-
-
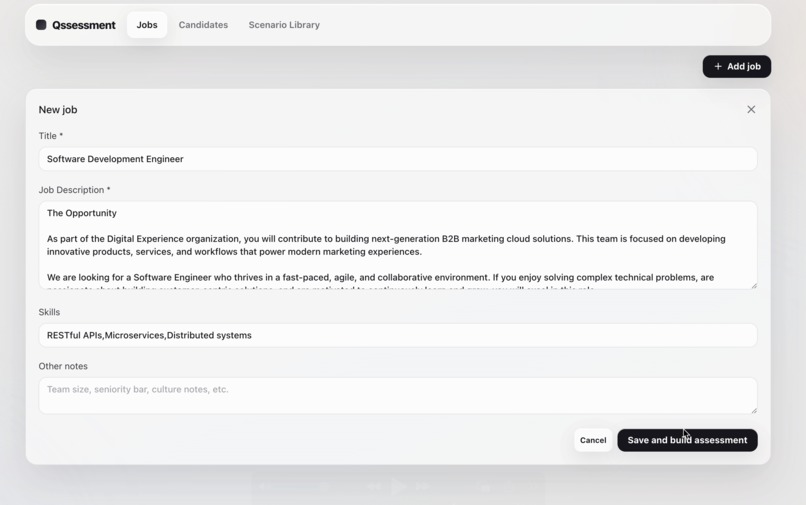
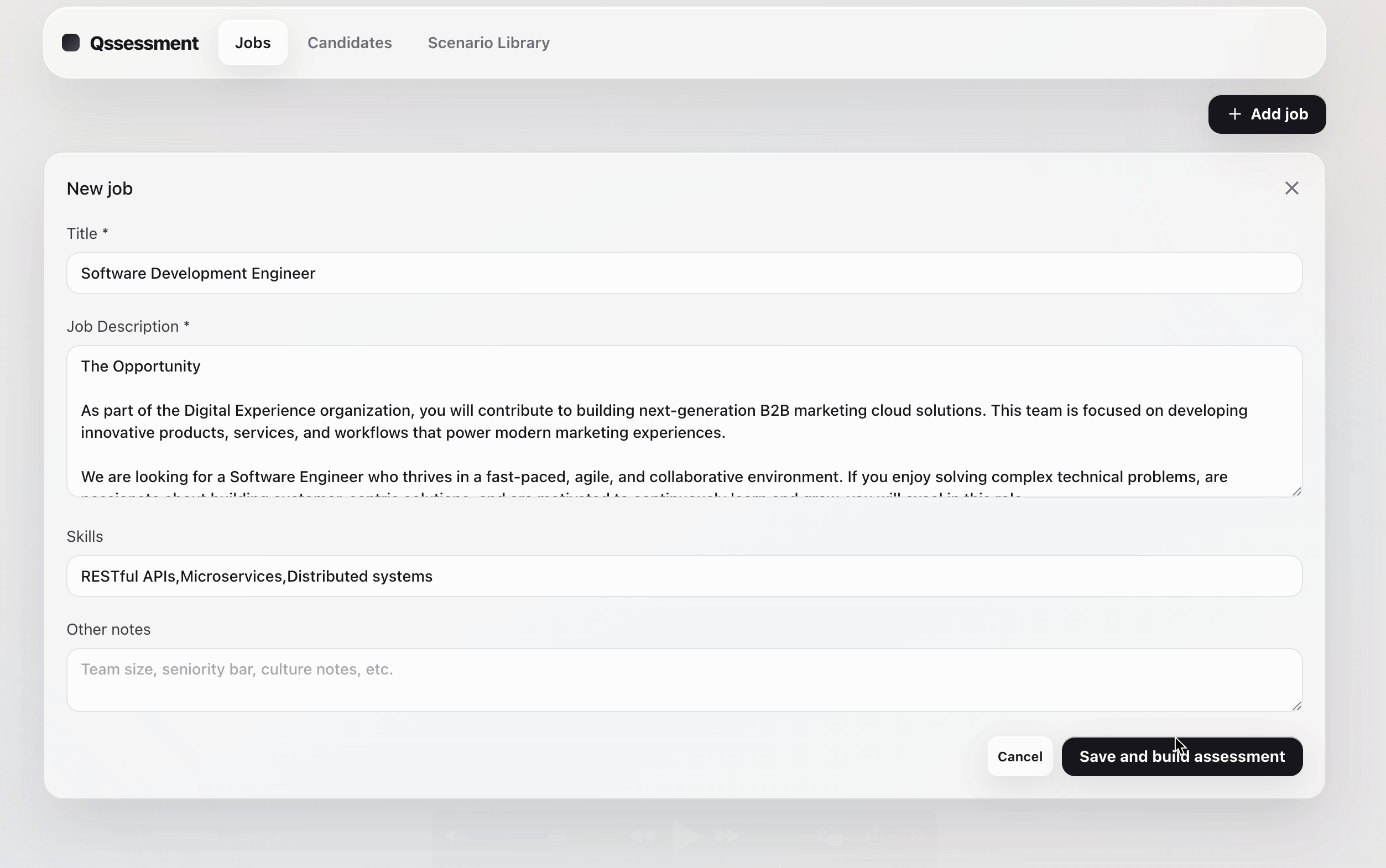
Step 1 Register Job
-
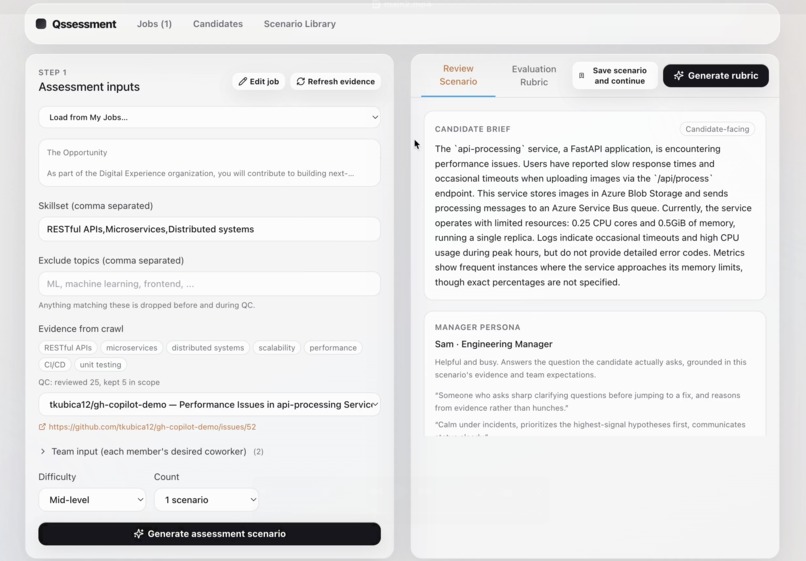
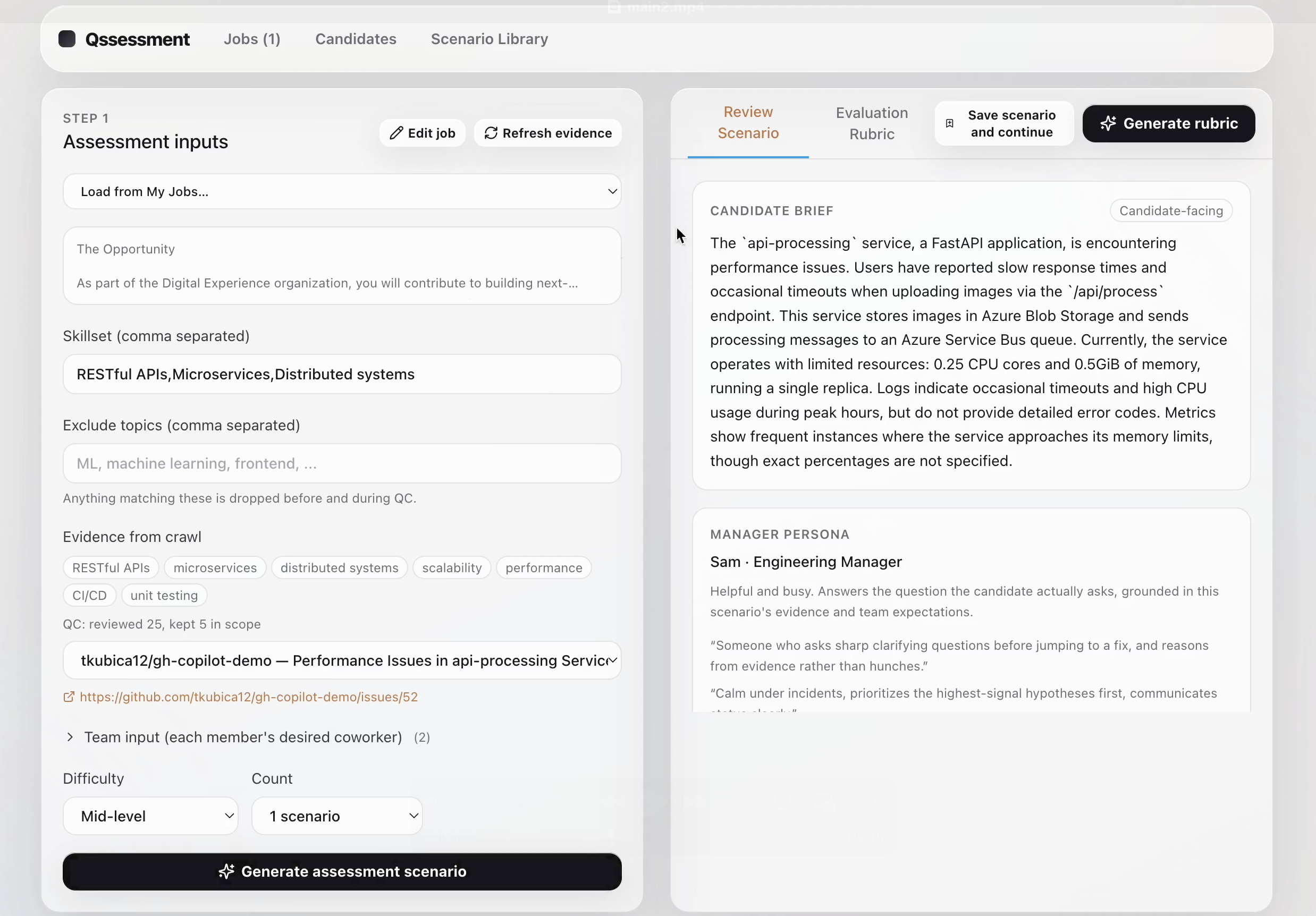
