-
-

PyTuna!
-
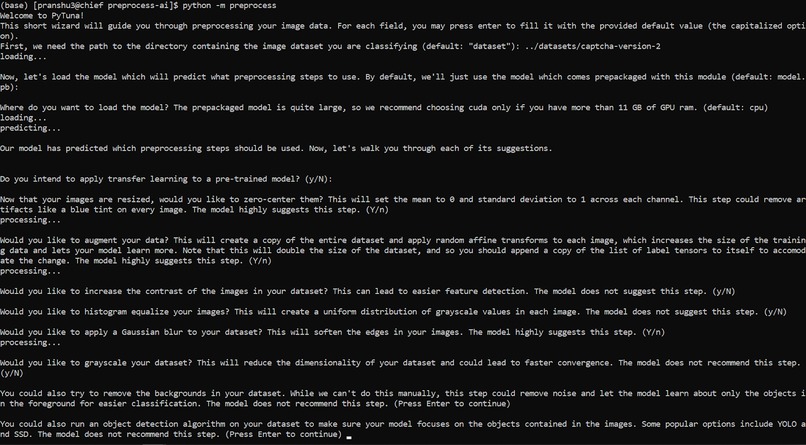
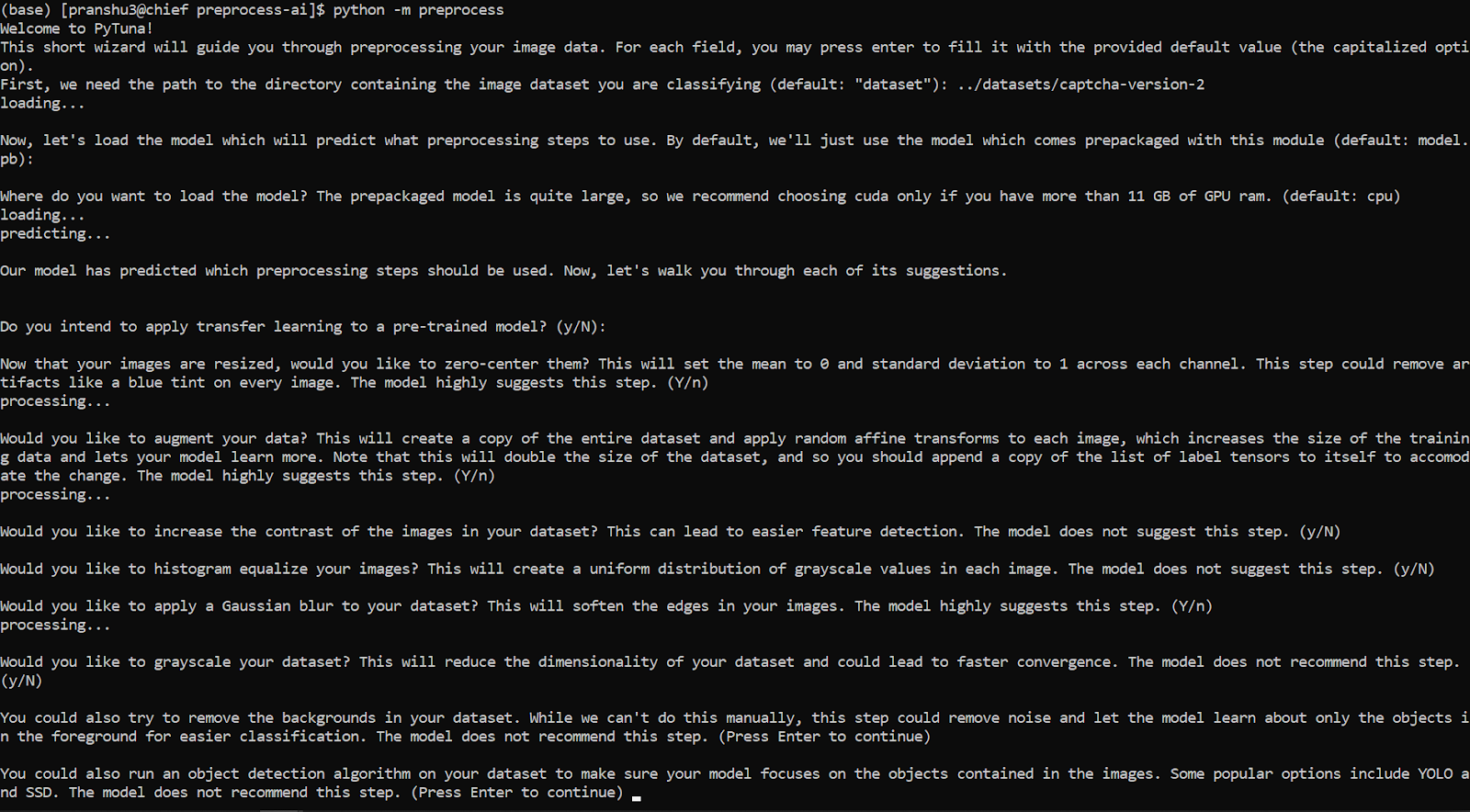
A screenshot of the PyTuna CLI wizard in action, guiding a user through preprocessing
-
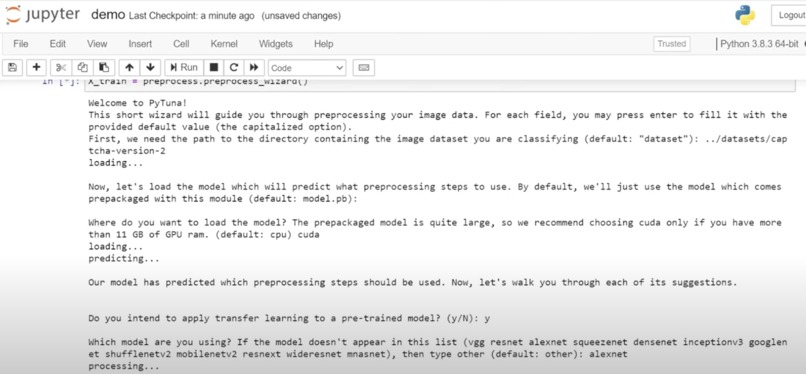
A screenshot of the PyTuna Jupyter Notebook wizard in action, guiding a user through preprocessing
-
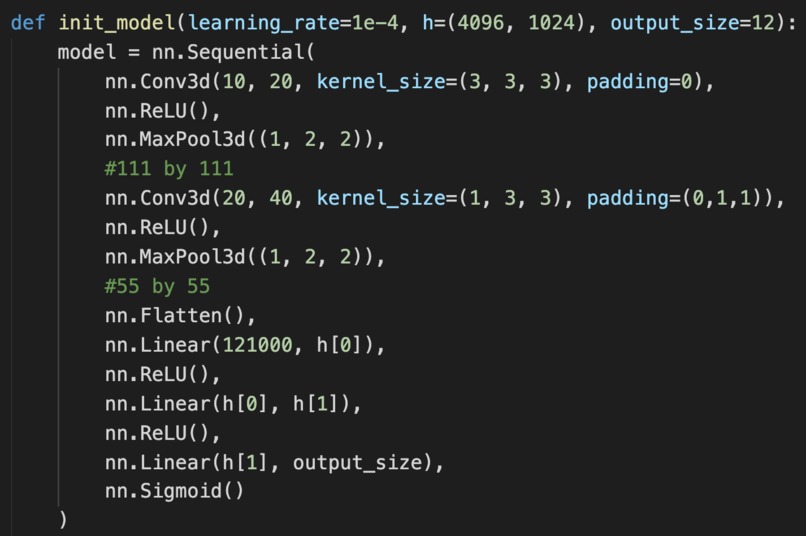
The architecture of PyTuna's underlying convolutional neural net
-

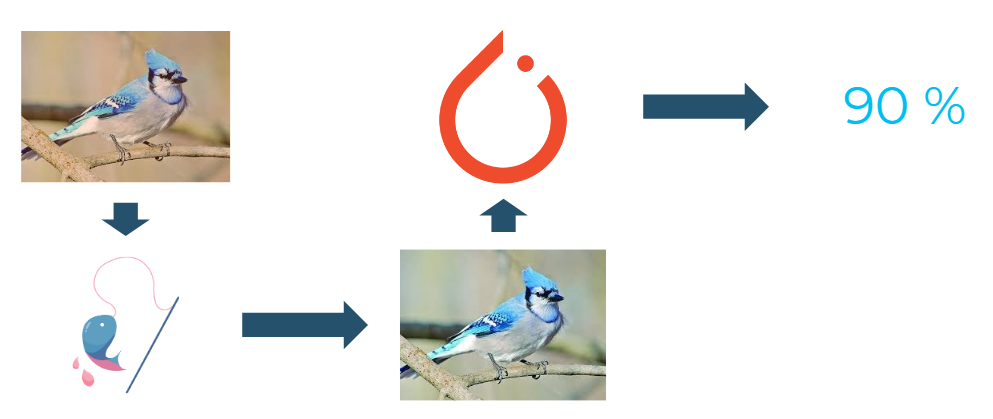
A visualization of the use case for PyTuna.


Inspiration
In the past decade, we've made massive strides in developing accurate architectures and models to the point where most people can, in under a half-hour, use an out-of-the-box model on a dataset. Even so, out of the 24 million programmers in the world, just 300,000 are proficient in AI. This is because the effectiveness of these models is gated by how well the data is prepared; the data preprocessing step is where many programmers, beginners and experts alike, find the most difficulty. As any programmer knows, "garbage in, garbage out" — in other words, a model is only as good as the data that comes in.
