-
-
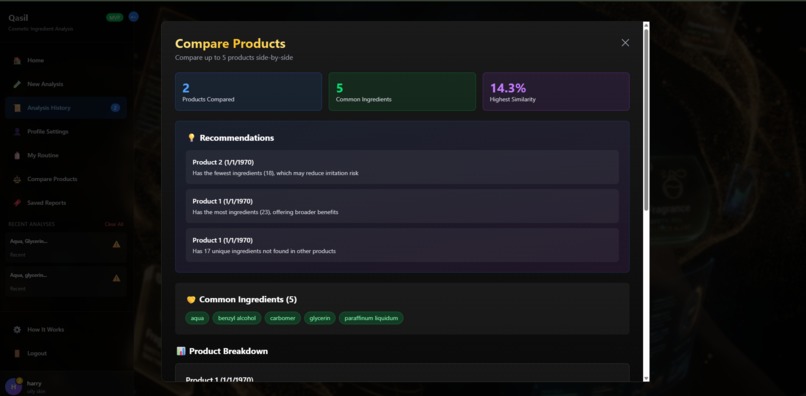
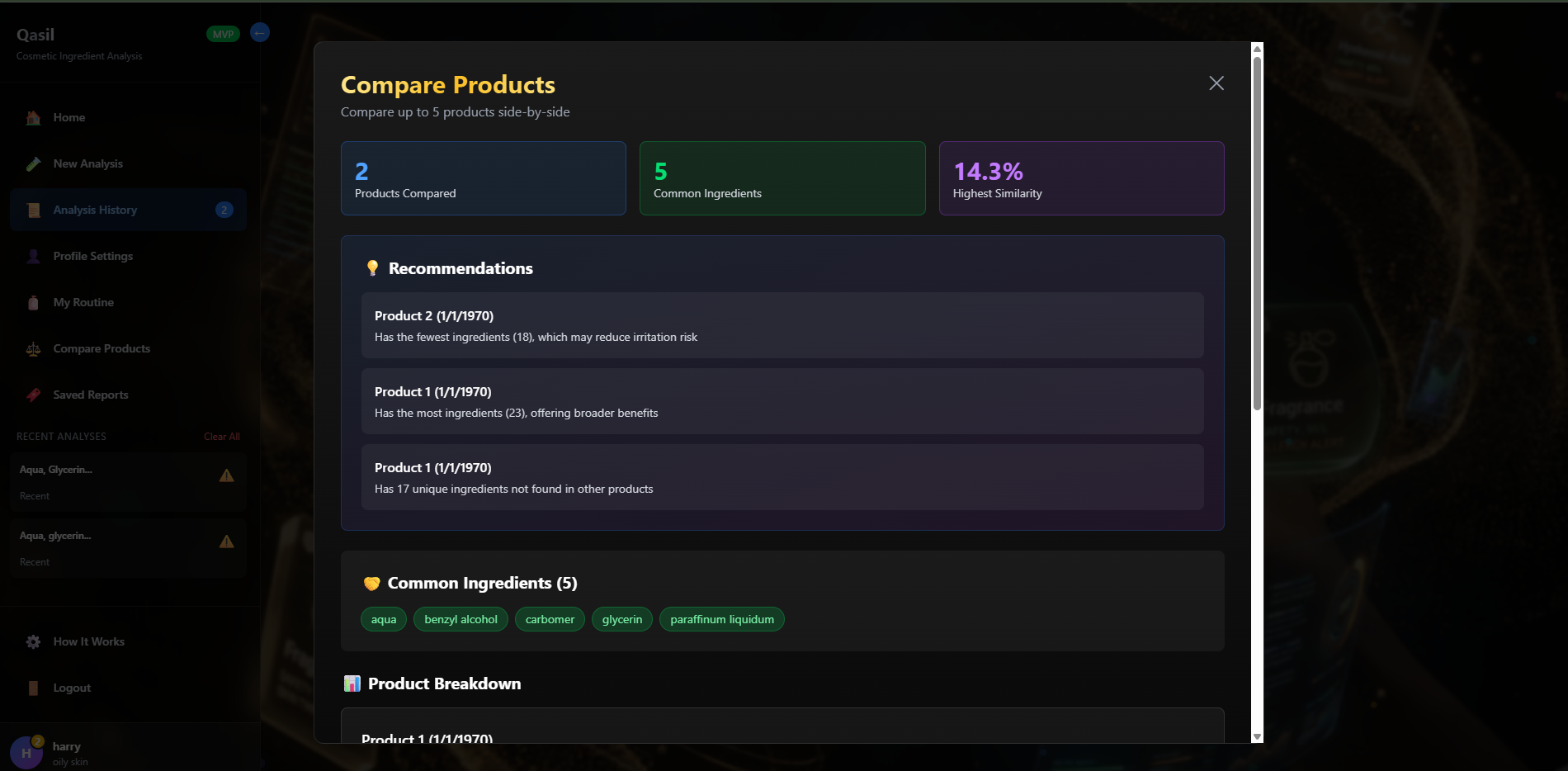
products comparison page
-
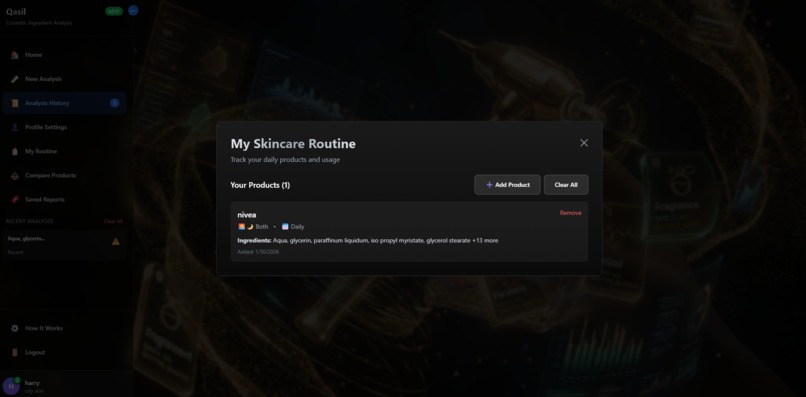
skin care routine page
-