Step 2: Create Scenario
-
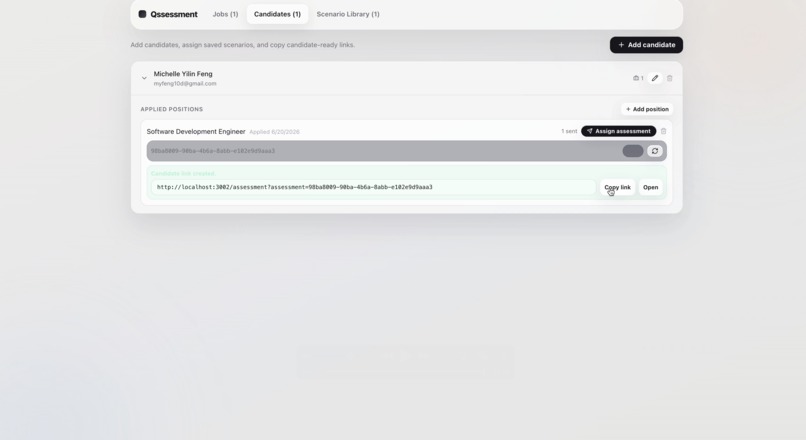
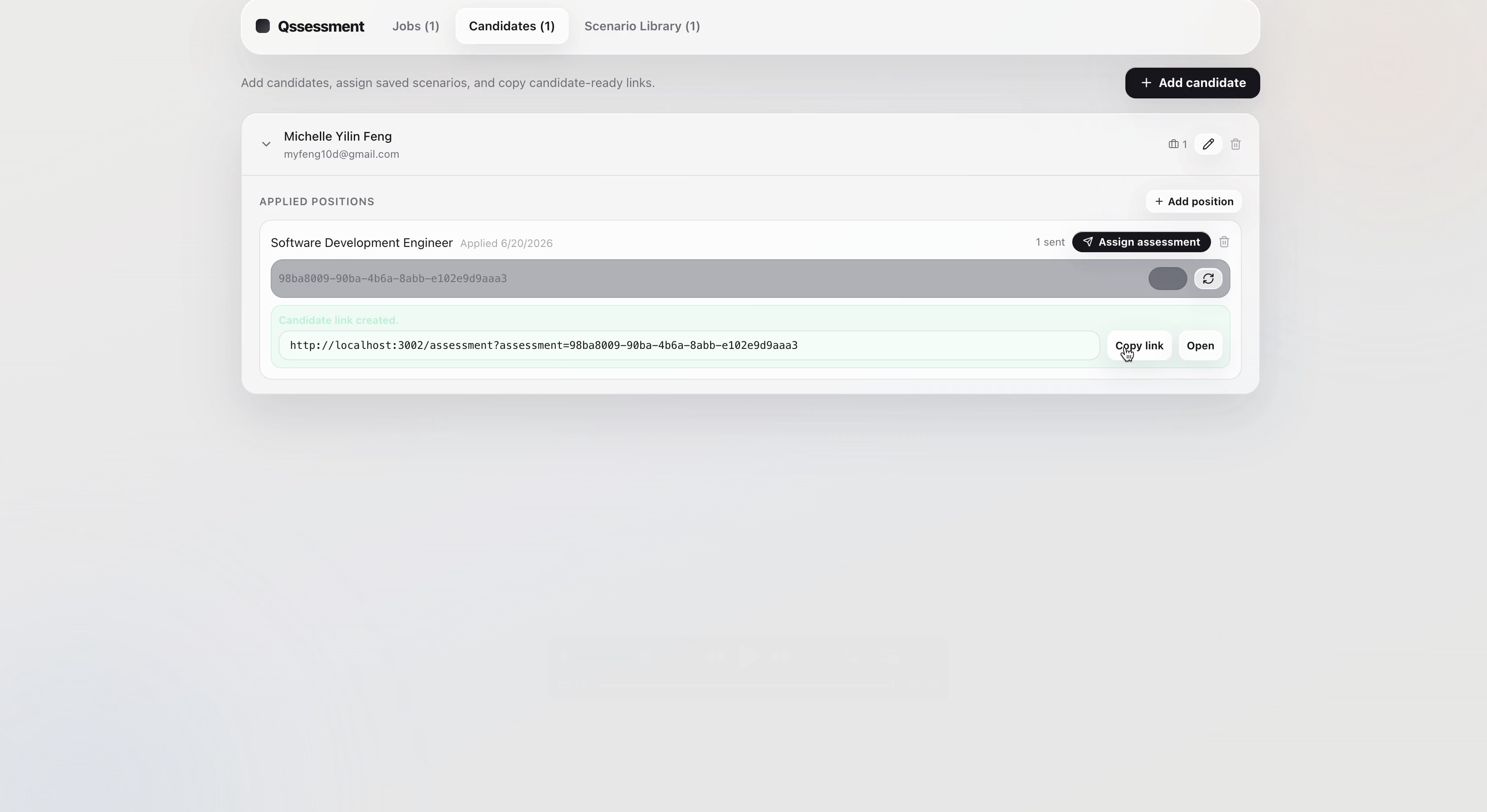
Step 3: Invite Candidate
-
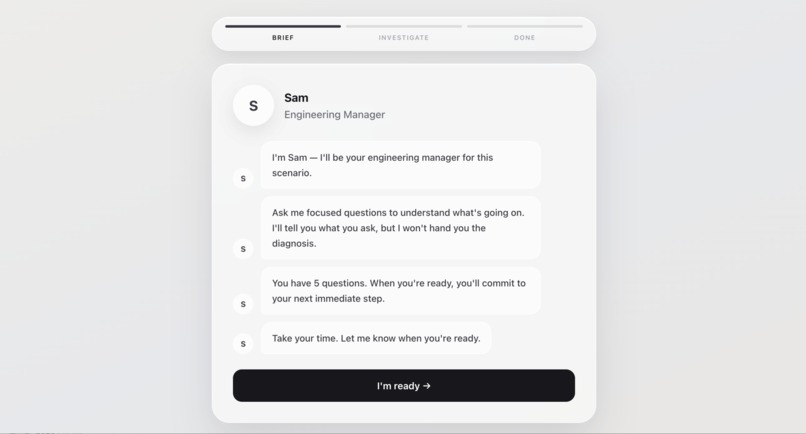
