-
-

Logo
-
UI diagram 1
-
UI diagram 2
-
Render (backend)

Inspiration
Between 40%-70% of medical devices and equipment in low and middle-income countries are broken, unused, or unfit for purpose. The problem is compounded by severe workforce shortages: many low-income countries have fewer than one biomedical engineer per 100,000 people. Thus 10–30% of donated equipment is ever put into operation. This means 70–90% ends up being unused or broken, not because it's useless, but because no one has the training, spare parts knowledge, or repair guidance to fix it.
In many hospitals, technicians lack:
- Step-by-step repair documentation in their language
- Access to spare parts guidance
- Real-time troubleshooting support
We built Puzzled to close this gap. Instead of donating more devices, what if we helped hospitals to fix the ones they already have?
What it does
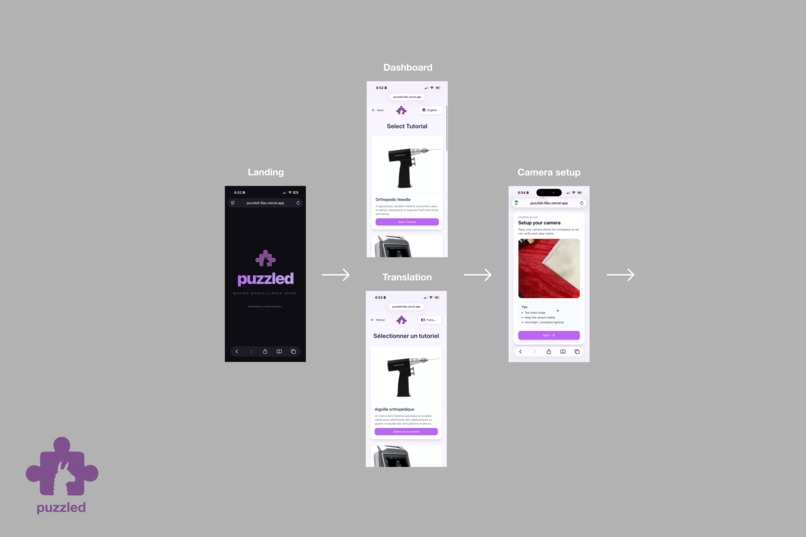
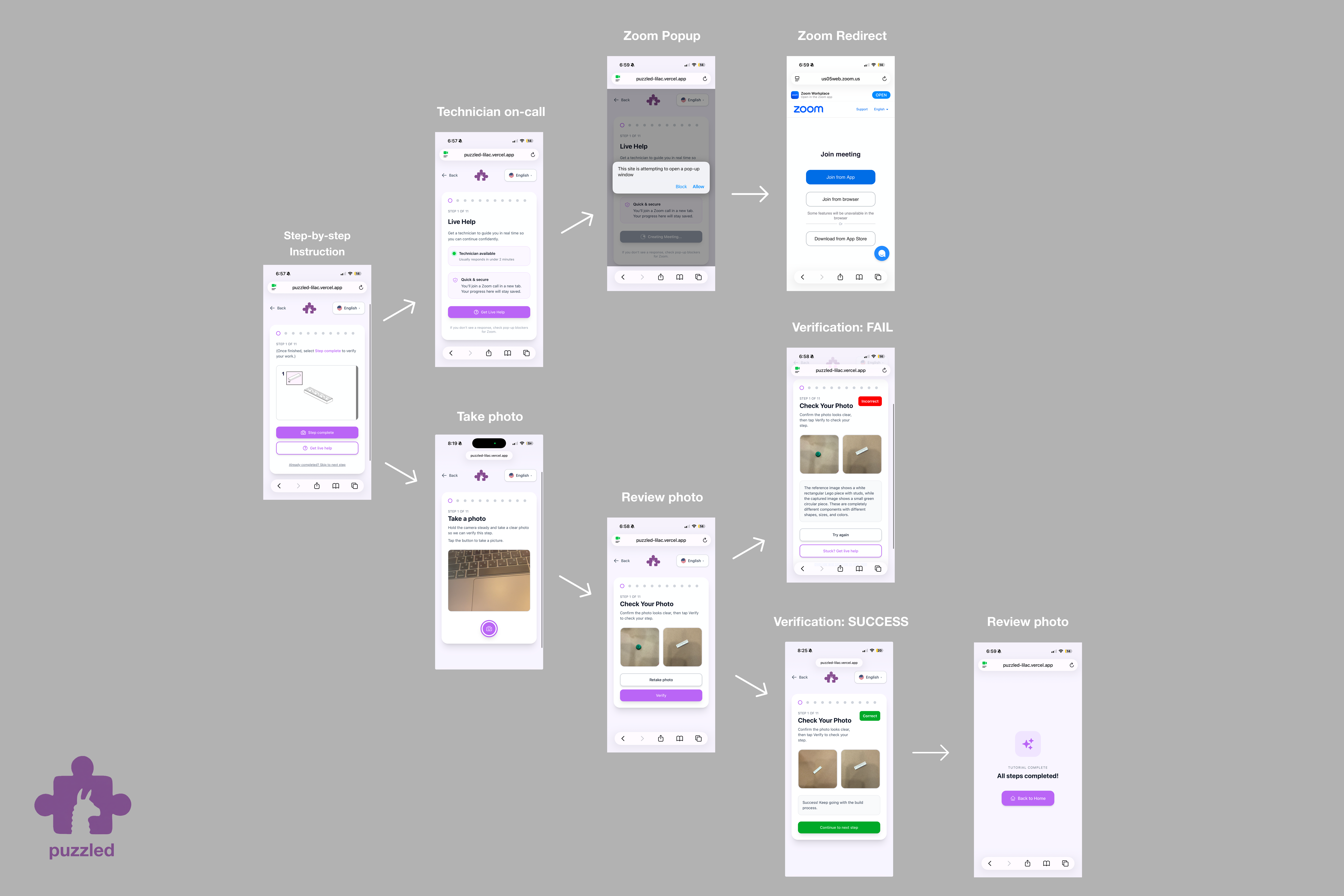
Puzzled is an computer vision powered visual repair assistant that turns any phone camera into a step-by-step repair guide.
Users can:
- Select their familiar language
- Follow guided repair steps
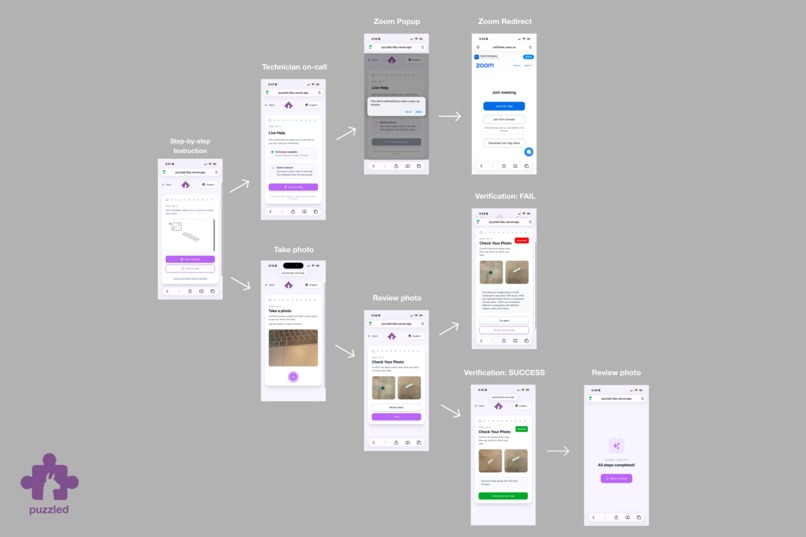
- Capture a frame to verify each step
- Escalate to live expert help if needed
- Automatically sends a support request email with a Zoom meeting link to an expert.
