-
/docs_page
-
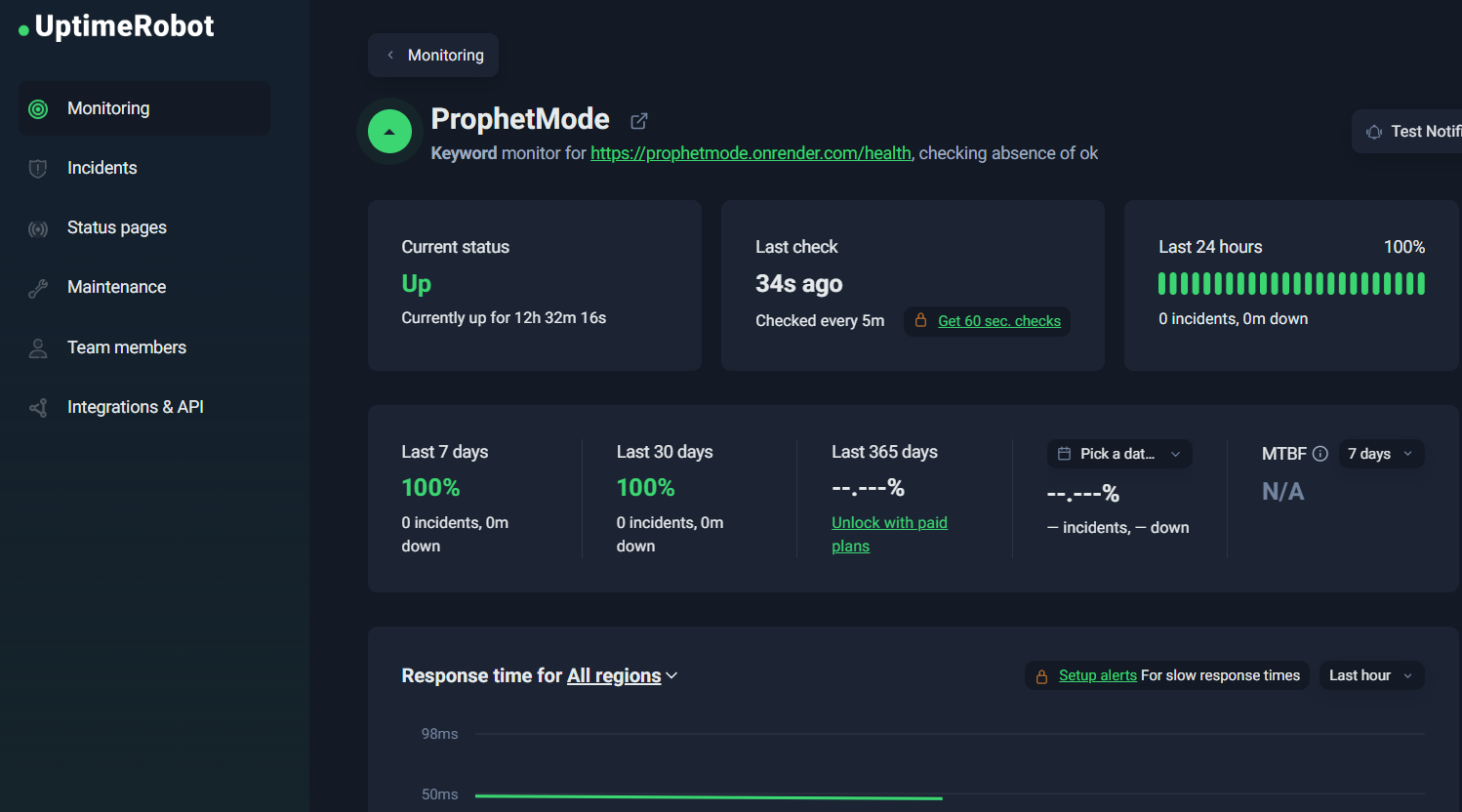
UptimeRobot_dashboard
-
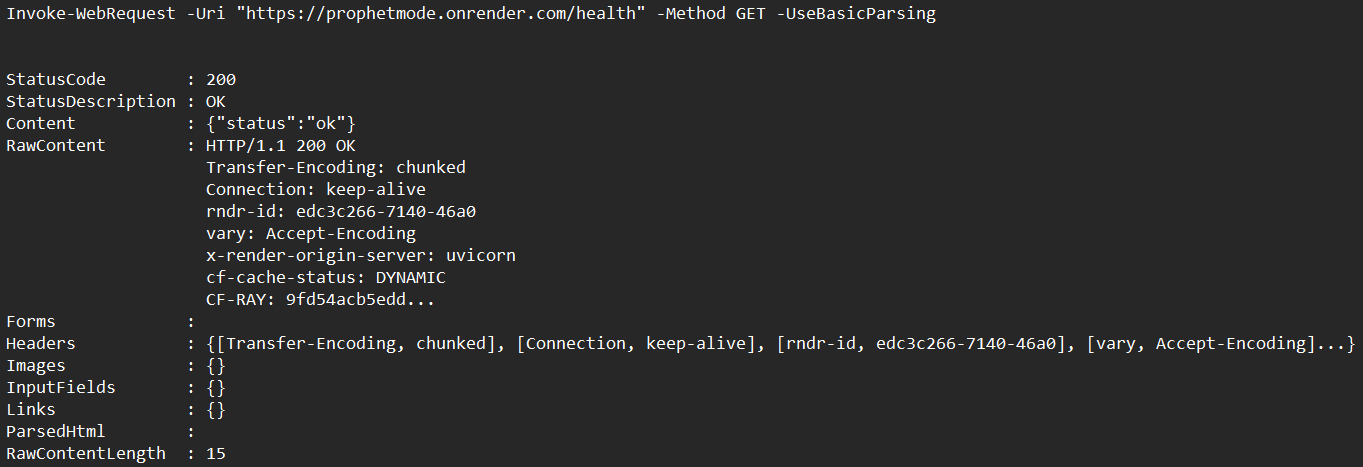
terminal_health_response
-
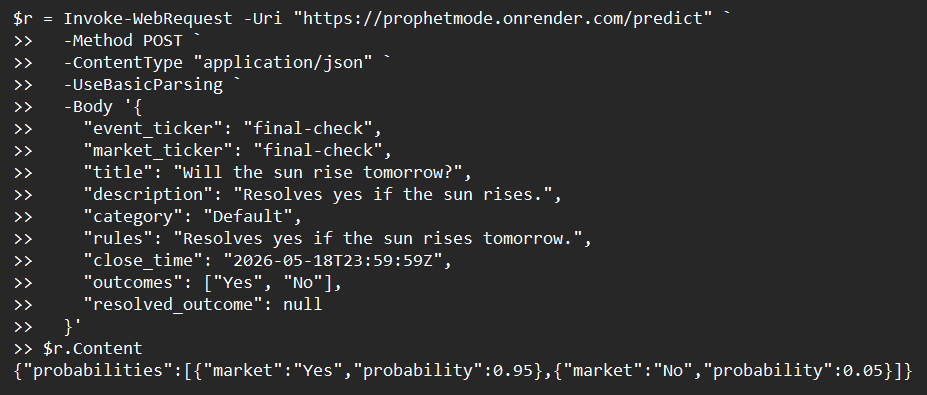
terminal_predict_response
Inspiration
Forecasting the future is one of the hardest things humans do — and most of us are poorly calibrated. Superforecasters beat experts not by knowing more, but by thinking more carefully about uncertainty. We wanted to encode that discipline into an AI agent: one that doesn't just guess, but reasons from evidence and honestly quantifies what it doesn't know.