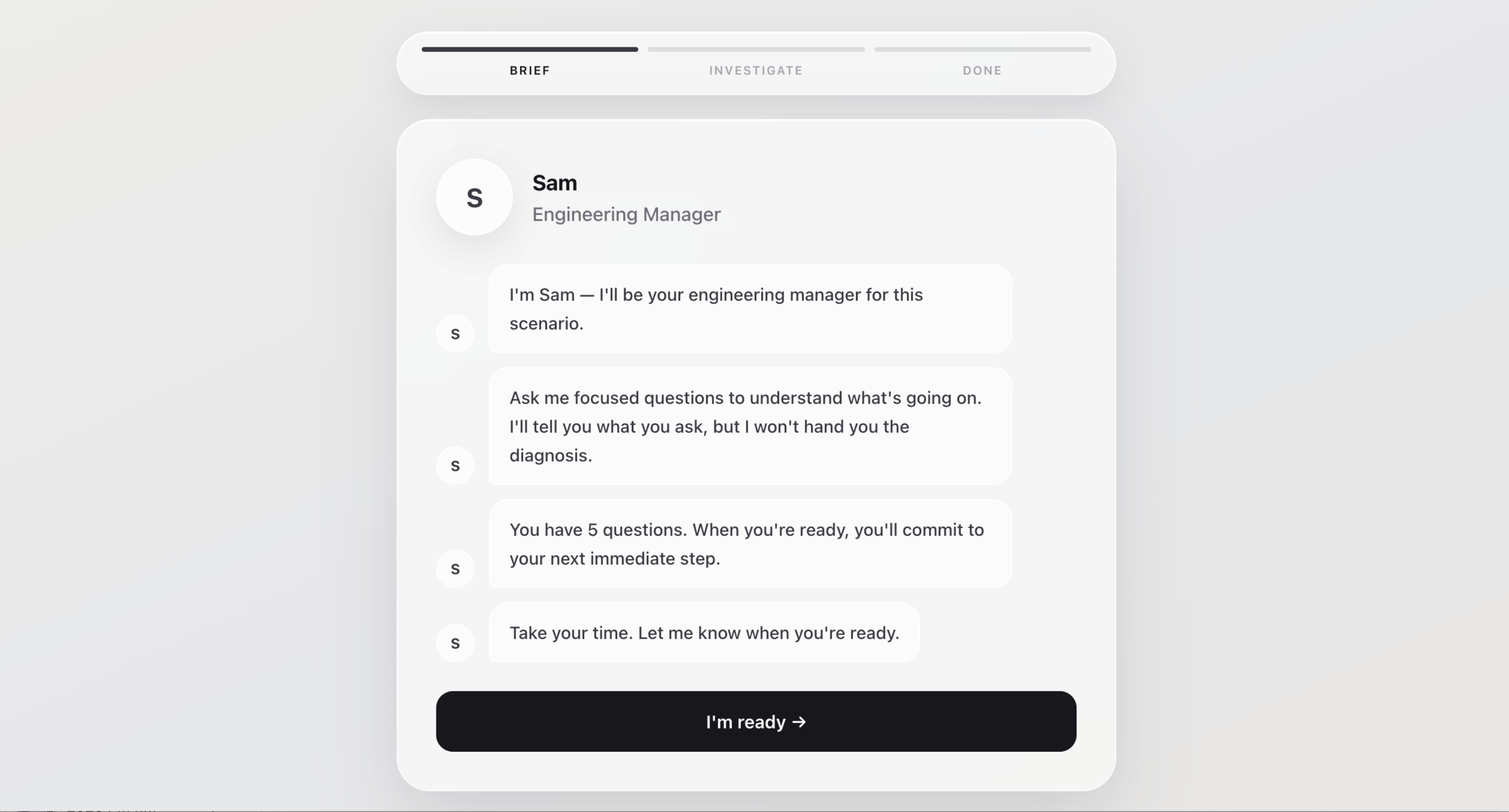
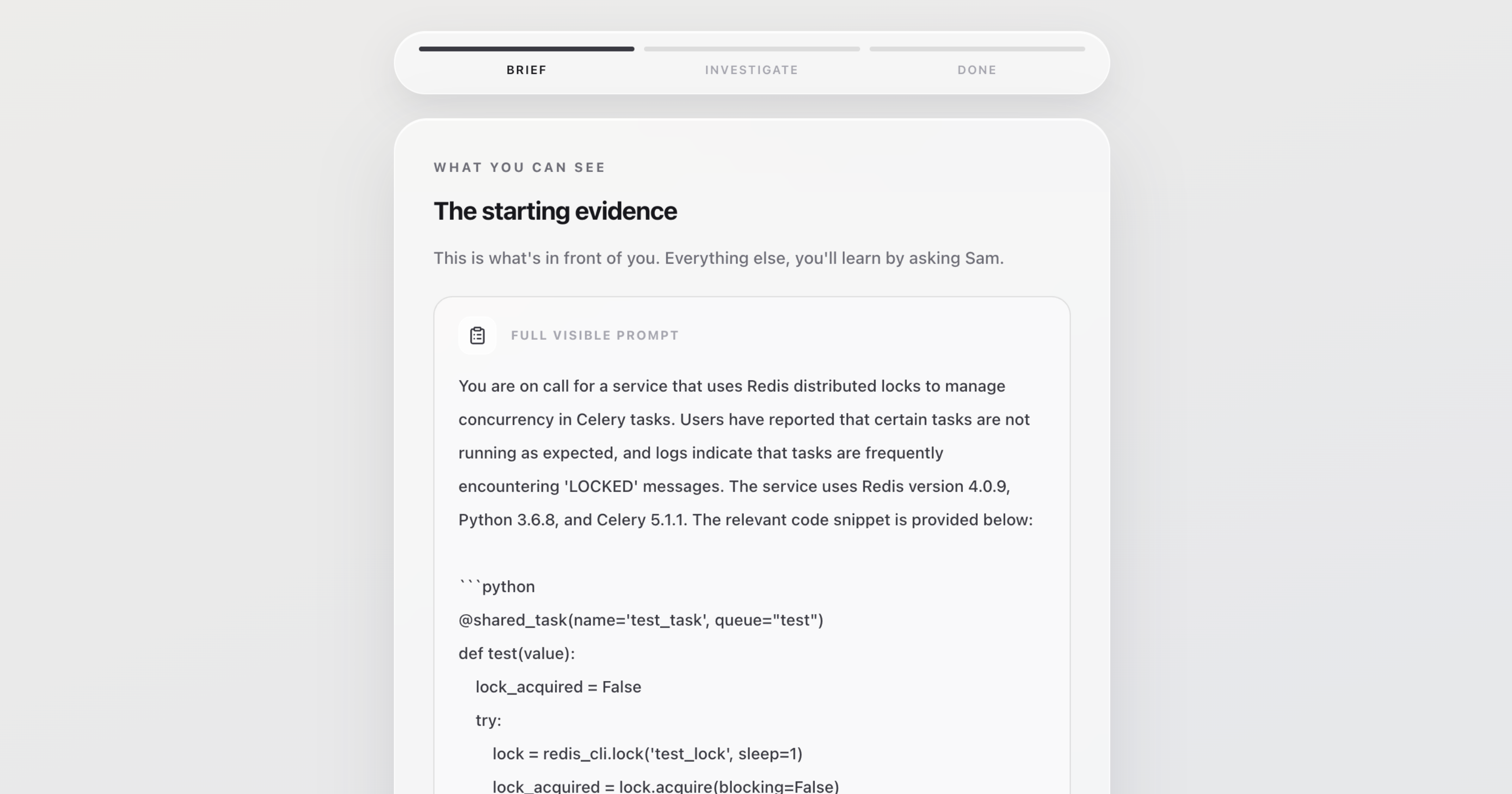
Step 4: Candidate Mock Interview (Starting Prompt)
-
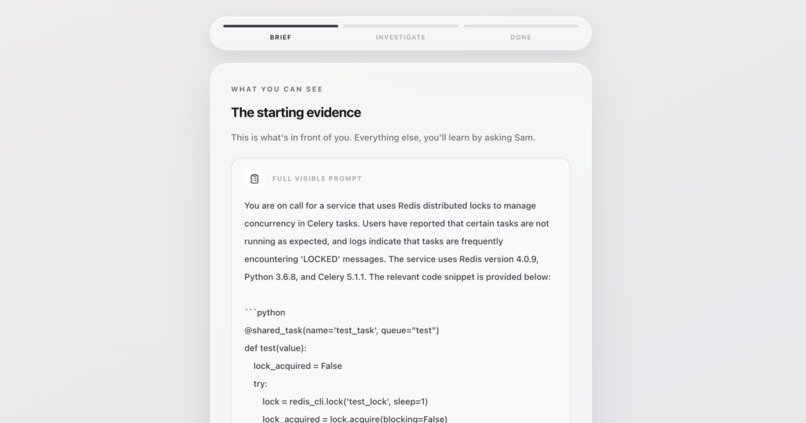