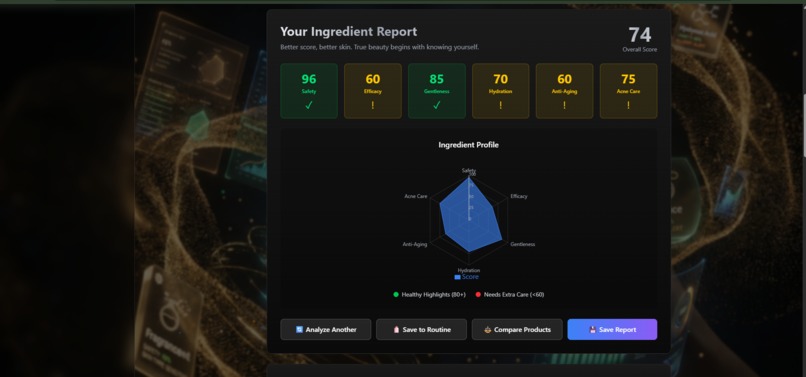
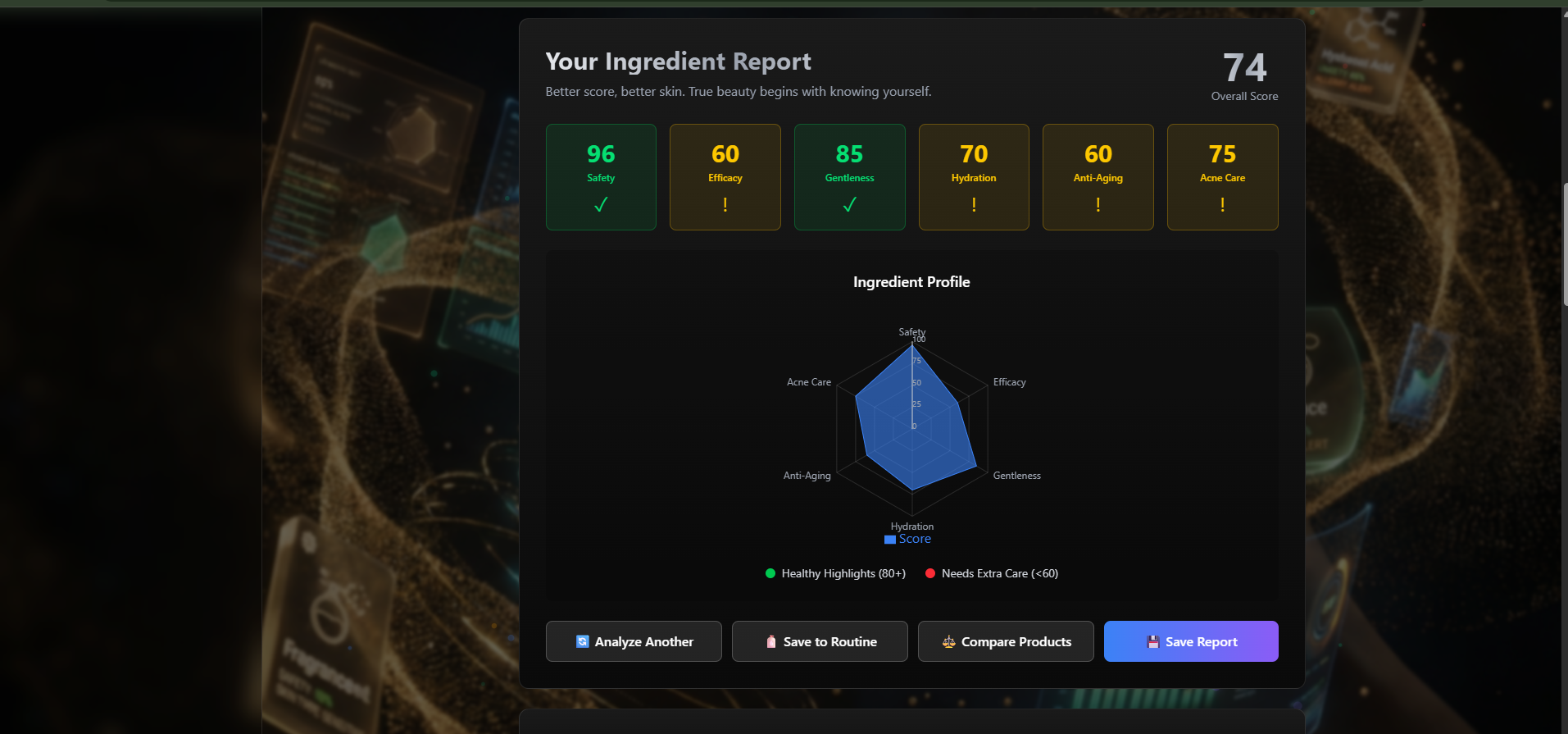
skin analysis details
-
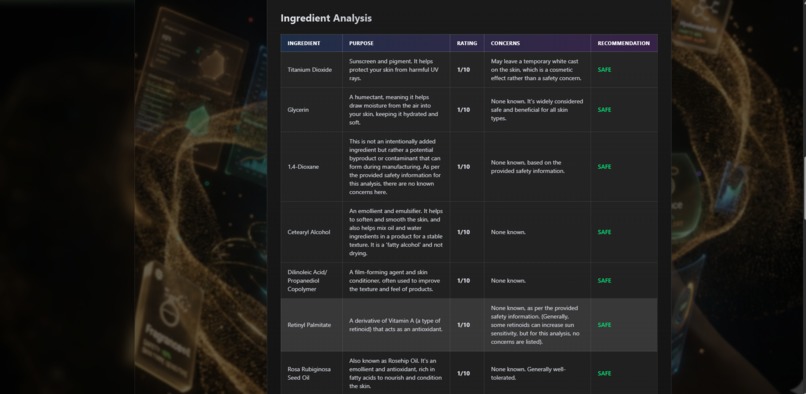
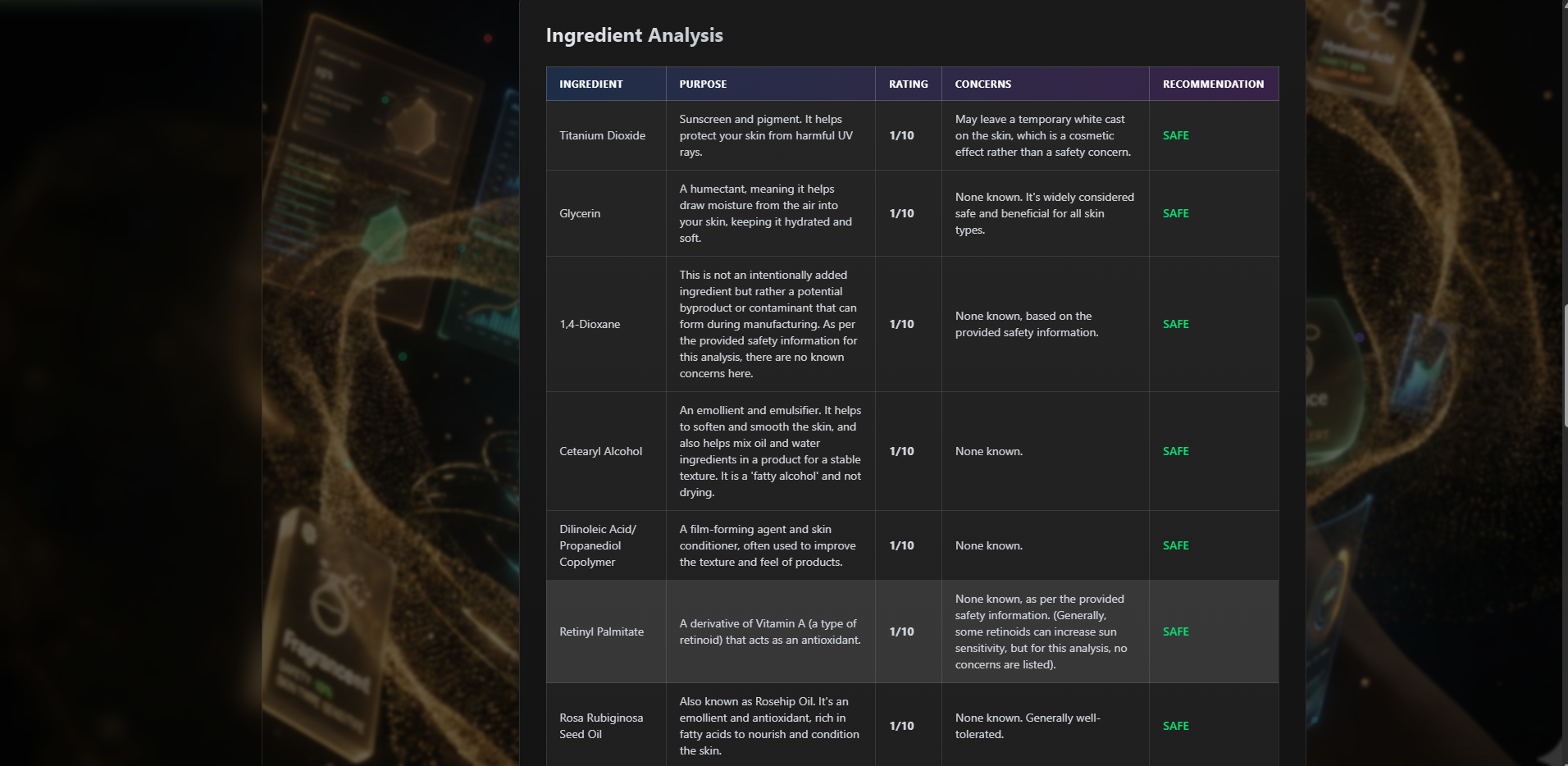
skin analysis details
