Tocky — Omnimodal Ambient Medical Scribe
Inspiration
Doctors spend nearly two hours on paperwork for every hour with patients. Clinical documentation — transcribing conversations, structuring SOAP notes, coding diagnoses — is the #1 contributor to physician burnout. We watched doctors in Vietnam, the Middle East, and France struggle with the same problem: existing tools don't handle their language, their dialect, or their workflow. We built Tocky to give doctors their time back, in whatever language they speak.
What it does
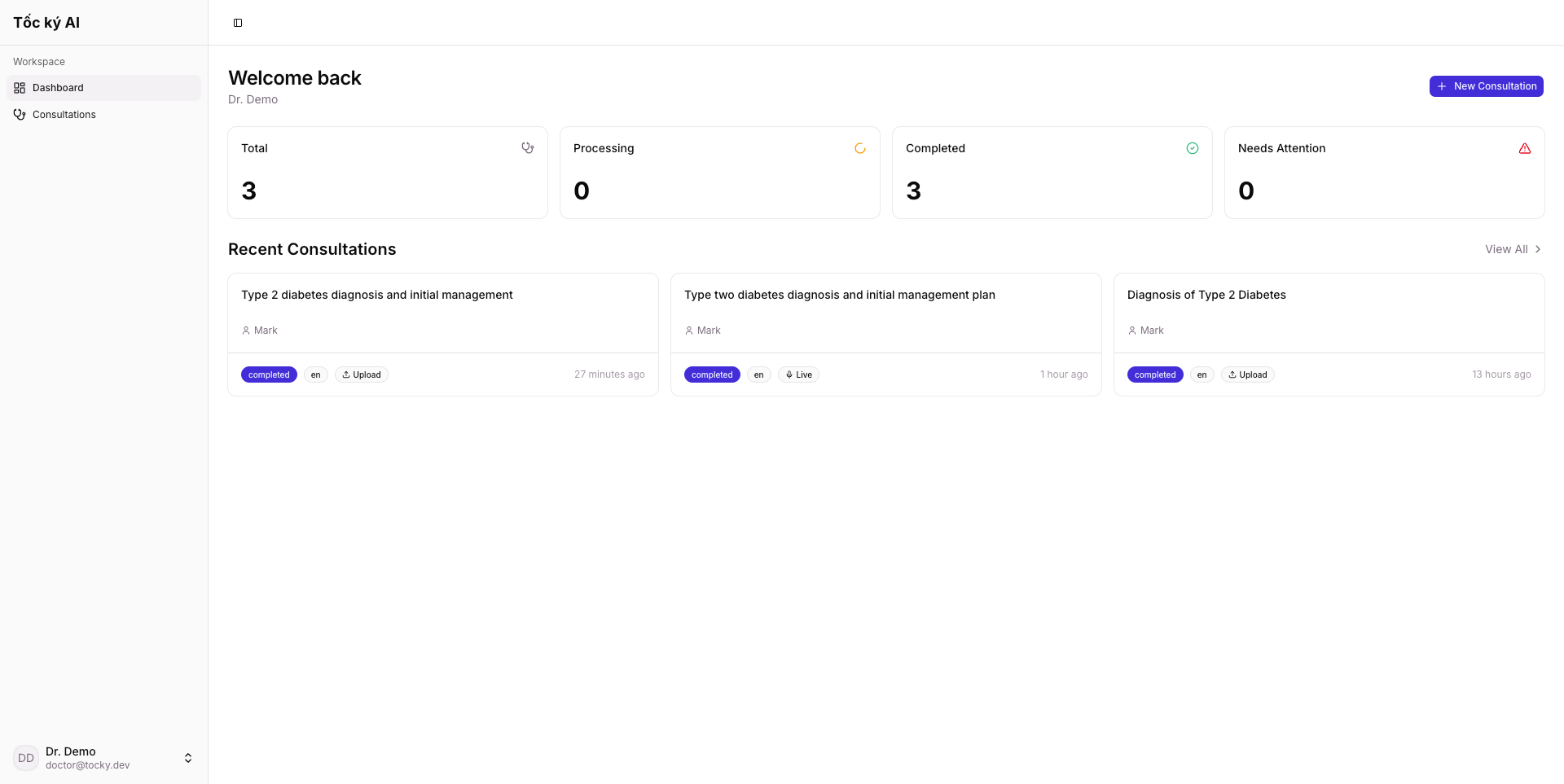
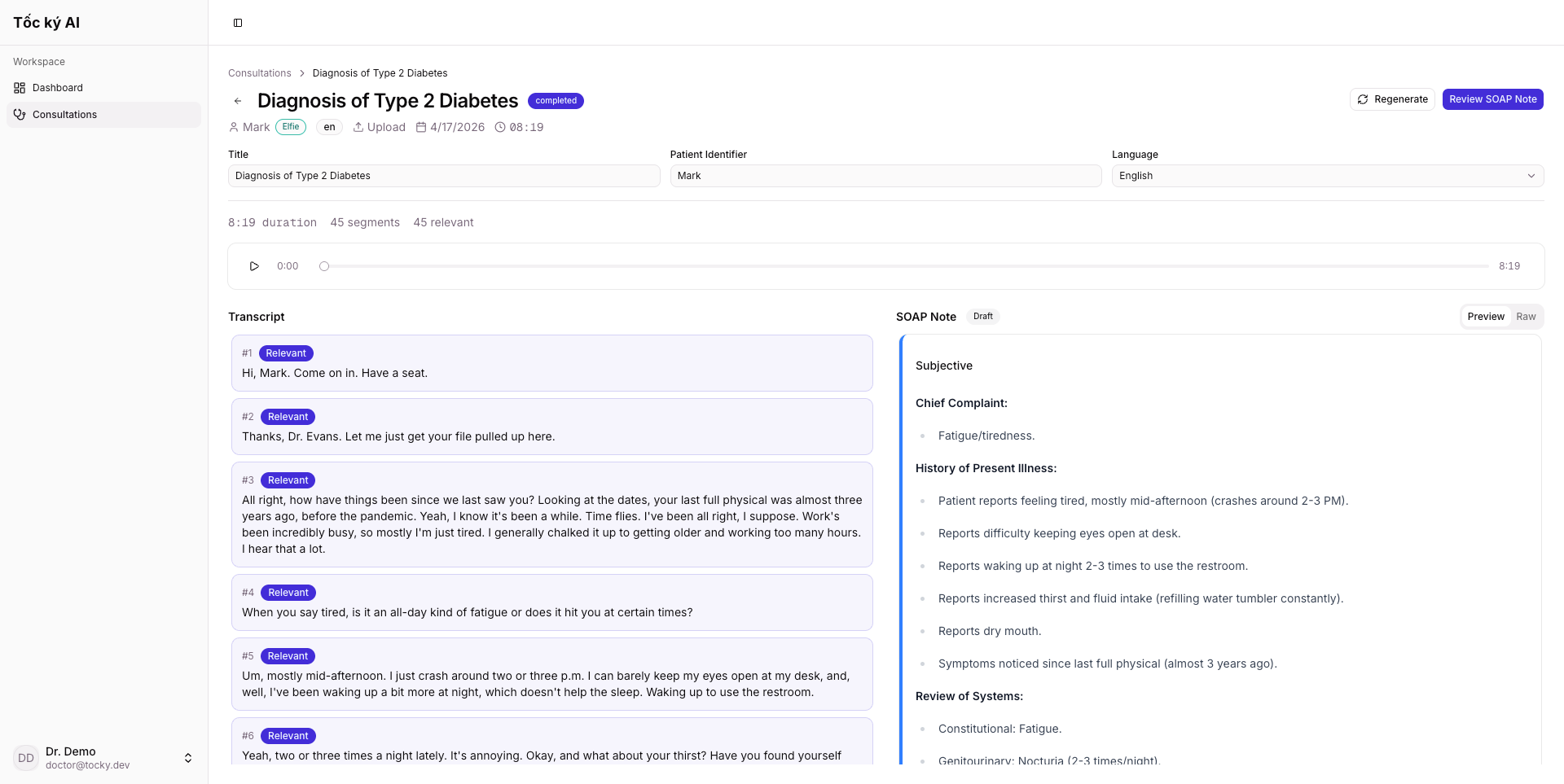
Tocky listens during clinical consultations and generates structured SOAP notes in real-time. It:
- Streams audio via WebSocket — the doctor hits record, and medically relevant transcript segments appear live, while small talk is filtered out automatically
