
PyTorch meets CORTX
Facebook Research ParlAI conversational AI training and testing pipeline using CORTX S3 with Flask app integration.
Model saving for continous fine tuning

What is ParlAI?
ParlAI is a python-based platform for enabling dialog AI research.
Its goal is to provide researchers:
a unified framework for sharing, training and testing dialog models
many popular datasets available all in one place, with the ability to multi-task over them
seamless integration of Amazon Mechanical Turk for data collection and human evaluation
integration with chat services like Facebook Messenger to connect agents with humans in a chat interface link: https://github.com/facebookresearch/ParlAI
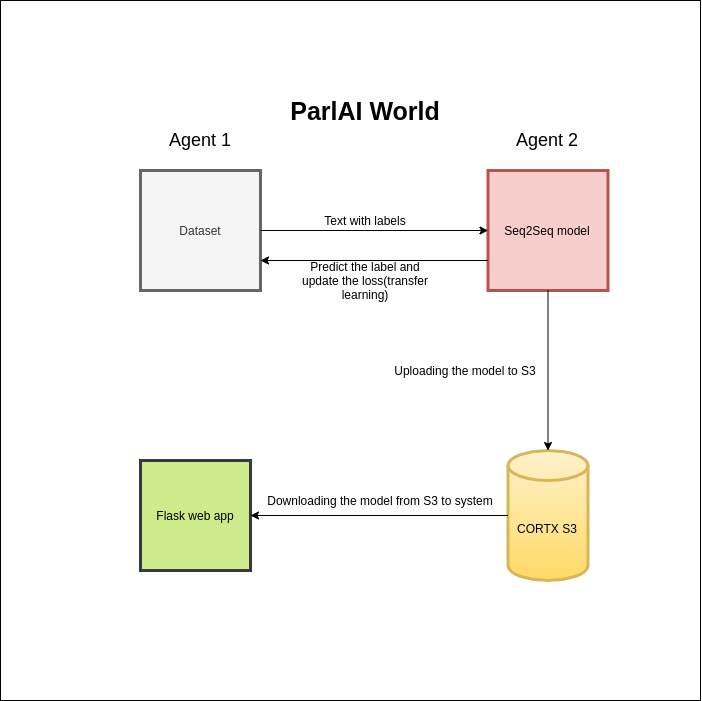
In ParlAI, we call an environment a world. In each world, there are agents. Examples of agents include models and datasets. Agents interact with each other by taking turns acting and observing acts.
To concretize this, we’ll consider the train loop used to train a Image Seq2Seq model trained on all DodecaDialogue tasks and fine-tuned on the Empathetic Dialogue task, We call this train environment a world, and it contains two agents - the seq2seq model and the dataset. The model and dataset agents interact with each other in this way: the dataset acts first and outputs a batch of train examples with the correct labels. The model observes this act to get the train examples, and then acts by doing a single train step on this batch (predicting labels and updating its parameters according to the loss). The dataset observes this act and outputs the next batch, and so on.
CORTX S3 support for ParlAI fine tuning
- During training the latest models get uploaded to the CORTX S3. Which can be downloaded from the bucket for Flask RESTful API integration or web app depolyment.
- This strategy helps in different versions of trained model for custom datasets withoud worrying the larger model size(>4GB)
RUN
I just used private virtual lab through CloudShare with Windows Server 2019 Standard as the system.(https://github.com/Seagate/cortx/wiki/CORTX-Cloudshare-Setup-for-April-Hackathon-2021). You can also Use standard QUICK_START guide for installation.(https://github.com/Seagate/cortx/blob/main/QUICK_START.md)
Installation setup
- Install anaconda python. (https://anaconda.org/)
- create a conda environment
conda create -n cortx pip python=3.7
- activate the environment
conda activate cortx
- Install the requirements
pip install -r requirements.txt
Training
Create an S3 bucket to store the weight files.
Train
cd training
python train.py
The "training" directory include a custom dataset "train.txt" in ParlAI format. Where the "text:" the user message or message from Agent 1, "label:" is the actual message from the AI agent or trained model or Agent 2. The model after geting fine tuned by reducing the loss, can able to predict the label. "episode_done:True" will stops the conversation thread to start a new thread. After training the model gets uploaded to S3 bucket.
train.txt
text:what is CORTX? labels:CORTX is a distributed object storage system designed for great efficiency, massive capacity, and high HDD-utilization
text:is it open sourced? labels:CORTX is 100% Open Source
text:Does it works with any processor labels:Yes, it works with any processor.
text:is it flexible? labels:Highly flexible, works with HDD, SSD, and NVM.
text:is it scalable? labels:Massively Scalable. Scales up to a billion billion billion billion billion exabytes (2^206) and 1.3 billion billion billion billion (2^120) objects with unlimited object sizes.
text:is it responsive? labels:Rapidly Responsive. Quickly retrieves data regardless of the scale using a novel Key-Value System that ensures low search latency across massive data sets.
text:how much resiliant? labels:Highly flexible, works with HDD, SSD, and NVM.
text:bye labels:bye. episode_done=True


Flask web application


cd ..
python application.py -mf "training/poly-encoder/model"
- For each user there will be a unique id to seperate conversations.
- Each connection will include one world, one AI agent and multiple users.
- The fine tuned model will be downloaded from the CORTX S3 bucket for inference in Flask.

Log in or sign up for Devpost to join the conversation.