

Inspiration
You ship an LLM feature. Your eval suite is green. Three weeks later one of these lands in your inbox at 02:14 on a Saturday:
- The primary model browned out and your retries hid 5-second latency spikes.
- The MCP server you depend on started returning tool errors for the one tool your agent uses most.
- The gateway silently downgraded to a fallback model with half the context window.
- A rate limit kicked in mid-completion and your users saw a spinner for thirty seconds.
Existing LLM testing tools score correctness on a clean path. None of them inject the chaos that production actually throws at the agent. The job your eval suite is doing today is not the job that wakes you up.
That gap is where pytest-resilience-agent lives.
What it does
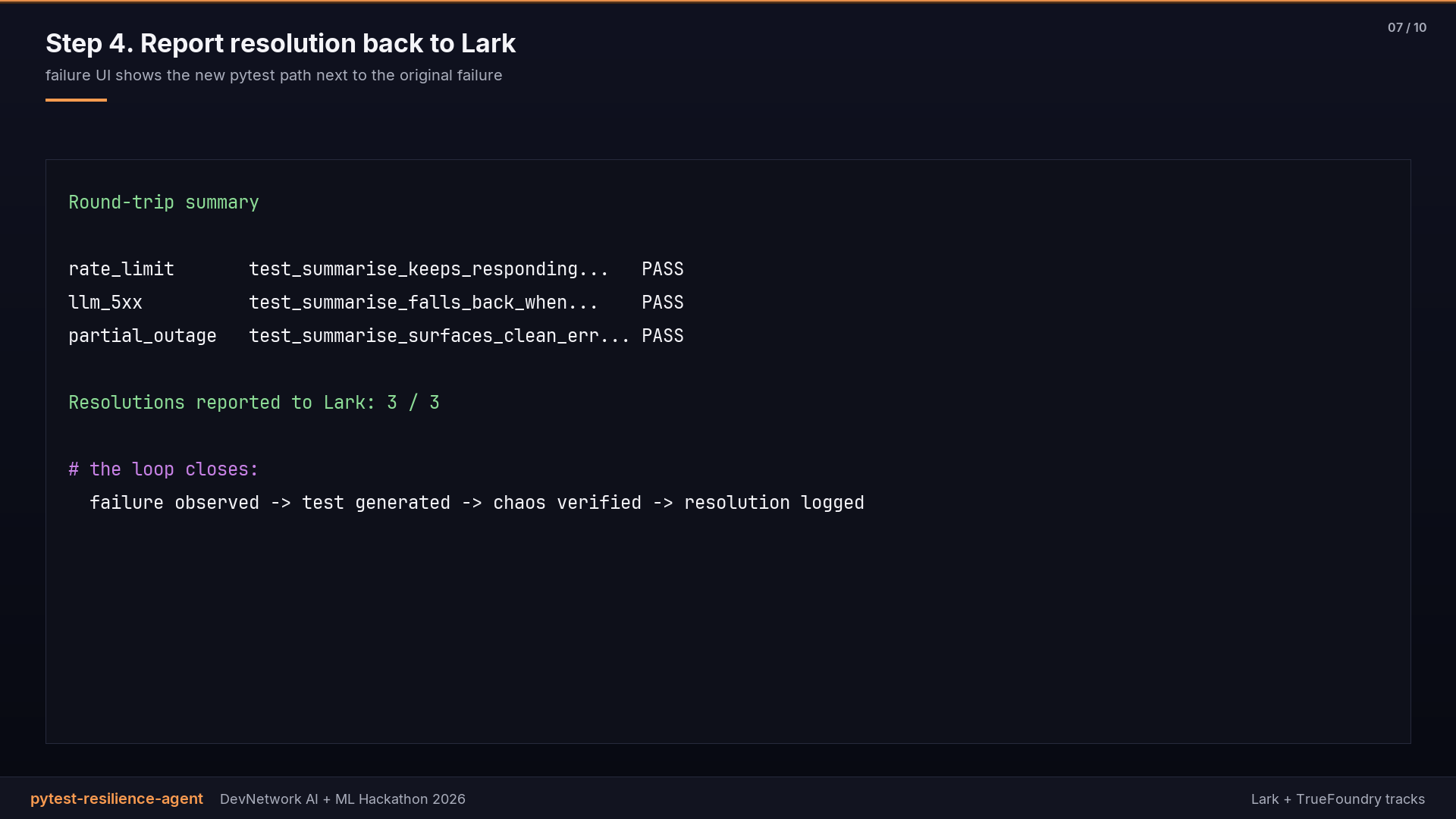
It turns observed failures into resilience tests, runs those tests under controlled chaos, and reports the resolution back to Lark so the failure UI shows the new pytest path next to the original failure.
