-
-

This is a screenshot of the GitHub repository of PyGlow.
-
This is a screenshot of the main page documentation of PyGlow (link in the repo).
-
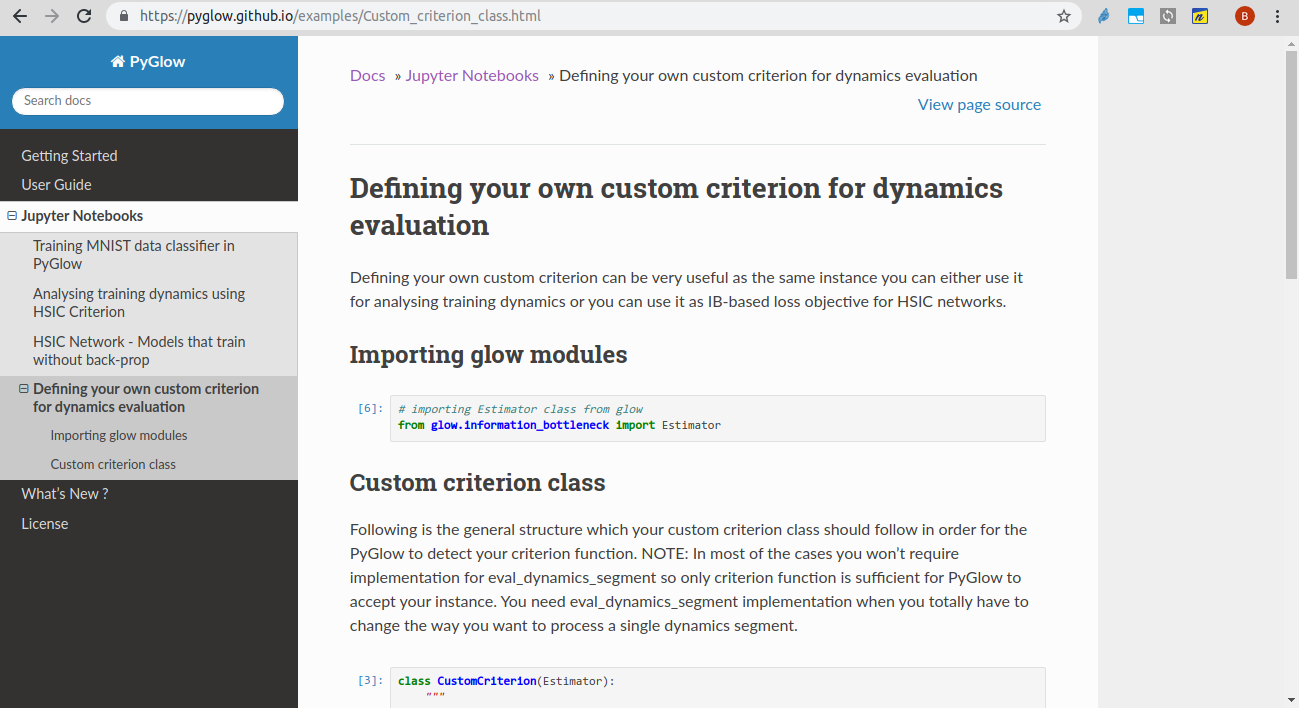
This is a screenshot of the notebook given in documentation page (link in the repo) which tells how to implement your custom criterion.