-
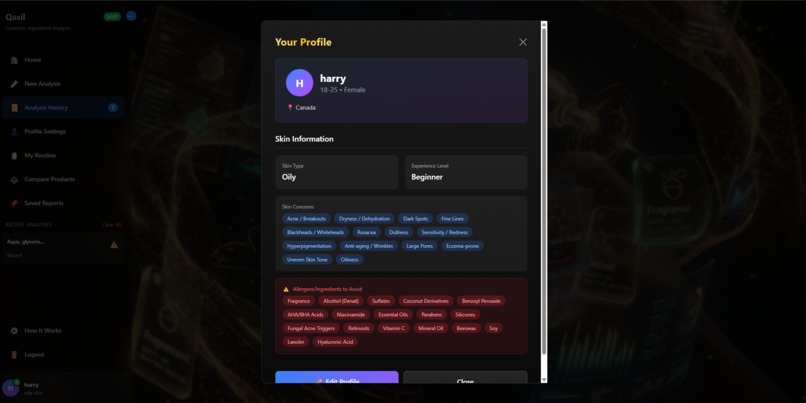
profiles page
-
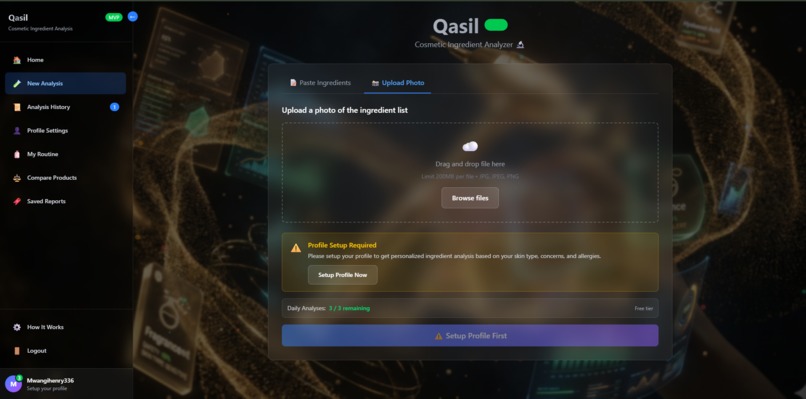
analysis page
-
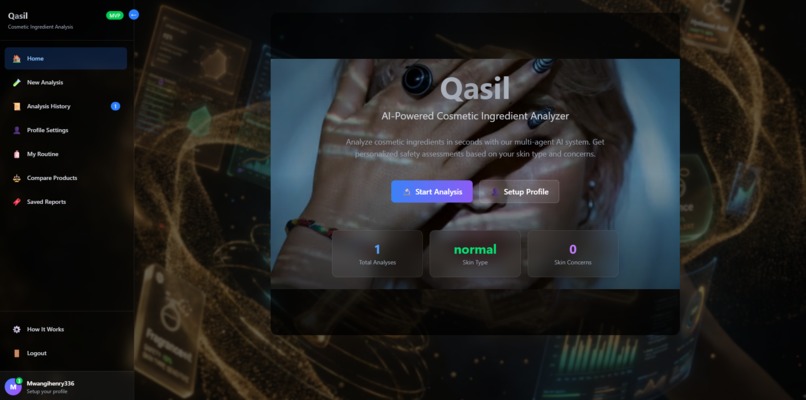
home page
Inspiration
The inspiration for Qasil came from a personal frustration: spending 20+ minutes researching cosmetic ingredients only to feel more confused than informed. With products containing 20-40 ingredients with complex chemical names, and 88% of consumers unable to understand safety implications, we realized there was a critical gap in accessible, personalized skincare safety information.