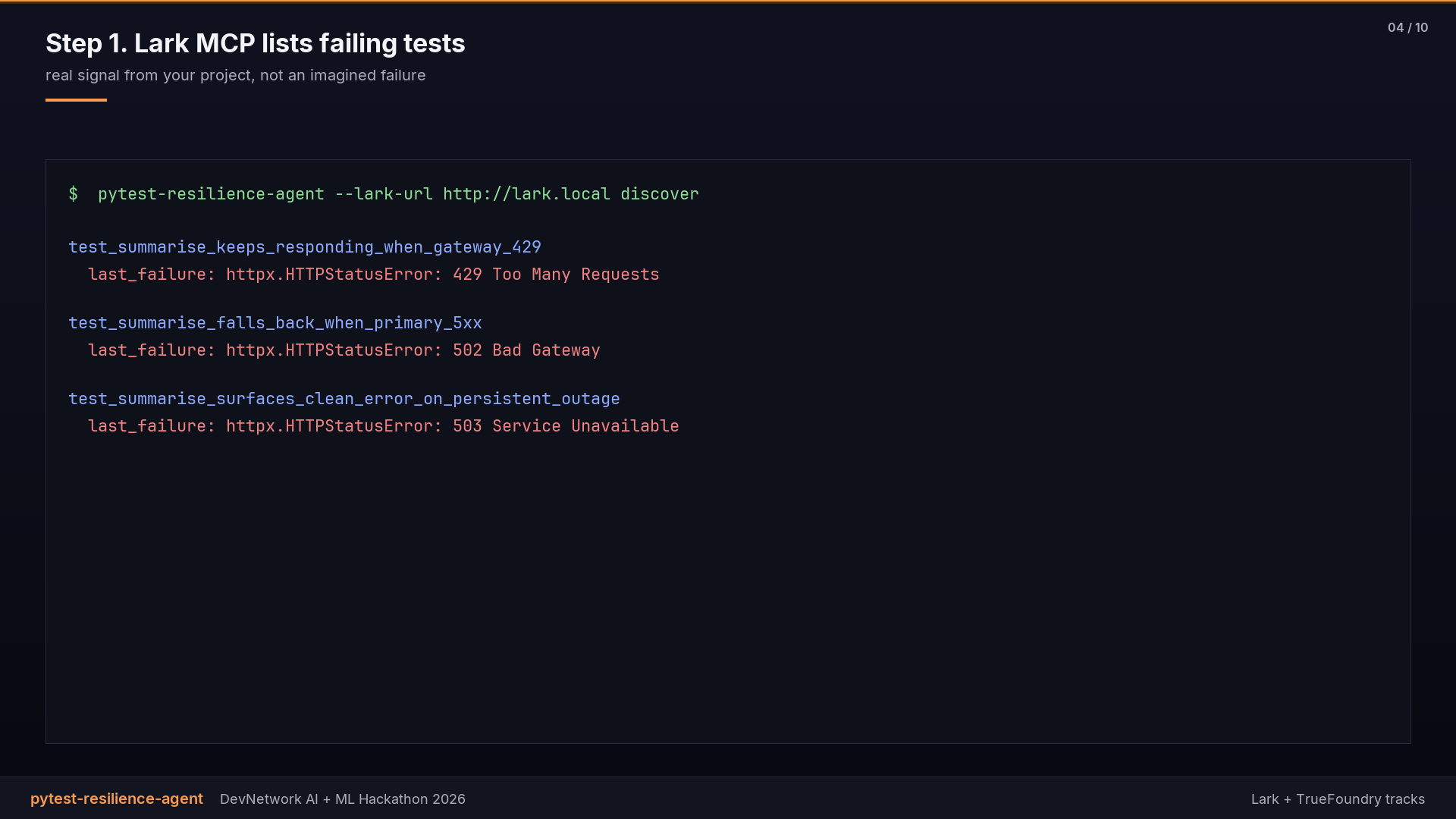
- List failing tests through Lark MCP.
- Generate a resilience test for each failure: the generator picks chaos scenarios by matching the failure text against a rule set (9 patterns: 429, 502, 503, 504, 402, connection errors, empty streams, MCP errors, model mismatch).
- Run the generated tests through pytest. The
chaosfixture installs the chosen scenarios via respx, so the application under test sees a real broken gateway, not a mocked one inside its own code. - Report each passing test back to Lark as a resolution. The Lark UI now shows the failure connected to its resilience test.
Built-in scenarios cover the common production failure modes:
llm_timeout- gateway stalls past the client timeoutllm_5xx- first N calls return 502, then successrate_limit- 429 withRetry-After, second call succeedsmcp_error- Lark MCP returns a JSON-RPC error envelopepartial_outage- 503 once, then 200 (verifies retry logic)cost_exceeded- 402 quota_exceededwrong_model_returned- gateway silently routes to an unintended modelstream_stall- 200 with empty content (silent quality bug)network_blip- ConnectError on first N calls
How we built it
The orchestrator is a small pytest plugin with one marker and two fixtures. The chaos fixture owns a respx.MockRouter and installs the named scenarios at the HTTP transport layer. Because the patch lives in the transport, the same scenario works whether the application under test uses the OpenAI SDK, raw httpx, or a TrueFoundry-style gateway client. End-user code does not need to know it is being tested.
