-

Q-buster agent Logo
-
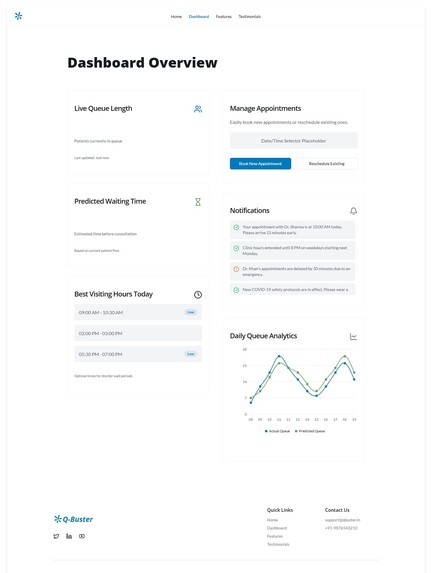
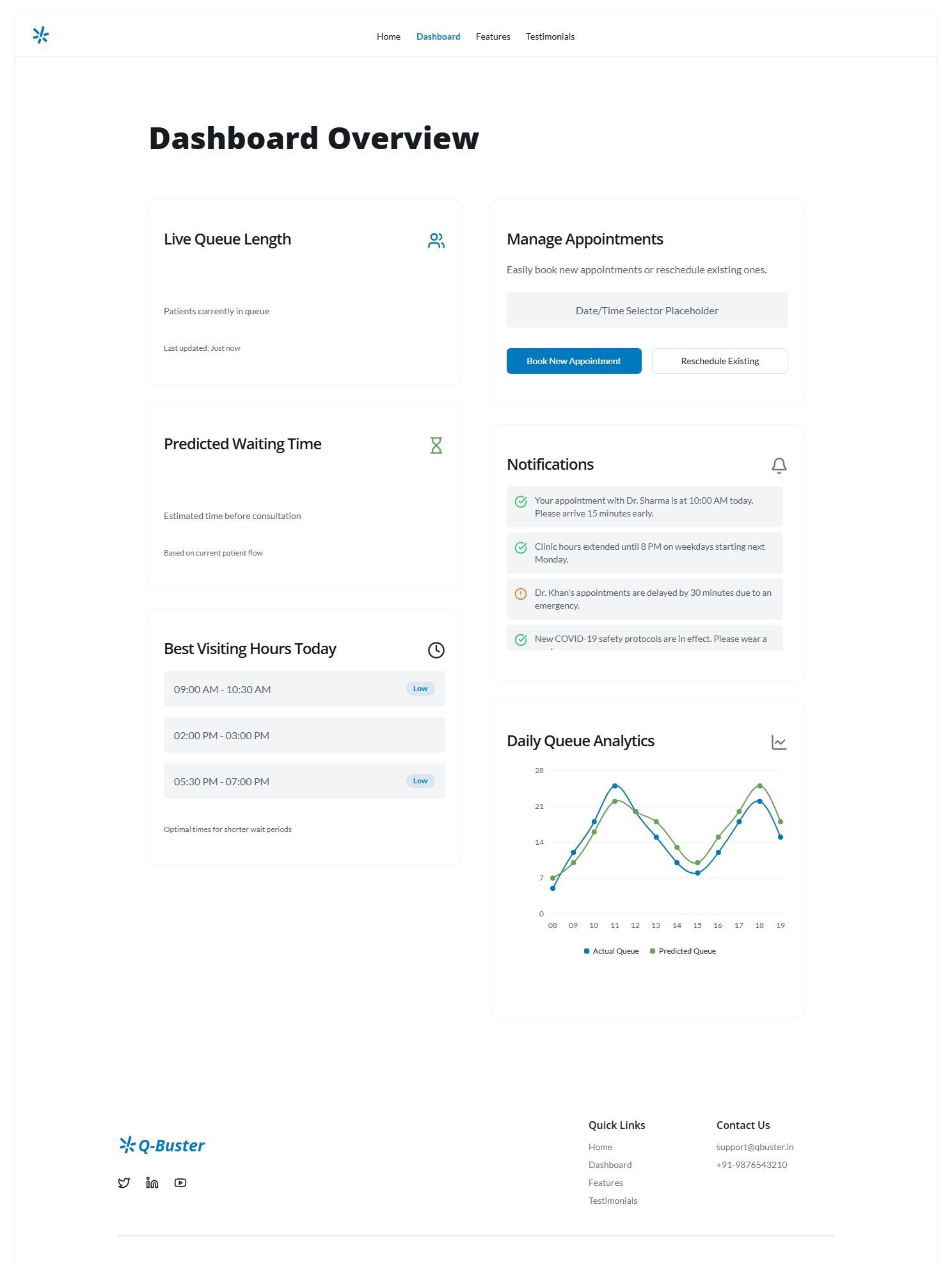
Dashboard
-
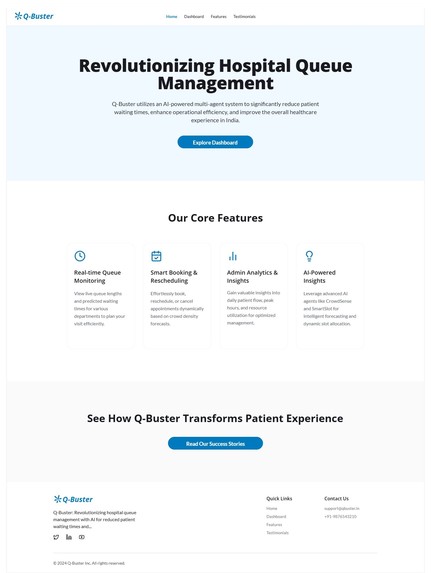
Home Page
-