-
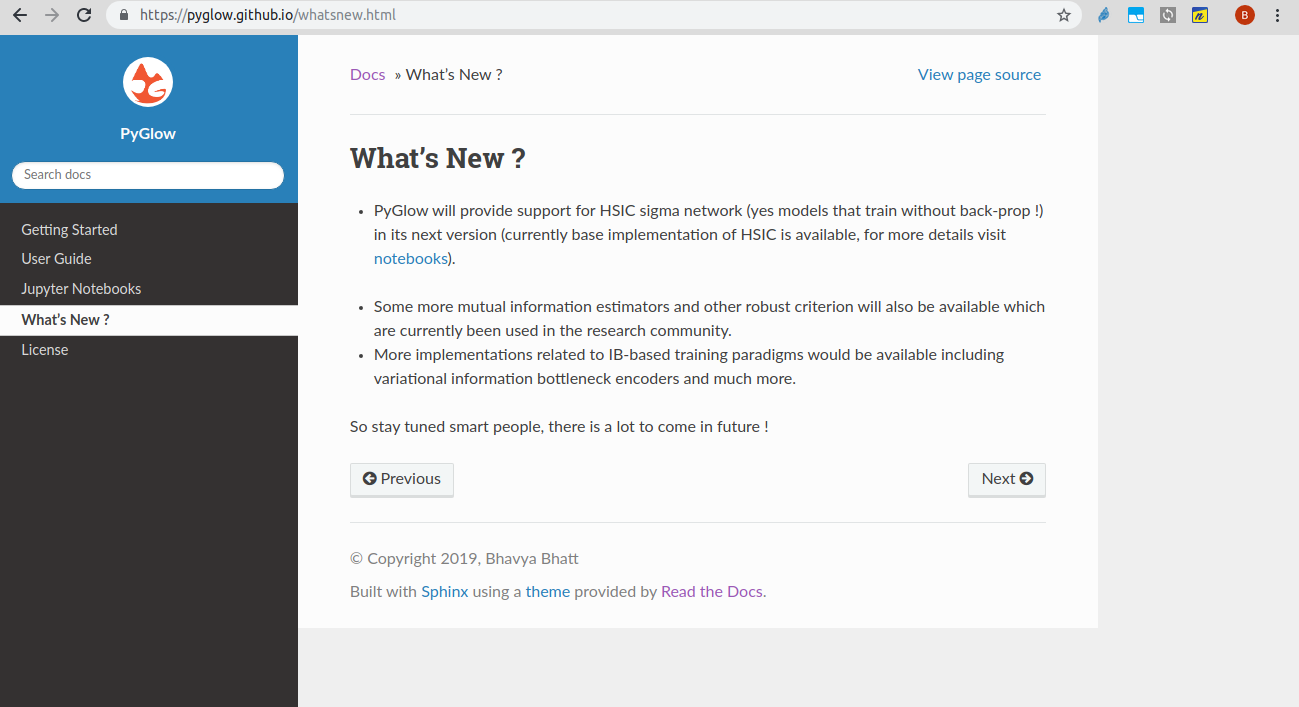
This is a screenshot of future updates which will be available in coming versions and is given on documentation page.
-
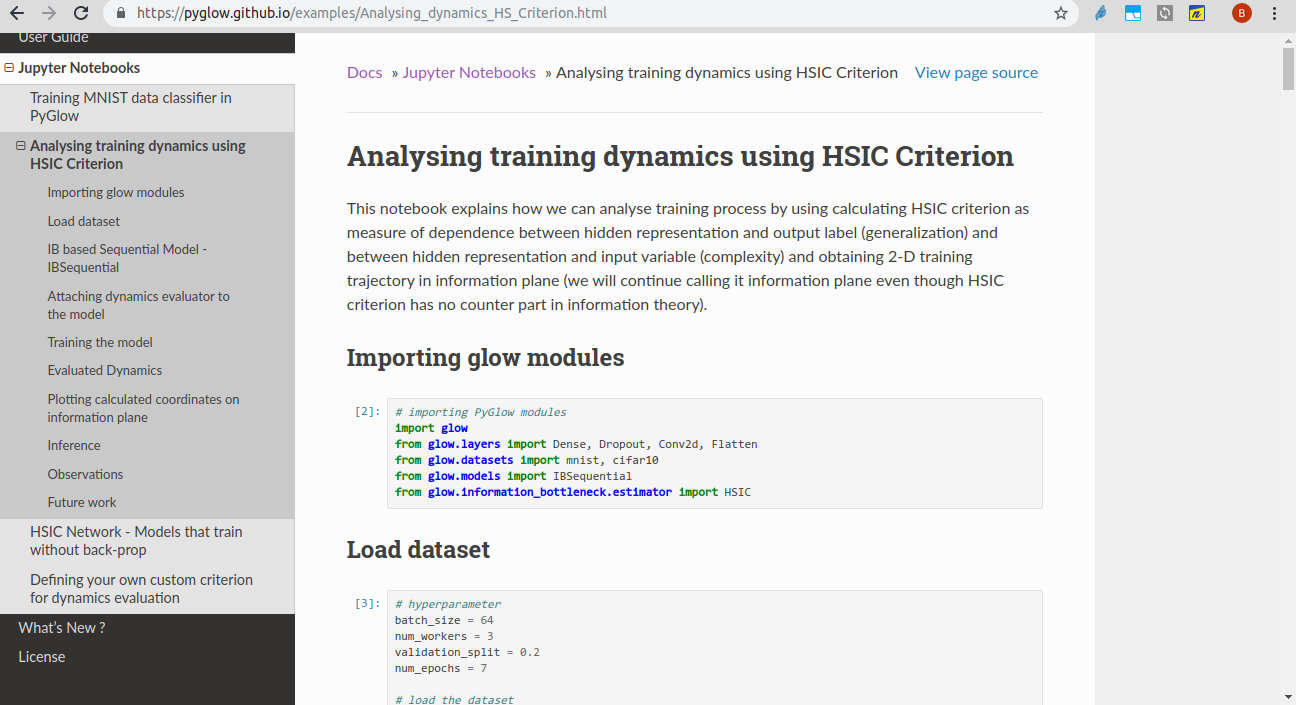
This is another notebook in documentation page which tells users how to use IBSequential model to analyse training dynamics (using HSIC).
