome becomes permanent.
Winner = ap-southeast-1
Amount = $5.40
Only this settlement is written to the financial ledger.
How we built it
Once we identified the architectural pattern, the implementation became surprisingly straightforward.
We started with a simple question:
If only one bid becomes the final settlement, why should every bid pay the cost of globally coordinated transactions?
That question shaped the entire architecture.
Incoming bids flow into DynamoDB, where high write throughput and simple access patterns matter most.
Settlement is intentionally separated.
Only after the winning bid is determined does the transaction move into Aurora DSQL, where globally consistent transactions protect the financial record.
Instead of asking one database to solve every problem, each service is responsible for the workload it handles best.
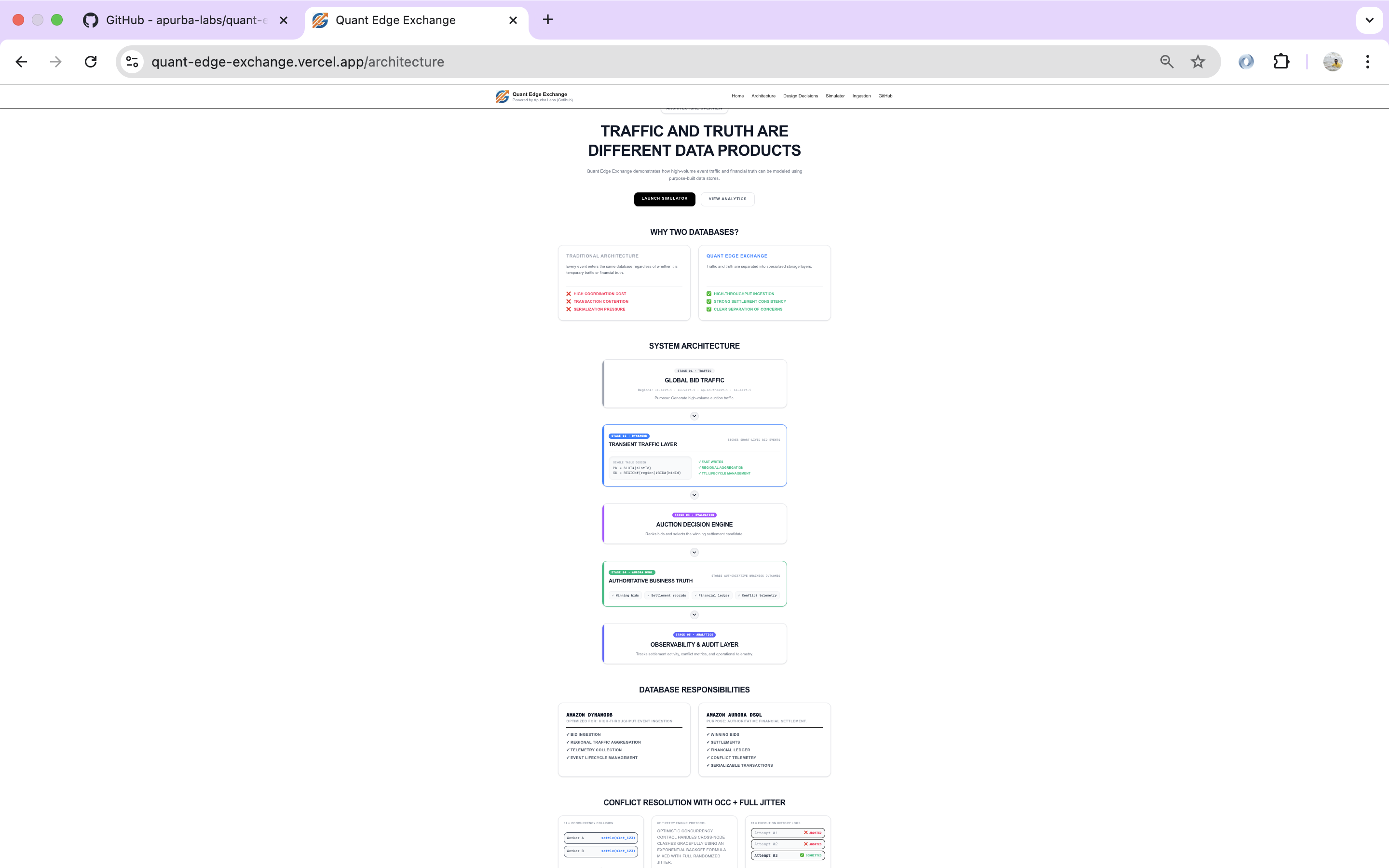
Architecture
Transient Bid Traffic
↓
DynamoDB
↓
Bid Evaluation
↓
Winning Bid
↓
Aurora DSQL
↓
OCC + Full Jitter
↓
Financial Ledger
↓
Observability
Why Two Databases?