- Generates SOAP notes progressively — Subjective, Objective, Assessment, and Plan sections update every 30 seconds during the consultation, so there's no long wait at the end
- Supports 4 languages natively — English, Vietnamese, Arabic (Egyptian and Gulf dialects), and French, with automatic language detection
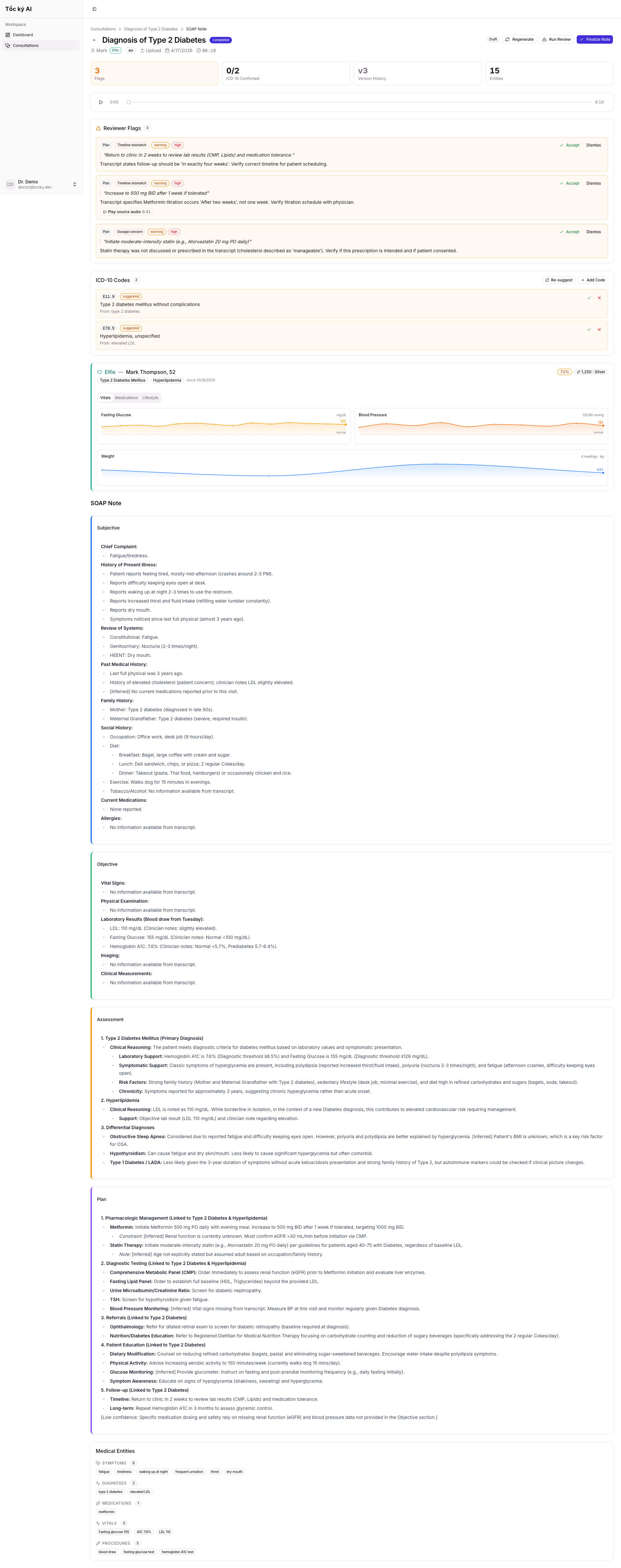
- Runs QA review — flags 8 types of clinical issues (symptom-diagnosis mismatches, dosage concerns, contraindications, ambiguous terms) with severity levels so doctors can verify before finalizing
- Suggests ICD-10 codes — maps extracted medical entities to diagnosis codes, validated against a 15K-code database
- Integrates with Elfie — pulls patient history from a chronic disease management platform to provide context-aware clinical reasoning
- Provides an admin dashboard — tracks quality metrics comparing AI-generated vs. doctor-finalized notes, flag acceptance rates, and exports training data for continuous improvement
How we built it
Backend: FastAPI (Python 3.13) with async everywhere — async database (SQLAlchemy + asyncpg on PostgreSQL), async WebSocket streaming, async AI calls. The core of Tocky is a LangGraph state graph that orchestrates 7 processing nodes: language detection, metadata extraction, transcript polishing, entity extraction, two-pass SOAP generation (extract facts first, then clinical reasoning), QA review, and ICD-10 coding. The pipeline supports conditional routing — live recordings get periodic lightweight updates, while finalized recordings go through the full pipeline.