Instead of leaving people puzzled in front of broken medical devices, lab equipment, household appliances, or even LEGO builds, we can help them find the missing piece 🧩— step by step.
How we built it
Our app begins with a puzzle. When the final piece (our logo, featuring the adorable Treehacks llamas 🦙!) clicks into place, the screen transitions to language selection, our first page. Once a user selects a tutorial, our system uses computer vision to analyze their image at each step to check for validity and provides real-time feedback.
The following details our tech stack:
Frontend
- React + TypeScript + Tailwind for a mobile-first interface and camera integration
Backend
- Python (FastAPI) for REST API serving verification endpoints and image processing
- Runpod (GPU inference):
- Deploying of Siamese neural network endpoint through runpod, reducing inference latency to <100ms for high-volume production use
- Deploying of Claude Vision API
- Supabase for BaaS, database and storage for images of tutorials and repair steps
AI & Intelligence
- MyMemory Translation API for multilingual translation
- i18next for frontend internationalization and language detection
LightWeight On Device Verification:
- Siamese architecture: REsNet18 backbone pretrained on ImageNet
- Heavy data augmentation: +-50% brightness/contrast, 180° rotation, random flips
- CLAHE (Contrast Limited Adaptive Histogram Equalization): Normalizes lighting variations across different environments
- Comparison: Cosine similarity between embeddings (threshold: 0.81)
- Center crop (15%): Removes edge noise and focuses on center of assembly
- 99.8% similarity on matching steps in test
- Clear rejection (51-67%) on non-matching steps
Advanced Model with Feedback:
- Claude Sonnet 4 Vision API for frame analysis and step verification
- Gives useful insights about what is wrong with the image (helpful if you're unsure what's wrong)
- Similar performance to Siamese network
Both models have an advantage of not needed large amounts of data, making it easy for people to crowdsource help for repair of medical equipment without investing significant time in curating ML datasets.
Integration
- Zoom API for live expert escalation and support
- Vercel for frontend deployment and hosting
Challenges we ran into
- Database implementation (expected it to take 5 minutes. Ended up taking waayyyy longer)
- Zoom API with Render backend. Yeah this one was difficult. It turns out the WiFi was our bottleneck and our request would time out often.
- Occasionally, some steps would do perform worse than others during the AI analyzation due to varying alignment or lighting
- Providing support for more languages for translation as each was computationally expensive while maintaining good performance on latency
- Developing a complex but intuitive user flow (back button, help button, verifications, etc)
Accomplishments that we're proud of
- Training a neural network with only 2-3 images per step. Although it seemed impossible, we solved this by choosing a Siamese architecture (learns similarity, not classification) and aggressive data augmentation (25x expansion with rotation, brightness, blur variations).
- Overcoming Lighting Inconsistency: Early tests failed when images had different lighting than our reference images. We implemented CLAHE preprocessing and trained with ±50% brightness augmentation to help the model be more lighting-invariant.
What's next for Puzzled
- Auto-checks for step completion
- Rather than manual photo capture, we hope for an accurate CV detection via real-time camera
- AI-created visual instructions
- Users can view their difficult text-only manuals as step-by-step visual guides.
- Medical admin portal
- A platform for hospitals and manufacturers to upload manuals and convert them into interactive workflows.
- Providing support for more languages
Right now, Puzzled supports a wide range of assembly workflows. In the long run, we hope to specialize it in medical equipment repair, advancing our computer vision to detect fine parts and guide important fixes!
References: (1): https://www.who.int/data/gho/indicator-metadata-registry/imr-details/4584 (2): https://cdn.who.int/media/docs/default-source/medical-devices/health-technology-management/country-data-on-health-technology-management.pdf?sfvrsn=4c8eefbb_3&utm_source=chatgpt.com (3): https://pubmed.ncbi.nlm.nih.gov/28821280/
Built With
- claude-sonnet
- python
- react
- render
- runpod
- supabase
- tailwind
- typescript
- zoom








Log in or sign up for Devpost to join the conversation.