However, there are few hard-and-fast rules or workflows to follow when preprocessing a dataset, especially with images. There are so many options to choose from — augmentation, normalization, object detection, Gaussian blur — and little consensus on how to use them.
What it does
With this in mind, we made PyTuna, a pytorch framework that acts as a wizard to guide data scientists through preprocessing any image dataset. Under the hood, PyTuna has a convolutional neural network trained on 50 world-class image datasets and the preprocessing strategies that the most frequently-cited research papers and the most successful Kaggle notebooks used for each of them. Given any dataset, PyTuna first samples a representative subset. Then, it uses a ConvNet to predict a set of preprocessing techniques that are well-suited for the dataset. Next, the PyTuna wizard walks through each of the techniques with the user, automating, educating, and informing at each step. PyTuna makes the case for each technique, but the user gets the final say. Finally, PyTuna returns a list of preprocessed images in PyTorch tensor format, ready to be fed into a model. It also optionally pickles a copy of the preprocessed dataset for future use.
The PyTuna wizard serves to make preprocessing a painless experience, even for coders with little to no experience. With PyTuna, anyone can use PyTorch for computer vision.
How we built it
We gathered 50 of the most frequently used image datasets, then gathered the most cited research papers and highest-ranked Kaggle submissions for each. Then, we manually read through and recorded which preprocessing methods each one used.
We ended up choosing the following set of 12 preprocessing steps to predict from: scaling, augmentation, normalization, zero-centering, removing background colors, object detection, Gaussian blur, perturbation, contrast, grayscaling, histogram equalization, label one-hot encoding.
To generate our training data, we randomly sampled 10 images from a dataset, which were then combined into a single stack of images. We repeated this process 40 times within each dataset to gain a representative set of stacks for the entire dataset. Each label was represented as a tensor with 12 binary elements, each corresponding to whether a preprocessing step was used or not (e.g. [1, 0, 0, 0 ,1, 1, 0, 0, 0, 0, 0, 0]).
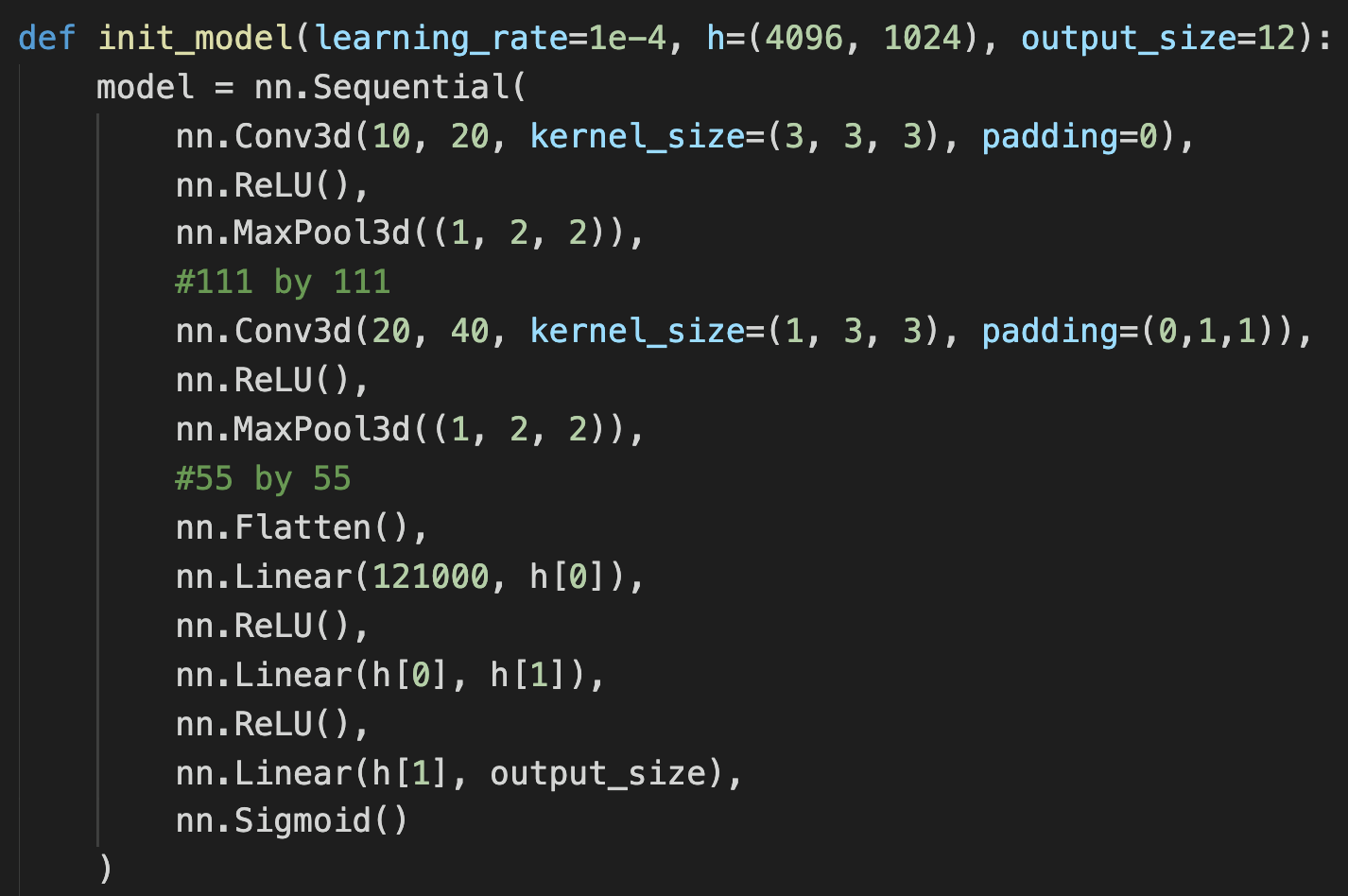
We then created our own custom model consisting of the following layers:
- Input: (1 x 10 x 3 x 224 x 224) which represents (batch size, stack size, color channels, height, width)
- 3D Convolution (10 -> 20 channels)
- ReLU
- MaxPool
- 3D Convolution (20 -> 40 channels)
- ReLU
- MaxPool
- Flatten
- Fully Connected (121000 -> 4096)
- ReLU
- Fully Connected (4096 -> 1024)
- ReLU
- Fully Connected (1024 -> 12)
- Sigmoid
We trained the model across 10 epochs, with 1520 iterations per epoch, taking a total of 12 CPU hours on 2 Intel Xeon 20 core processors. We then evaluated our model on 5 image stacks per dataset and took the mean of the 5 results as our final prediction. We obtained a final mean squared error of 0.12 per class.
Challenges we ran into