What it does
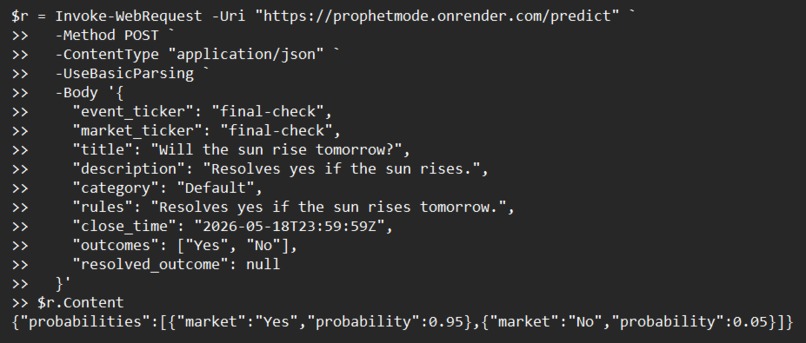
Pythia accepts real-world forecasting questions one at a time and returns a calibrated probability estimate for each possible outcome. Given a question like "Will Cleveland beat Detroit in Game 6?", Pythia retrieves current web evidence, reasons through base rates and recent signals using a structured superforecaster prompt, and outputs a probability per outcome — exposed via a POST /predict HTTP endpoint ready for the Prophet Arena evaluation harness.
How we built it
- FastAPI to serve the prediction endpoint
- OpenRouter to access Claude (claude-sonnet-4-5) for LLM reasoning
- Tavily for real-time web search and evidence retrieval per question
- Category-aware search strategy — Sports, Economics, Entertainment, and Politics questions each trigger domain-specific Tavily queries to maximize evidence quality
- Structured chain-of-thought prompting that guides Claude through: base rate estimation → evidence weighing → bull/bear case analysis → uncertainty acknowledgment → final calibrated probability
- Calibration layer that clamps all probabilities to [0.05, 0.95] preventing overconfidence
- ai-prophet SDK for event schema, CLI tooling, and local evaluation
- Render to host the agent publicly for the 2-week evaluation window
Challenges we ran into
- Preventing LLM overconfidence — Claude naturally outputs extreme probabilities when evidence is one-sided. We built a calibration layer and prompt guardrails to keep estimates honest
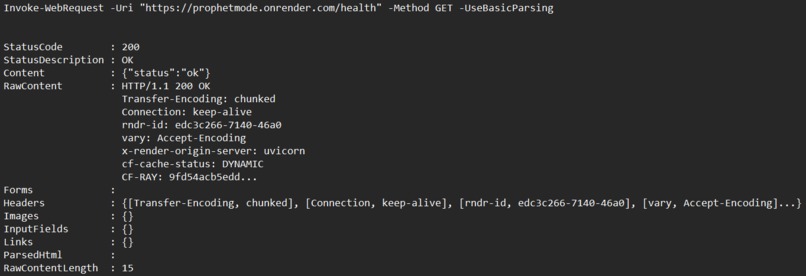
- Designing for reliability — the agent must never crash or skip a question across 200 events over 2 weeks. Every failure mode has a fallback: search fails → LLM only; LLM fails → uniform distribution
- Category generalization — building a single reasoning pipeline that works equally well for sports scores, economic indicators, entertainment awards, and geopolitical events
- Output format precision — matching the exact Prophet Arena schema where outcome labels must match verbatim and probabilities are scored independently, not normalized
Accomplishments that we're proud of
- A fully working deployed forecasting endpoint live within the hackathon window — tested end-to-end against real Prophet Arena event schemas
- Our agent correctly identified a resolved game result by finding the actual outcome via web search and assigned near-certain probability to the correct outcome — exactly what a superforecaster would do
- Clean layered architecture: retriever → reasoner → calibrator — each component is independently testable and replaceable
- Zero crashes across all local test runs with complete structured logging of every prediction and reasoning trace
What we learned
Calibration is harder than accuracy. A model can be directionally right but badly miscalibrated — confidently wrong is worse than uncertain and correct. Building Pythia taught us that structured reasoning scaffolds and evidence grounding matter more than raw model capability. We also learned that reliability engineering — graceful fallbacks, logging, and uptime monitoring — is just as important as the AI logic itself.
What's next for Pythia
- Fine-tuning on historical Metaculus and Polymarket data for domain-specific calibration
- Ensemble voting across multiple LLMs to reduce single-model bias
- Confidence interval output alongside point estimates
- Open-sourcing the prompting framework as a standalone forecasting toolkit
Built With
- ai-prophet-sdk
- claude-sonnet-4.5
- fastapi
- openrouter
- pydantic
- python
- rag
- render
- tavily
- web-search-api



Log in or sign up for Devpost to join the conversation.