Step 4.1 Candidate Mock Interview (Scenario Briefing)
-
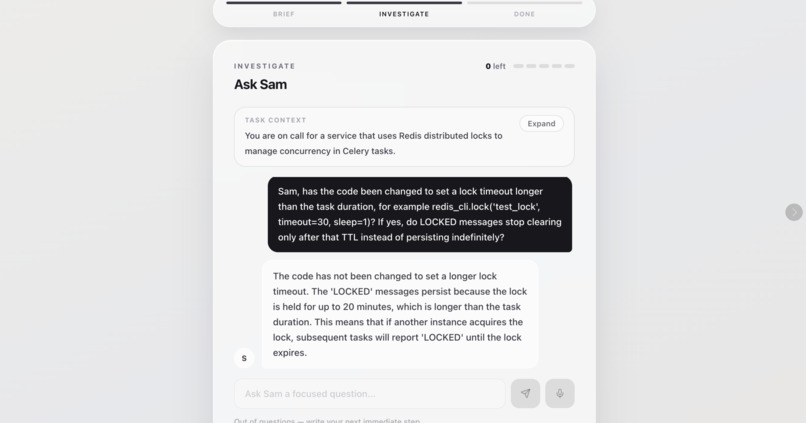
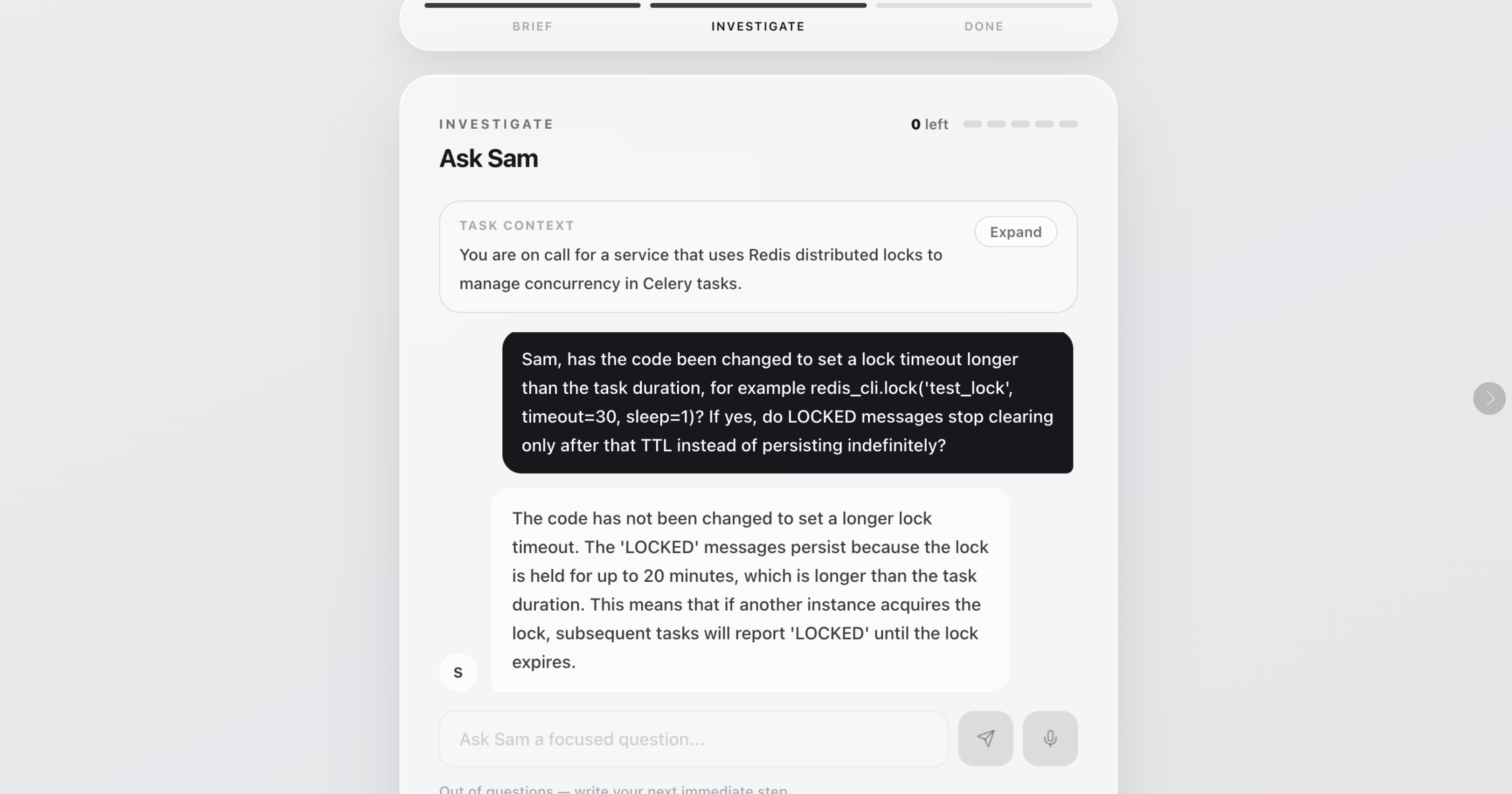
Step 4.2 Candidate Mock Interview (Q&A)
-