This project isn't arguing that one database is better than another.
It's demonstrating that different workloads deserve different storage strategies.
DynamoDB absorbs massive volumes of temporary traffic using a single-table design optimized for high-throughput ingestion.
PK = SLOT#<slotId>
SK = REGION#<region>#BID#<bidId>
This enables:
- Fast event ingestion
- Regional aggregation
- Slot analytics
- Automatic cleanup with TTL
Aurora DSQL is reserved for permanent business records.
Only winning settlements cross this boundary, where globally consistent transactions protect account balances, settlement history, and financial integrity.
Why Settlement Contention Matters
The real engineering challenge begins after the auction closes.
Finding the highest bid is relatively easy.
Guaranteeing that only one worker can successfully settle that bid across a distributed system is much harder.
Aurora DSQL protects correctness through serializable transactions.
When multiple workers attempt to settle the same auction simultaneously, serialization conflicts become a normal part of distributed execution rather than an application failure.
The platform demonstrates:
- Optimistic Concurrency Control (OCC)
- Exponential Backoff
- Full Jitter Retry
Attempt #1
❌ Serialization Conflict
Attempt #2
❌ Serialization Conflict
Attempt #3
✅ Settlement Accepted
The dashboard visualizes conflict counts, retry depth, and successful recovery so engineers can observe contention instead of treating it as hidden database behavior.
Challenges we ran into
Aurora DSQL Compatibility
Coming from years of PostgreSQL development, I initially expected Aurora DSQL to behave exactly the same.
It doesn't.
Small assumptions around schema initialization, UUID generation, and deployment workflows had to be revisited. Understanding those differences became one of the most valuable parts of the project.
Modeling Realistic Contention
Generating serialization conflicts wasn't difficult.
Generating conflicts that looked like real production workloads was.
We wanted retries to demonstrate realistic distributed behavior instead of artificial benchmarks.
Deployment
Deploying a monorepo application on Vercel while integrating Aurora DSQL, DynamoDB, AWS authentication, and modern deployment workflows required careful runtime validation and production hardening.
Accomplishments that we're proud of
- Built a hybrid architecture where coordination cost matches business value.
- Demonstrated how DynamoDB and Aurora DSQL complement rather than replace each other.
- Built an observable optimistic concurrency engine with conflict telemetry.
- Designed a DynamoDB single-table ingestion model aligned with real access patterns.
- Successfully deployed the platform using AWS and Vercel.
- Created dashboards that help engineers understand distributed systems instead of simply monitoring them.
What we learned
The biggest lesson wasn't learning another AWS service.
It was changing how we think about distributed systems.
We used to ask:
"Which database should we use?"
Now we ask:
"Which data actually deserves this database?"
That small shift influenced every architectural decision in this project.
It also changed how we think about scalability.
Sometimes the biggest scalability improvement isn't making a database faster.
It's deciding that some data never needed to be there in the first place.
What's next
Future work includes:
- Aurora DSQL Change Streams
- DynamoDB Global Tables
- EventBridge-driven settlement workflows
- Multi-region failover simulations
- Multi-tenant auction isolation
- More advanced auction ranking strategies
- Chaos testing for contention-heavy workloads
Beyond additional AWS integrations, we'd like to explore something even more interesting.
Can applications automatically classify events based on business value and route them to different storage engines?
Instead of developers deciding where data belongs, could distributed systems understand the difference between temporary traffic and permanent business records?
Quant Edge Exchange started as an architecture experiment.
We believe it raises a much broader question about how future distributed systems should be designed.
Built With
- amazon-aurora-dsql
- amazon-dynamodb
- aws-sdk-v3
- docker
- next.js
- postgresql
- tailwind
- turborepo
- typescript
- vercel
Log in or sign up for Devpost to join the conversation.