-
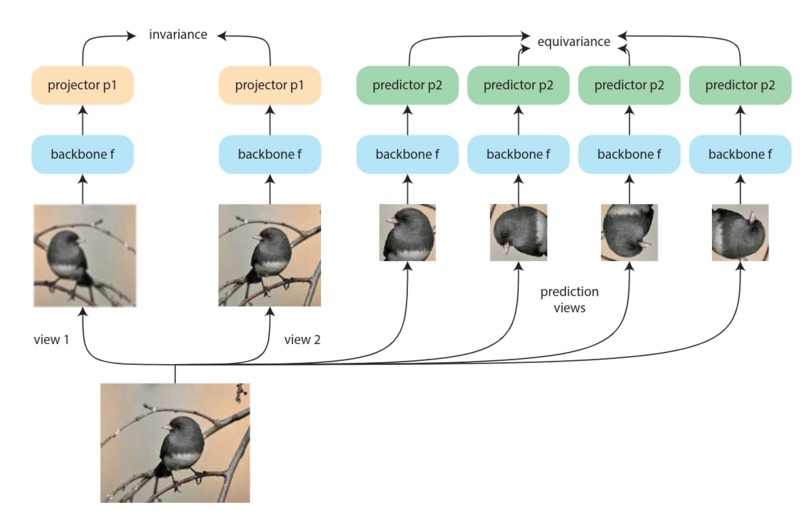
Overview of equivariant contrastive learning, figure taken from Dangovski et al. 2022
Inspiration
Contrastive learning is an unsupervised pre-training framework that encourages networks to produce semantically "good" representations of data. Intuitively, it works by teaching a network to see a datapoint in the same way after performing some random sequence of augmentations on the point. For example, blurring an image to a certain degree changes some aspect of the image, but it does not change the identity of the image. This property of insensitivity to transformations is formally known as invariance.
In Equivariant contrastive learning, Dangovski et al. 2022 propose an extension to contrastive learning, based on the notion that certain transformations actually do change the meaning of the data, and that networks should be invariant only to those semantics-preserving transformations. For example, in the jigsaw puzzle challenge, rotating the image actually changes its ground truth label, but distorting the color does not. By adding an additional loss term for predicting four-fold rotation to the standard contrastive loss, we are able to better capture what the model should be sensitive or insensitive to, hence the term "equivariant". After pre-training, we can more efficiently train a vanilla CNN classifier on the jigsaw puzzles, by freezing the actual encoder weights and propagating gradients only to multi-layer perceptrons.
How we built it
My submission is based largely on the code associated with Dangovski et al. 2022. Minimal adaptations are made to the code, to handle the jigsaw dataset instead of imagenet. Please see my github repo for correct requirements and usage instructions.
If I could go back in time...
- I wouldn't forget to pad images so that edges are preserved prior to entering the network. I forgot that default ImageNet transforms perform a resize and centercrop operation...
- I would incorporate a strong heuristic/binary classifier to detect corrupted v.s. uncorrupted images, and ensemble its predictions with the output of the resnet50 classifier. Since the model I trained achieves 95% top-5 accuracy but 65% top-1 accuracy, a simple classifier to pick the "uncorrupted" image out of the top 5 predictions would probably lead to great performance.
- I would leave more time to submit, so that my requirements files and submission structure isn't incorrect. Sorry @TAMUDatathon :')

Log in or sign up for Devpost to join the conversation.