The two largest challenges that we ran into were collecting and hand labeling data to train our model on and selecting an appropriate model architecture. As there has never been anything similar to what we have done, our team of 5 had to find 50 impactful image-based datasets, convert each dataset into a format that our API can understand, and search for top Kaggle submissions and highly cited research papers that documented the preprocessing steps used for the dataset. We then had to decide on a list of preprocessing steps that our model could predict. We ended up creating a spreadsheet containing the 50 datasets as well as 12 columns representing each of the preprocessing steps we predict for.
The next challenge came from deciding on an architecture that would be able to convey the information required to decide on what preprocessing steps to use to the model. We first experimented with creating a model of all fully connected layers whose input was a grid representing the means and standard deviations of a sample of images from each dataset. We found that this architecture had poor performance when predicting many of the preprocessing steps like object detection and image augmentation. We also realized that this model wouldn’t be able to make spatial associations within images as it was only looking at the means and standard deviations of how pixel values varied across the sample. We then moved on to using a transfer learning approach using a ResNet with layers prepended and appended to the network in order for the network to effectively analyze multidimensional data. However, this architecture ended up overfitting to the sample of images used from each dataset and therefore had poor validation accuracy when a different sample of images was used. Finally, we switched to a custom network architecture where we used 3d convolution layers in conjunction with several fully connected layers which was able to learn the preprocessing steps without overfitting to any particular set of images.
Accomplishments that we're proud of
As rising second-years in university (each attending different universities), this is the most ambitious project any of us has ever done. We were able to learn a tremendous amount about preprocessing image datasets, designing a convolutional neural network, and training it successfully. In all, we are most proud of the chance to help all coders; we really just want to make it possible for anyone to do computer vision in PyTorch.
What we learned
We learned a ton in the process of designing and tuning our convolutional neural net. We also picked up a thing or two in the process of reading hundreds of notebooks and research papers to see how they preprocessed their datasets. Since we are all beginner hackers, it was a super exciting experience to set this huge goal at the start of the summer and come close to hitting all of our main goals.
Even so, the real learning was the friends we made along the way <3
Acknowledgements
We are tremendously grateful to NCSA at UIUC for their compute resources.
This work utilizes resources supported by the National Science Foundation's Major Research Instrumentation program, grant #1725729, as well as the University of Illinois at Urbana-Champaign.
What's next for PyTuna
As with any convolutional neural net, we would love to continue tuning our hyperparameters and fiddling with the architecture to squeeze out as much performance as possible. We’re also looking into more sophisticated methods of representing large datasets, such as math papers on the most representative subset of a large set. For our endgame, we’d like PyTuna to become a PyTorch module, available for any and all to use.
Thank you so much for this amazing opportunity! We hope you have a great week!









Log in or sign up for Devpost to join the conversation.