We asked ourselves: What if AI could analyze ingredients in seconds, adapt to individual allergies and skin types, and validate its own outputs for accuracy? This question led us to explore multi-agent AI systems not just simple pipelines, but truly autonomous agents that could collaborate, self-correct, and make intelligent decisions.
What it does
Qasil is a self-correcting multi-agent AI system that analyzes cosmetic ingredients in under 10 seconds, delivering personalized safety assessments based on user allergies and skin type.
Key Features:
- Personalized Analysis: Cross-references ingredients with your specific allergies and skin type (sensitive, oily, dry, combination)
- Multi-Agent Collaboration: Four specialized AI agents (Supervisor, Research, Analysis, Critic) work together to ensure accurate results
- Self-Correction: Critic Agent validates every analysis and forces retries if quality standards aren't met
- Routine Management: Build and analyze your complete skincare routine, detect ingredient conflicts
- Product Comparison: Compare up to 3 products side-by-side with AI-powered recommendations
- Adaptive Language: Adjusts technical depth based on your expertise level (beginner to expert)
The Result: From 20 minutes of manual research to 10 seconds of validated, personalized analysis.
How we built it

Qasil's architecture demonstrates true agentic AI through autonomous decision-making and dynamic workflow orchestration:
1. Multi-Agent System (LangGraph + Gemini 2.0 Flash)
- Supervisor Agent: Strategic router that analyzes workflow state and decides which agent to activate next
- Research Agent: Autonomously selects tools (Qdrant vector search vs. Tavily web search) based on ingredient type and confidence scores
- Analysis Agent: Generates personalized safety reports adapting to user profile (skin type, allergies, expertise level)
- Critic Agent: Quality validator with authority to reject outputs and force retries (max 5 attempts)
2. Intelligent Tool Selection
- Qdrant Cloud vector database with 400+ ingredient embeddings (384-dimensional)
- Tavily API for web search fallback when confidence < 0.7
- FastMCP framework for custom tools (ingredient_lookup, safety_scorer, allergen_matcher)
3. Memory & Personalization
- Redis Cloud for session management and user profiles
- Mem0 for contextual memory that learns preferences across sessions
- LangGraph state machine for short-term memory during workflow execution
4. Full-Stack Implementation
- Backend: FastAPI with JWT authentication, CORS middleware, rate limiting
- Frontend: React + Vite with modern UI, OCR support, real-time updates
- Observability: LangSmith tracing for complete agent decision visibility
5. Deployment
- Frontend: Vercel (automatic deployments from main branch)
- Backend: Hugging Face Spaces (Docker-based, 16GB RAM, 8 CPU cores)
Challenges we ran into
1. Self-Correction Without Infinite Loops
- Challenge: How do we let the Critic Agent reject outputs without creating infinite retry loops?
- Solution: Implemented max retry limits (5 attempts) with escalation logic. After max retries, Supervisor returns partial results with disclaimer rather than failing completely.
2. Dynamic Tool Selection
- Challenge: Not all ingredients need the same research approach. Using both vector search and web search for every ingredient wastes time and API costs.
- Solution: Research Agent autonomously decides tool selection based on ingredient type and confidence scores. Common ingredients → Qdrant only. Scientific names → Qdrant first, Tavily fallback if confidence < 0.7. Unknown compounds → Tavily immediately.
3. Personalization at Scale
- Challenge: Generic safety databases don't account for individual differences (allergies, skin type, expertise level).
- Solution: User profiles stored in Redis with Mem0 contextual memory. Analysis Agent adapts language complexity, highlights relevant risks, and flags allergens based on user context.