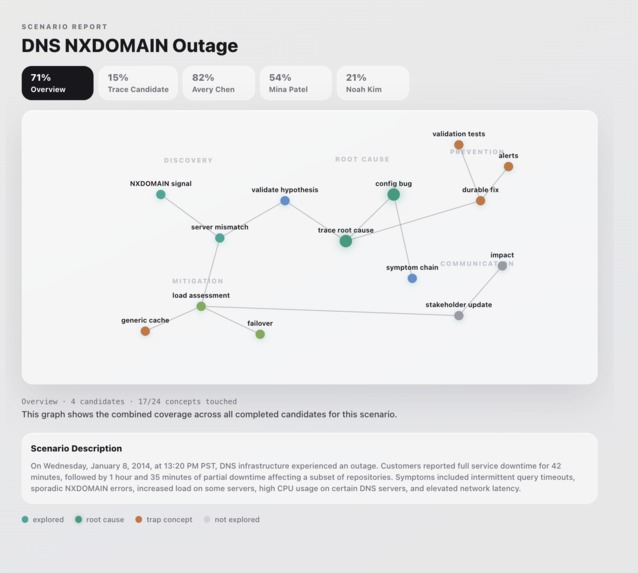
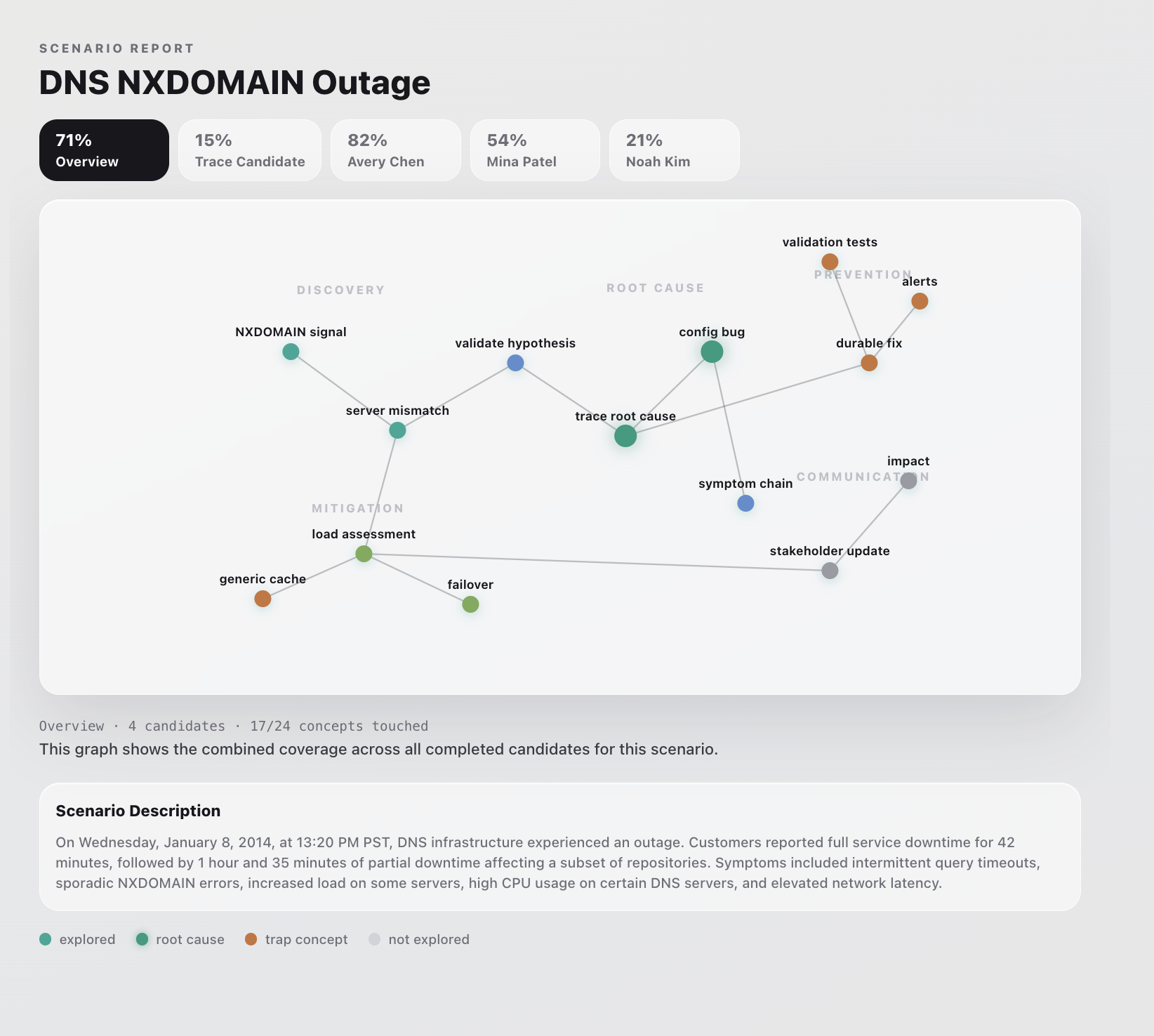
Step 5 Graph View of Candidate Skills (Overview)
-
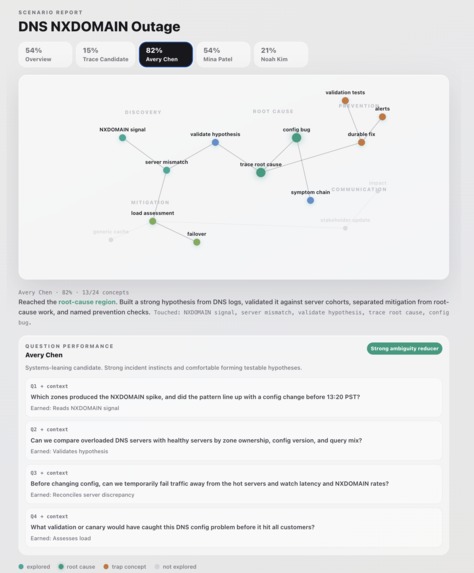