-
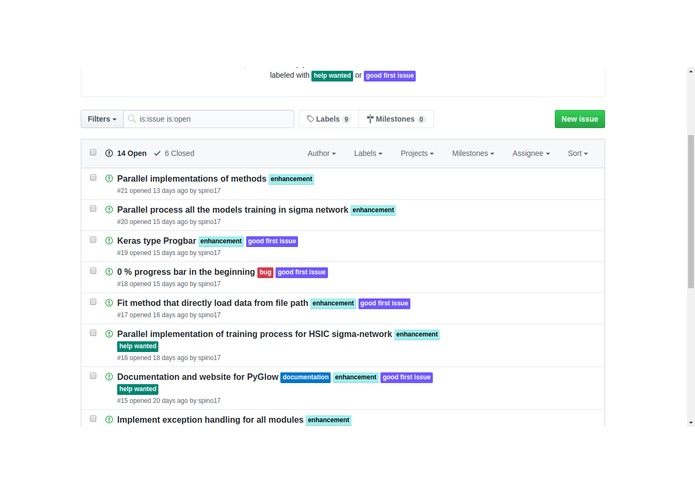
This is a screenshot of issue tracker page of the GitHub repo of PyGlow. Anyone up for contribution can refer to this or the documentation.


Inspiration
I loved PyTorch more than any deep learning framework out there and I wanted to make my dream come true of having a Keras like API on PyTorch backend. I started working on my final year major technical project few months back which mainly deals with application of information theory, statistical mechanics, learning theory and complexity theory to get a deeper understanding of theoretical aspects of generalization, memorization and compression in the context of deep neural networks.
The idea of information theory in deep learning
One of the exciting ideas which provide a theoretical explanation for the dynamics of neural networks is the application of Information Bottleneck Principle in deep learning. This idea really helped researchers in gaining deeper insights in the training dynamics when analysed in information plane.
These methods include estimation of mutual information between input, output and hidden representations, which can have very different values for different parameters of the estimator and if not calculated correctly can result in varying observations and interpretations of the training process.
Due to this many of the other researchers who tried to repeat the experiment of information bottleneck method did not get the results which were claimed in the original paper "Opening the black box of Deep Neural Networks via Information" (The observation was that training process happens in two phases namely generalization phase and compression phase).
The controversy
This lead to a controversy that 'Do information bottleneck principle generalize to other architectures and activation functions as well or is it just a property of only special activation functions ?' (for example, the original paper used tanh activation function and showed to have observed these two phases during training). The authors of the original paper claimed that the authors of the attacking paper have not calculated mutual information correctly and thus have not been able to observe the two phases. The controversy was apparently resolved when many other researchers proposed better mutual information estimation techniques (like EDGE, MINE) and observed the same generalization and compression phase for relu activation function as well.
But even then researchers in the past one year (through papers published mainly in 2019) have published many papers claiming that though regularizing intermediate representations is a great and valuable idea, suffers from critical theoretical issues which have been shown in these papers.
The need for improvement
Because of the above issues, researchers are trying to come up with new measures of generalization and complexity (captured by I(T, Y) and I(T, X) respectively in traditional IB theory) but at the same time, keeping the idea of intermediate representations, which is the fundamental change of perspective that IB theory offers and these have shown interesting theoretical and experimental results in the past few months. Hence even if the pure information bottleneck principle does not give robust framework for studying the dynamics, it surely have the potential to act as a guiding principle for more advanced frameworks based on information flow.
Why PyGlow ?