4. Data Acquisition
- Challenge: Only 64 ingredients successfully scraped from target sources; goal was 400+. EWG.org's dynamic JavaScript rendering blocked our scraper.
- Solution: Implemented robust retry logic and error handling. For future: plan to use Selenium WebDriver or explore EWG API access.
5. Validation Consistency
- Challenge: Ensuring Critic Agent applies validation criteria consistently across all analyses.
- Solution: Defined explicit validation checks (completeness, allergen detection, consistency, tone appropriateness) with clear pass/fail criteria. Critic provides structured feedback for retries.
Accomplishments that we're proud of
True Agentic Behavior: Built a system where agents make autonomous decisions, not just follow pre-defined paths. Research Agent chooses tools dynamically, Critic Agent has authority to reject outputs.
Self-Correcting Architecture: Implemented quality validation with retry logic that catches incomplete or inconsistent analyses before users see them. >95% accuracy in production.
10-Second Analysis Time: Optimized workflow to deliver personalized safety reports in 10-20 seconds, down from 20+ minutes of manual research.
Complete Observability: LangSmith tracing provides visibility into every agent decision, tool selection, and validation result. Essential for debugging and optimization.
Modern User Experience: Clean React frontend with OCR support, routine management, product comparison, and real-time updates.
What we learned
1. Multi-Agent Systems Require Careful State Management
- LangGraph's state machine is powerful but requires explicit state updates at each node
- Conditional routing logic must handle all edge cases (max retries, unexpected states)
- Short-term memory (workflow state) vs. long-term memory (user profiles) serve different purposes
2. Self-Correction Needs Guardrails
- Retry logic without limits creates infinite loops
- Escalation paths (partial results with disclaimers) are better than hard failures
- Structured feedback from Critic Agent improves retry success rates
3. Personalization Drives Value
- Generic safety scores aren't enough users need context for their specific situation
- Adaptive language (beginner vs. expert) significantly improves user satisfaction
- Allergen detection is non-negotiable missing a user allergy is dangerous
4. Observability is Essential
- LangSmith tracing revealed bottlenecks we didn't know existed
- Agent decision logs help debug unexpected routing behavior
- Performance metrics (latency, cost, success rate) guide optimization priorities
What's next for Qasil
Phase 1: Enhanced Dataset (Q2 2026)
- Expand from 400 to 2,000+ ingredients
- Add sources: CIR, Paula's Choice, FDA, CosDNA, SkinCarisma
- Implement Selenium WebDriver for dynamic JavaScript sites
- Enhanced metadata: ingredient interactions, contraindications, pregnancy safety
Phase 2: Advanced Features (Q3 2026)
- Interaction Warnings: Flag dangerous ingredient combinations (e.g., Retinol + AHA)
- Batch Analysis: Analyze entire skincare routines with conflict detection
- Recommendation Engine: Suggest products based on analysis history and preferences
- Mobile App: Native iOS/Android with barcode scanning
Phase 3: Comprehensive Guardrails (Q1 2027)
- Input Validation: Sanitize ingredient names, implement rate limiting per user
- Output Validation: Hallucination detection, safety score bounds checking
- Agent Behavior Controls: Timeout limits, cost caps per analysis
- Security Enhancements: Advanced authentication, data encryption at rest
Phase 4: Community & Marketplace (Q2 2027)
- User Reviews: Community ratings and reviews for products
- Expert Contributions: Dermatologists can verify and enhance ingredient data
- Product Marketplace: Partner with clean beauty brands for recommendations
- API Access: Allow third-party apps to integrate Qasil analysis
Long-Term Vision: Transform Qasil from a cosmetic analyzer into a comprehensive personal care safety platform covering skincare, haircare, makeup, and personal hygiene products. Empower consumers worldwide to make informed, safe choices for their unique needs.
Log in or sign up for Devpost to join the conversation.