AI: Qwen models via DashScope — qwen3-asr-flash for streaming speech recognition and qwen2.5-omni-7b for multimodal audio understanding. SOAP generation uses a two-pass approach: Pass 1 extracts factual Subjective + Objective sections, Pass 2 performs clinical reasoning for Assessment + Plan with patient history context. We wrote 20+ language-specific prompt templates.
Frontend: Next.js 16 (App Router) with React 19, Zustand for state, React Query for server state, Tiptap for rich text editing, and shadcn/ui + Tailwind v4 for the interface. The scribe UI is a split-pane layout — live transcript on the left, evolving SOAP note on the right.
Auth: ES256 ECDSA JWT shared between Next.js and FastAPI, with a short-lived token handoff for cross-origin WebSocket authentication.
Challenges we ran into
- Arabic dialect handling — Egyptian and Gulf Arabic sound different enough that a single prompt set produced poor results. We had to create dialect-specific prompt templates and tune VAD silence thresholds per language (900ms for Vietnamese, 1500ms for Arabic).
- Cross-origin WebSocket auth — browsers don't send cookies on WebSocket upgrades across origins. We solved this with an ephemeral ticket exchange: the frontend requests a short-lived token via a same-origin API call, then passes it as a query parameter to the WebSocket.
- Graceful degradation — AI calls fail. We built a soft-fail architecture where errors accumulate in the pipeline state rather than crashing it, so a failed entity extraction doesn't block SOAP generation. Batch processing checkpoints PCM audio to cloud storage so failed transcription chunks can be retried individually.
Accomplishments that we're proud of
- Real-time SOAP updates every 30 seconds during a live consultation — doctors see structured notes forming as they talk
- A two-pass SOAP generation approach that separates fact extraction from clinical reasoning, producing significantly better Assessment and Plan sections
- Full multilingual support including Arabic dialect awareness — not just translation, but culturally appropriate clinical documentation
- A QA review system that catches clinical issues before finalization, with a feedback loop that tracks which flags doctors actually find useful
What we learned
- Medical AI isn't just about accuracy — it's about trust. Confidence annotations (
[Low confidence: reason]) and review flags matter more than a slightly better model, because doctors need to know where to look twice. - Language-specific tuning goes far beyond translation. VAD thresholds, silence detection, medical terminology normalization, and prompt structure all need per-language attention.
- Two-pass generation (extract then reason) consistently outperforms single-pass for clinical notes, because it forces the model to separate observation from interpretation.
What's next
- Speaker diarization — distinguish doctor vs. patient speech for more accurate Subjective/Objective separation
- Specialty-specific templates — cardiology, pediatrics, and dermatology each have distinct documentation patterns
- Fine-tuned models — using the admin dashboard's training data export (AI SOAP vs. doctor-edited SOAP pairs) to fine-tune domain-specific models
- Mobile app — bring Tocky to the bedside with a native mobile recording experience
Demo site accounts
doctor@tocky.dev/doctor123 admin@tocky.dev/admin123
Built With
- nextjs
- python
- qwen
- realtime

Log in or sign up for Devpost to join the conversation.