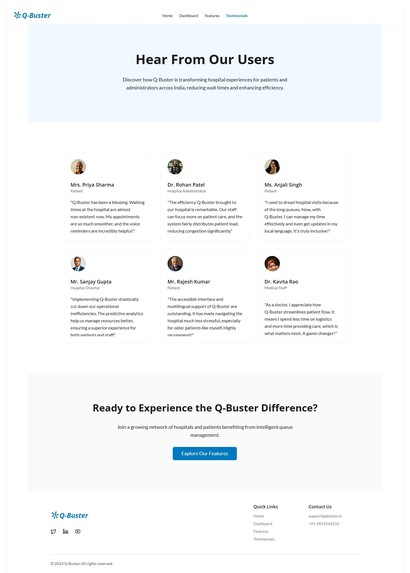
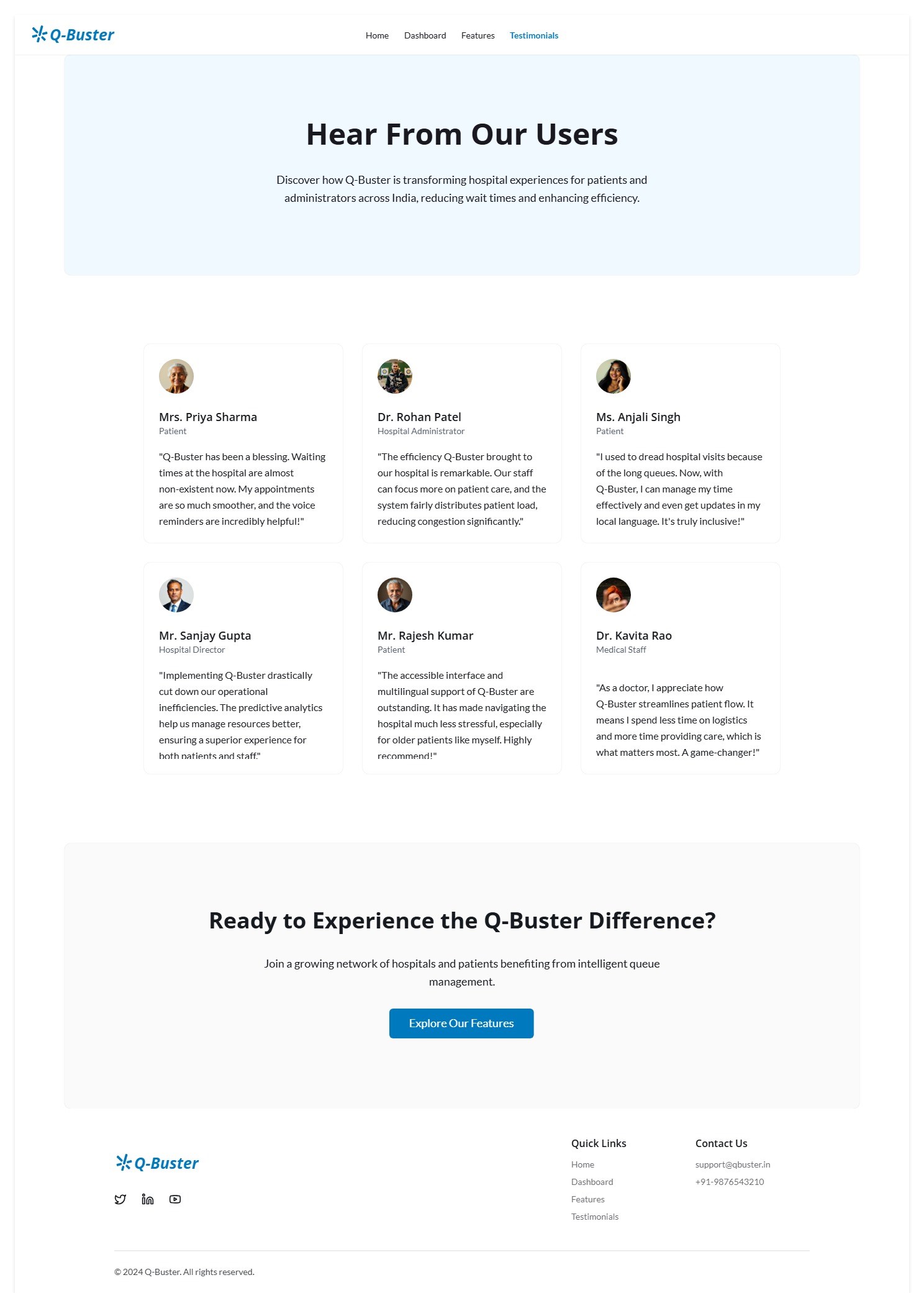
Testimonials
-

Features
-
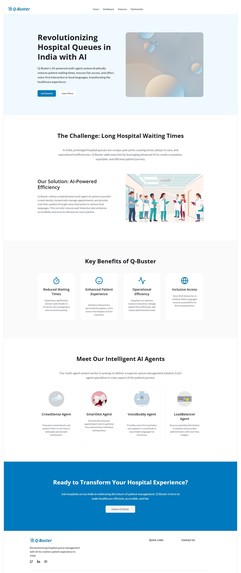
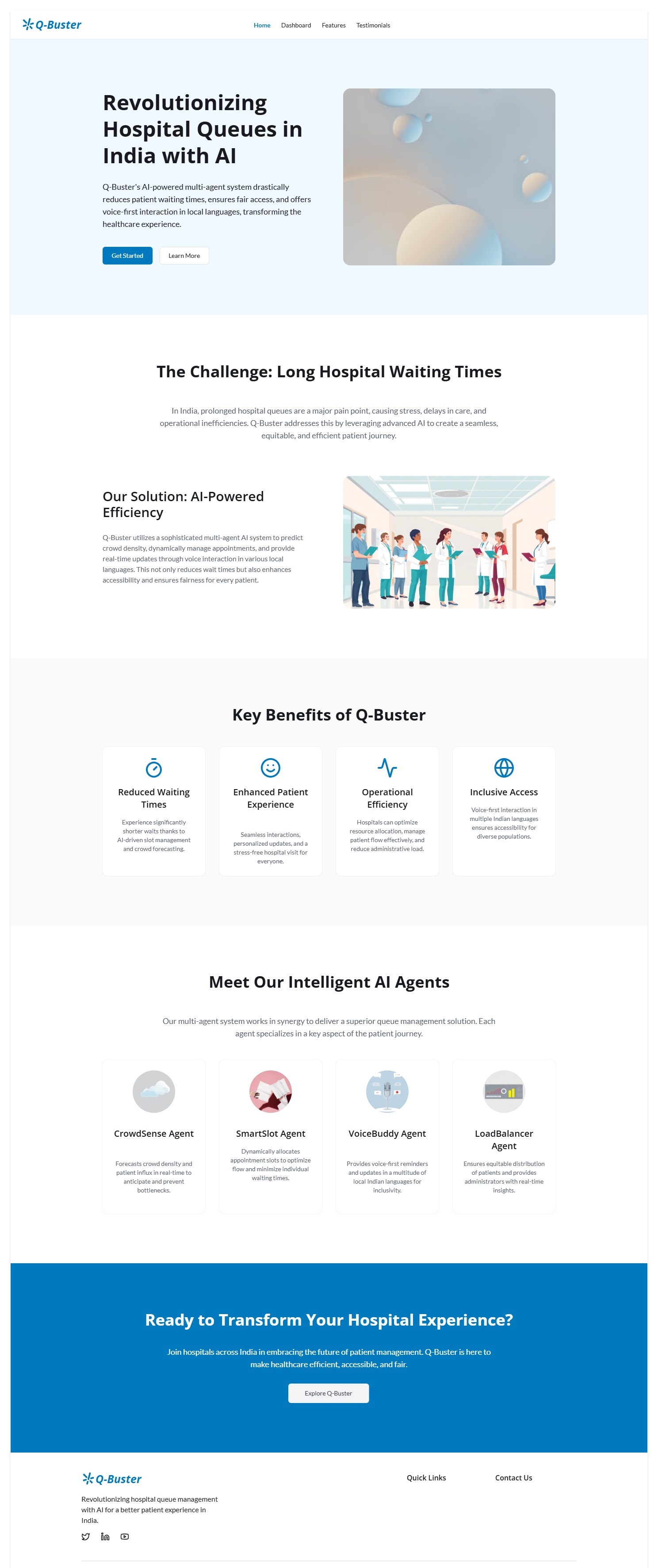
Landing Page


About the Project: Q-Buster Agent
Inspiration
In India, queues are everywhere - hospitals, RTOs, temples, ration shops, and even at passport offices.