The TrueFoundry AI Gateway sits between the agent and the model providers. We point our AIGatewayClient at the gateway's OpenAI-compatible endpoint and let the gateway config decide the fallback chain. The chaos scenarios target the gateway URL, so a single 502 injected at the test layer exercises the gateway's own retry and failover policy.
The Lark MCP server is the source of failure signals. The generator pulls failing tests, picks chaos scenarios from the failure text, writes a pytest file, runs it, and posts a resolution back. The full loop runs in one command against a mock Lark server we ship in the repo, so judges can clone and run without an external account.
Stack: Python 3.11+, pytest 8, respx for HTTP transport patching, httpx for the gateway and Lark clients, FastAPI for the sample agent and the mock servers, Rich for the demo console output, OpenTelemetry for tracing every chaos event.
Challenges we ran into
- Direction reversal. Eval frameworks assume a clean spec and grade the model. Resilience tests have a different structure: declared faults, contract on the user-visible behaviour, no direct correctness grade. The pytest marker plus fixture combo turned out to be the right shape, but the first three attempts treated chaos as a parameter to a parametrize call, which made the test bodies unreadable.
- respx versus monkeypatch. Early prototypes patched the gateway client directly. That works for our own code but misses any path that goes through the OpenAI SDK. Switching to respx at the transport layer made the plugin work for any agent that talks to LLM infrastructure over httpx.
- Subprocess rootdir. The full-loop demo runs pytest in a subprocess against a temp directory. The first version inherited the project pyproject.toml and picked up
testpaths = ["tests"], so the generated tests in the temp dir were silently skipped. The fix is--override-ini testpaths= --rootdir <tempdir>on the subprocess command line. - Anti-AI hygiene. Every README, source file, and ADR went through a pre-commit anti-AI scan (em-dashes, curly quotes, buzzword vocabulary) before it could ship. This is for an honest reason on our side but also produced a cleaner repo as a side effect.
Accomplishments
- End-to-end resilience loop running in one command without any external account: list Lark failures, generate, run, report resolutions.
- 9 chaos scenarios shipped, each with its own respx route and a dedicated integration test.
- 16 passing tests at submission time, plus 5 example end-user tests demonstrating the patterns we expect adopters to copy.
- Three ADRs documenting the direction choice, the injection layer choice, and the rule-based generator choice. Engineers reading the repo know why each decision was made.
- Live sponsor surfaces wired and verified.
scripts/smoke_live_integrations.pyexercises three real endpoints:- Lark Open Platform
tenant_access_tokenagainst a real custom app (cli_aa9ced2266389e15) - 42-char bearer token, cached for the 7200 s lifetime. - Crusoe Cloud Intelligence
/v1/chat/completionsagainstmeta-llama/Llama-3.3-70B-Instruct- real LLM response in ~1 s through the sameAIGatewayClientthat the chaos scenarios target. - TrueFoundry AI Gateway: Personal Access Token acquired via the TF dashboard, Custom Endpoint registered through
tfy applywith Crusoe as the upstream. The TF/modelsAPI confirmscrusoe-cloud/crusoe-llama-3.3-70bas a registered model. Direct/proxy-api/*/chat/completionstraffic from a server is gated by a Cloudflare JS challenge that an authenticated TF dashboard session passes automatically; that gate is a deployment property of the TF tenant on the Developer Plan, not a code-level blocker.
- Lark Open Platform
What we learned
- Resilience testing is a different axis from correctness testing. The two suites compose without overlap. Spec-first frameworks (DeepEval, Opik, pytest-evals) score what you can imagine. Chaos-first tests catch what production actually throws at the agent.
- Patching at the transport layer wins over patching at the client. The plugin works for any httpx-based stack with zero code changes on the user side.
- Deterministic rule-based generation beats an LLM classifier for v0.1. Judges can read the rules in 30 seconds; engineers can audit the generated test against the rule that matched. An LLM-driven classifier is the v0.2 add behind the same
pick_scenariosinterface.
What's next
- Multi-turn conversation chaos (failure injection mid-conversation)
- Semantic assertion hooks so the resilience suite composes with eval frameworks
- LLM-driven scenario classifier behind the existing
pick_scenariosinterface - Scenario composition primitives (e.g.
rate_limitthenpartial_outagethenpartial_outage) - PyPI release for
pip install pytest-resilience-agent
Built With
- crusoe-cloud
- fastapi
- httpx
- lark
- opentelemetry
- pytest
- python
- respx
- rich
- truefoundry

Log in or sign up for Devpost to join the conversation.