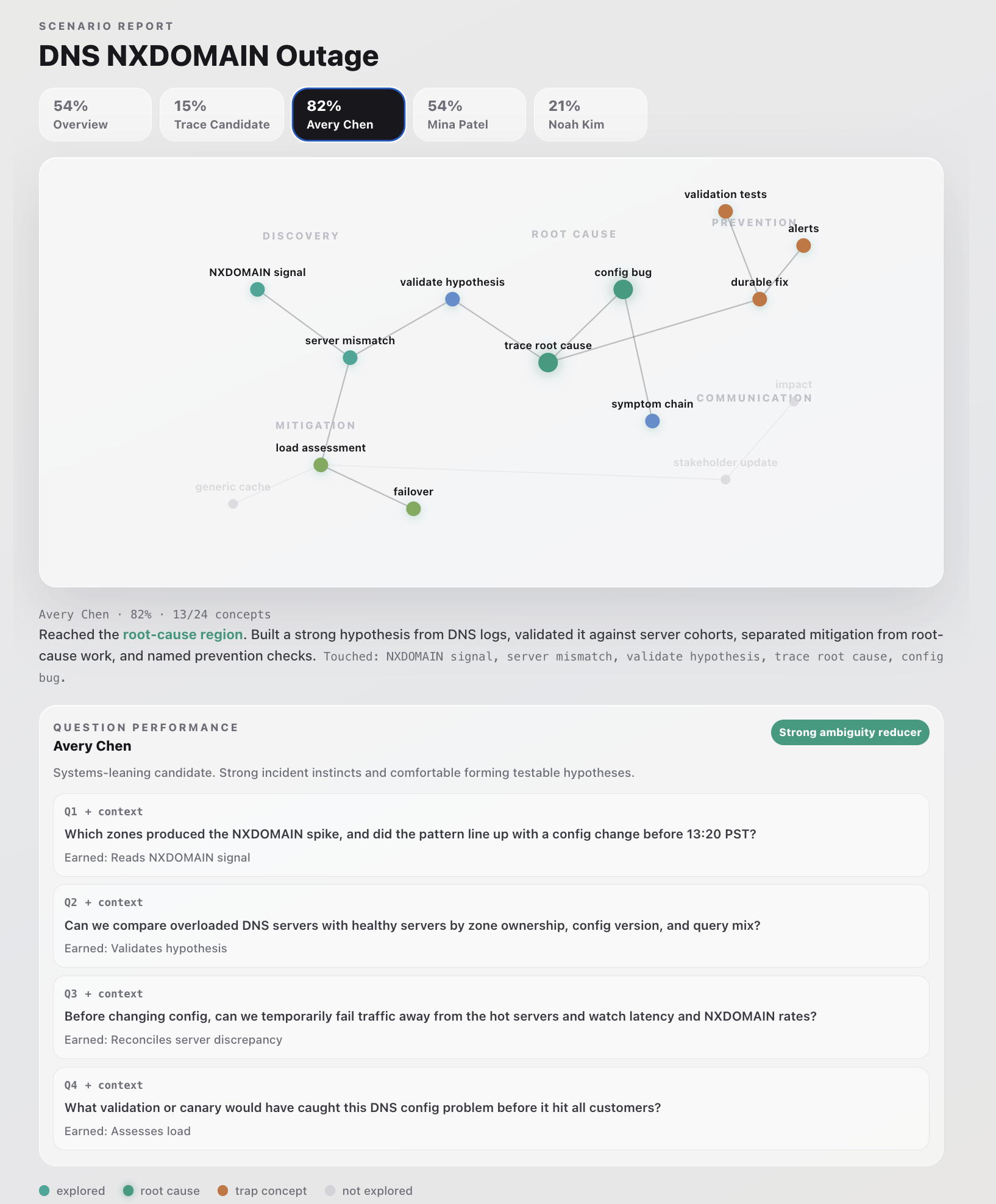
Step 5.1 Graph View of Candidate Skills (Candidate Detail)
Inspiration
Hiring managers often need to evaluate more than whether a candidate knows the right answer. In real engineering work, strong candidates ask good questions, uncover missing context, reason through ambiguity, and make judgment calls before committing to a recommendation.