The idea of PyGlow is to provide a library support to researchers interested in the field of theoretical deep learning and related information theoretic methods. PyGlow can serve as a common library platform using which researchers can accurately carry out their experimentation without being hindered by miscalculation of different components of the information theoretic methods. The goal is to provide researcher with enough freedom to try out their own hypothesis but also at the same time provide them with the ease to implement these ideas in their code for experimentation. The goal is to allow researchers to really focus on the theoretical aspects of the neural network dynamics rather than been occupied in debugging the code and which in turn can prevent controversies that happen due to failure of reproducing the observations due to inaccurate computations.
We don't know the future of theoretical deep learning neither we know how much information theory will play a role in the final unified framework for deep learning but the idea of studying the dynamics in generalization compression measure plane is itself very promising and definitely have taken us one step closer to our goal.
What it does
PyGlow is a Python package which attempts to implement Keras like API struture on PyTorch backend. It provides functionalities which supports information theoretic methods in deep learning. These methods are relevant for understanding neural network dynamics in information plane. The package is equipped with a number of state-of-the-art algorithms for estimating and calculating various kinds of information theoretic measures. The package also provides intensive support for information bottleneck based methods in deep learning. These functionalities include mutual information estimators like EDGE, KNN, KDE, KSG in non-parametric and MINE etc. in parametric estimators, together with new training paradigms like HSIC training algorithm which do not use back propagation ! The future plan for PyGlow is to make the library fully equipped with such functionalities so that it can be used in the research community as a standard package to carry out experimentation in the field of theoretical deep learning.
The package is currently in its development status and is available on Test PyPI or PyPI.
The prerequisite for the package is PyTorch (version greater than 1.1.0). After installation, you can verify it by running the following code in python shell.
import glow
print(glow.__version__)
out[1]: '0.1.7'
How I built it
I closely followed the API structure of Keras but at the same time followed the conventions of PyTorch so that anyone can make transition from Keras to PyGlow but also tend to slowly learn the 'PyTorch' way of doing deep learning and can really explore this beautiful deep learning framework. So I built it keeping in mind the best of both worlds. Apart from the API structure, for information theoretic methods, I referred to a large number of awesome research papers which have been published in this field and several conference discussion portals to learn about the viewpoints that the reviewers and researchers hold for IB-theory in general. I tried to implement these methods as efficiently as possible, in which PyTorch shinned like a charm.
Challenges I ran into
Firstly I did not know PyTorch really well so I learned it from an online course on Udacity and really loved it. Then the challenges I faced during the development of this API structure was to decide on how to get around the problem of tensor shape flow which changes with layers, though I was finally successful in implementing a clean pipeline for handling of the tensor shapes. Second challenge I am still facing is to implement mutual information estimators which is a research field in itself and there exists a lot of algorithms to chose from and integrate into the code but currently the plan is to implement EDGE algorithm because of its scalability and its nature to fit into the pipeline of forward pass source code (unlike some neural network based estimators which tend to use parametric function with f-representations of KL-Divergence and use gradient descent to optimize a lower bound version of mutual information).
Accomplishments that I'm proud of
I have made libraries in past also which are related to numerical relativity and relativistic astrophysics computations (EinsteinPy) in which I mainly dealt with theoretical physics concepts but this time I implemented this library on my own as a sole contributor and the accomplishment I am really proud of is the amount of knowledge I gained during this journey of building PyGlow from scratch and I hope to extend this knowledge even further in coming years.
What I learned
I learned how a library pipeline works because I got the opportunity to read the source code of both the libraries, Keras and PyTorch. I also learned how to package a python source code with which I struggled a lot.
Apart from that, I learned a lot of new concepts in theoretical deep learning and explored different approaches which researchers are using to make deep learning a more interpretable and theoretically rigorous field rather than a black box. Lastly I tend to realise how research is conducted on a specific topic and learned how to experiment with your hypothesis in code.
What's next for PyGlow
I will try to implement all of the state-of-the-art information theoretic methods which are currently been used in deep learning research. Immediate goals for PyGlow is to perform rigorous unit testing on each module and increase the coverage of the source code.
I will also use PyGlow in my future research and will test some of my ideas on non-equilibrium phase transitions and continuum field theory of parameters in deep learning.
PyGlow is up for contributions from the community and anyone can checkout the Issues Tracker in the GitHub repository.

Log in or sign up for Devpost to join the conversation.