On average, an Indian spends months of their life just waiting in line.
We felt this daily frustration ourselves and wanted to ask:
“Can AI save people from wasting hours in queues?”
That question inspired us to build Q-Buster Agent - an AI system that predicts queues, manages bookings, and guides people in local languages.
What We Learned
While building this project, we learned:
How queueing theory works:
- ( \lambda ) = arrival rate
- ( \mu ) = service rate
- Waiting time depends on ( \frac{\lambda}{\mu} ).
- ( \lambda ) = arrival rate
How to clean and use real-world queue datasets like:
- Queue Waiting Time Dataset (IEEE DataPort) - structured queue logs with arrival/service times.
- Hospital Wait Time Dataset (GitHub) - real-world OPD waiting durations.
- Eye Smart EMR Outpatient Visit Data (India) - 3M+ visit records from an Indian hospital chain, capturing temporal footfall trends.
- Queue Waiting Time Dataset (IEEE DataPort) - structured queue logs with arrival/service times.
How IBM’s Granite Models + Time Series Foundation Models (TSFM) can forecast demand surges.
How to build multi-agent workflows with IBM’s Agent Development Kit (ADK).
How We Built It
We combined IBM’s open-source tech assets with real-world queue datasets (Kaggle, IEEE DataPort, GitHub, and medical repositories) to simulate and forecast Indian queue behavior:
Data Preparation
- Data preprocessing & pipelines -> Used IBM’s toolkits to clean and transform queue data (arrival times, service start/end, waiting times, queue lengths).
- Cleaned hospital logs (ER wait times, appointments, EyeSmart OPD visits).
- Converted them into time-series for forecasting.
- Tools: IBM preprocessing toolkits.
- Data preprocessing & pipelines -> Used IBM’s toolkits to clean and transform queue data (arrival times, service start/end, waiting times, queue lengths).
Prediction Models
- Trained Granite + TSFM models to predict crowd density, average waiting time, and no-shows.
- Example: If OPD gets 200 patients/day, our model predicts peak hours and waiting time distribution.
- Trained Granite + TSFM models to predict crowd density, average waiting time, and no-shows.
Agents (using IBM ADK)
- CrowdSense Agent -> predicts crowd levels from historical + real data.
- SmartSlot Agent -> dynamically allocates or reallocates bookings when last-minute cancellations or missed appointments occur.
- VoiceBuddy Agent -> sends voice/SMS reminders in local languages.
- LoadBalancer Agent -> gives administrators live dashboards & suggestions.
- CrowdSense Agent -> predicts crowd levels from historical + real data.
Challenges We Ran Into
- Data diversity -> Queue behavior differs by place. We solved this by combining multiple datasets.
- Local language support -> Many citizens are not comfortable with English apps, so we built voice reminders in Indian languages.
- Scalability -> Training on large datasets (like EyeSmart EMR) was heavy. We optimized using IBM’s efficient preprocessing and fine-tuning tools.
- Fairness -> Ensuring slots are allocated fairly without bias toward early-bookers or those with faster internet. We tested fairness benchmarks with IBM tools.
Impact
- Citizens -> Save hours of waiting, reduced stress.
- Hospitals & Gov. offices -> Better management, smoother operations.
- Rural inclusion -> Voice-first reminders make it accessible to everyone.
- Society -> Greater fairness, fewer bribes/agents needed.
In short:
Q-Buster Agent turns India’s biggest daily annoyance, queues, into an opportunity for AI-driven efficiency, fairness, and inclusion.
Accomplishments That We’re Proud Of
- We turned a very common Indian frustration (long queues) into a working AI agent solution.
- We managed to use real Indian datasets (Data.gov.in) instead of just synthetic data.
- Built a multi-agent workflow (CrowdSense, SmartSlot, VoiceBuddy, LoadBalancer) using IBM ADK that actually simulates how queues can be predicted and reduced.
What We Learned
- How to clean and process messy public datasets from India (hospital OPDs and more).
- The basics of queueing theory, which helps explain why waiting times shoot up when demand is high.
- How to use IBM’s Time Series Foundation Models (TSFM) and ADK to build an agent system.
- The importance of inclusivity in tech -> reminders in multiple Indian languages, SMS/voice for rural users, not just fancy apps.
What’s Next for Q-Buster
- Expand from hospitals to RTOs, temples, ration shops, mandis- anywhere queues waste people’s time.
- Add AI-powered fairness checks -> ensuring equal access regardless of privilege or digital skills.
- Open up an API for admins so hospitals, temples, or govt offices can plug Q-Buster into their existing systems.


Log in or sign up for Devpost to join the conversation.