We built Qssessment to help hiring teams create more realistic engineering interview simulations that test how candidates actually think in workplace situations, not just whether they can solve a static prompt.
What it does
Qssessment turns a job description into an interactive AI interview simulation.
A hiring manager enters the role, job description, required skills, excluded topics, difficulty level, and scenario count. Qssessment then crawls real engineering incidents from GitHub Issues and Stack Overflow, filters out excluded topics, and uses the remaining incidents to generate realistic workplace scenarios.
Each generated scenario is packaged into a candidate-facing brief, an AI manager persona, ambient facts, hidden decision-critical facts, an ideal recommendation, and a weighted evaluation rubric. The hiring manager reviews the generated package before sending the candidate a shareable /assessment?assessment=<uuid> link.
Candidates do not just answer a static question. They get up to 5 questions to ask the AI manager before making a recommendation. A gatekeeper decides which hidden facts each question earns. Sharp, specific questions unlock more useful context; vague or generic questions do not.
The final score is based on deterministic information gain: unlocked hidden-fact weight divided by total hidden-fact weight. An evaluator model can explain the score with a narrative breakdown, but the score itself is computed first in TypeScript.
How we built it
We built Qssessment with Next.js 14, React, TypeScript, Node.js API routes, and an OpenAI-compatible model endpoint configured through OPENAI_BASE_URL.
The system has two main stages.
First, the scenario-generation stage starts from the job description and required skills. It derives search queries, crawls GitHub Issues and Stack Overflow, applies a deterministic exclusion filter, and runs a relevance quality-control check. If too few incidents pass, it retries with refined queries up to 3 times, then falls back to a local incident corpus.
After an incident is selected, the system generates a candidate-facing scenario that withholds the root cause. A separate self-critique pass audits the draft for root-cause leakage, vague signals, weak red herrings, difficulty mismatch, grounding problems, and generic tasks. If enough issues are found, the scenario is revised once.
The critique stage creates a recursive scoring rubric. We normalize sibling weights in code so rubric weights sum cleanly at every level, instead of trusting the model output directly.
Second, the Question Arena stage turns the approved scenario into an interview simulation. The candidate asks up to 5 questions. An LLM gatekeeper classifies each question as sharp, targeted, broad, scattershot, or irrelevant, and can unlock at most 2 hidden facts per question. If the model endpoint is unavailable during the interview flow, a deterministic TypeScript fallback can classify questions using configured unlock triggers.
The AI manager only answers from gatekeeper-approved context. That means it cannot volunteer hidden facts the candidate did not earn. This keeps the interview closer to a structured simulation than an open-ended chatbot.
For evaluation, we compute the score deterministically first. The evaluator then adds a four-signal narrative breakdown covering question quality, adaptive follow-up, ownership posture, and grounded next step.
Challenges we ran into
The hardest part was balancing specificity and evaluability.
If a scenario is too open-ended, it feels realistic but becomes hard to grade. If the rubric or scenario is too rigid, it becomes easy to score but loses the nuance of real workplace situation.
We also had to separate what the candidate sees from what the manager knows. The candidate should receive enough ambiguity to ask useful questions, while the manager persona needs hidden facts, ambient facts, unlock triggers, and sample responses so the conversation stays grounded.
Another challenge was keeping LLM output bounded. We did not want generated rubrics, hidden facts, or evaluator text to silently break the assessment. We added guardrails such as deterministic exclusion filtering, rubric weight normalization, fact ID validation, capped unlocks per question, and TypeScript-first scoring.
Accomplishments that we're proud of
We are proud that Qssessment is not just a prompt wrapper. It has a full workflow: job description input, incident crawling, scenario authoring, rubric generation, candidate link sharing, an interactive manager simulation, hidden-context unlocking, and deterministic scoring.
We are also proud of the scoring design. The model can help make the interview feel natural, but the candidate's score comes from explicit hidden facts and information gain. That makes the result easier for hiring managers to inspect and defend.
What we learned
We learned that good hiring assessments are not just about answers. They are about how candidates navigate uncertainty.
A candidate's questions can reveal how they think, what assumptions they make, whether they understand the problem, and how they gather context before making decisions.
We also learned that AI interviews need strong boundaries. The agents can author the scenario and make the manager persona feel natural, but scoring should be explicit, validated, and deterministic.
What's next
Next, we want to add simulation calibration before a scenario is sent. The idea is to run simulated strong and weak candidates through the Question Arena, check whether their scores separate clearly, and adjust hidden-fact weights if the scenario does not distinguish them well enough.
We also want to improve the manager persona, support richer follow-up conversations, and make the evaluation report more useful for hiring teams comparing multiple candidates.
Technical Report https://docs.google.com/document/d/1gMYGvERJJTdn05GbtgLA0x-eoVyrBFGjMJU-Ici0eAg/edit?usp=sharing
Built With
- github-issues-api
- next.js-14
- node.js
- openai-compatible-chat-completions-api
- qwen2.5-32b
- react
- stack-overflow-/-stack-exchange-api
- tailwind-css
- typescript
- vllm-compatible-endpoint



Log in or sign up for Devpost to join the conversation.