-
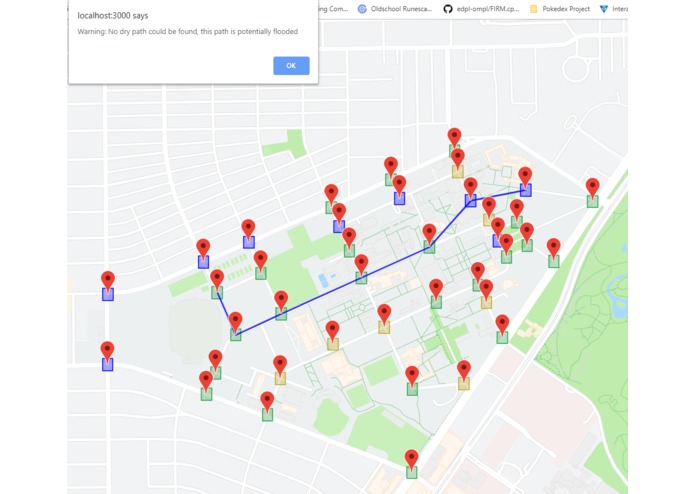
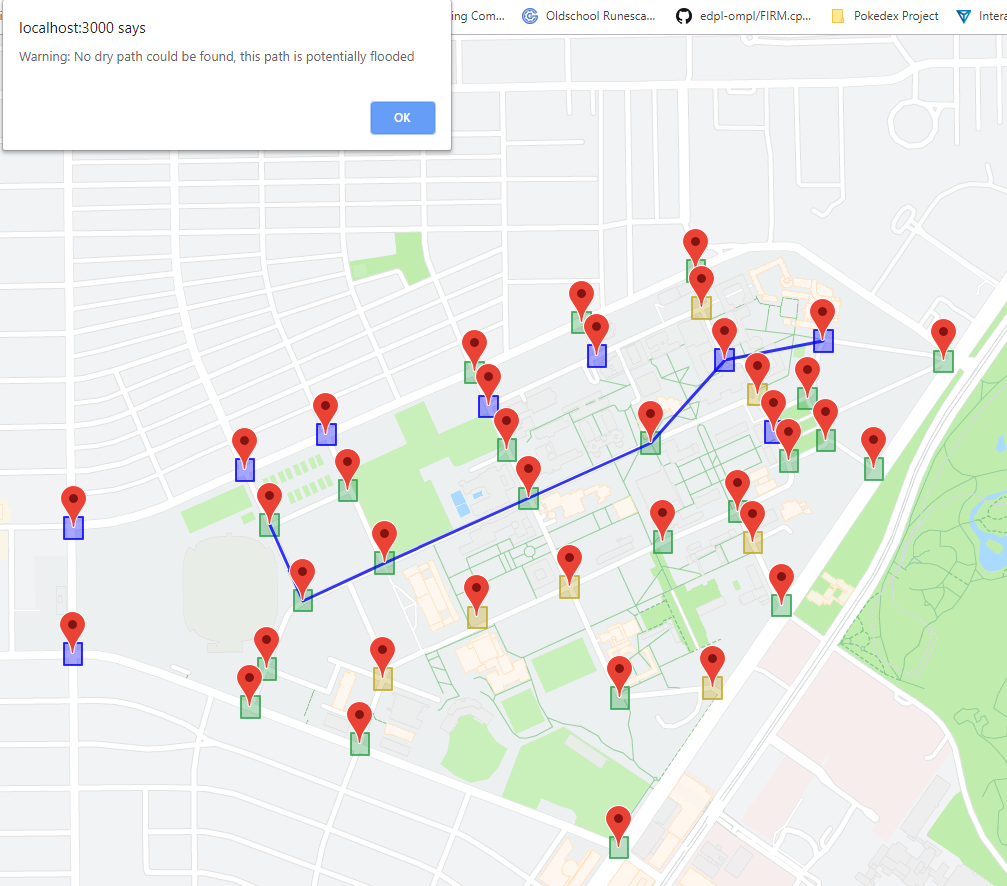
Alert that pops up when no dry path can be found, along with a wet path.
-
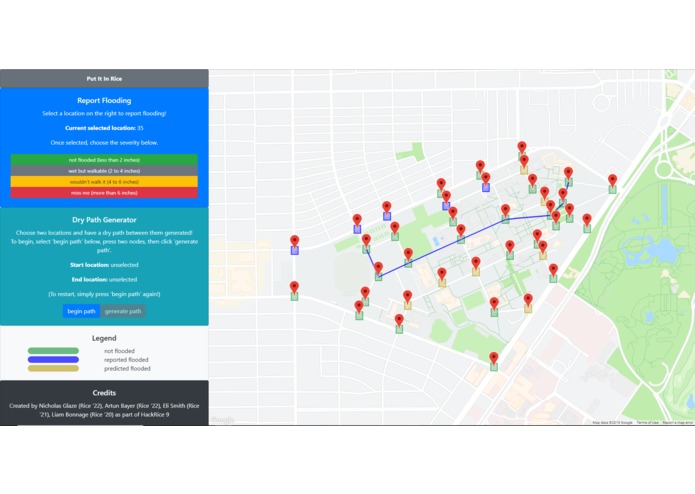
Website interface, with the shortest dry path between two nodes shown.
Inspiration
Imagine that you're a Rice student, and that an especially big storm (e.g. Imelda) is currently hitting campus. As it stands, there would be no easy way to know which parts of campus are flooded. If you're trying to get from one place on campus to another, you'd have to brave the weather, with no way of knowing what parts of campus are flooded beyond Rice's occasional "flooding somewhere on campus!" messages.
Our project solves this problem. With user-reported data, we aim to help students stay safe and (somewhat) dry during storms. In particular, we aim to help OC students get on and off campus safely by providing advanced prediction capabilities for flooding at Rice's many entrances.
Furthermore, once trained, our models could be can to learn Rice's flooding patterns, so administration can be better prepared to handle flooding events on a campus-wide level.
What it does
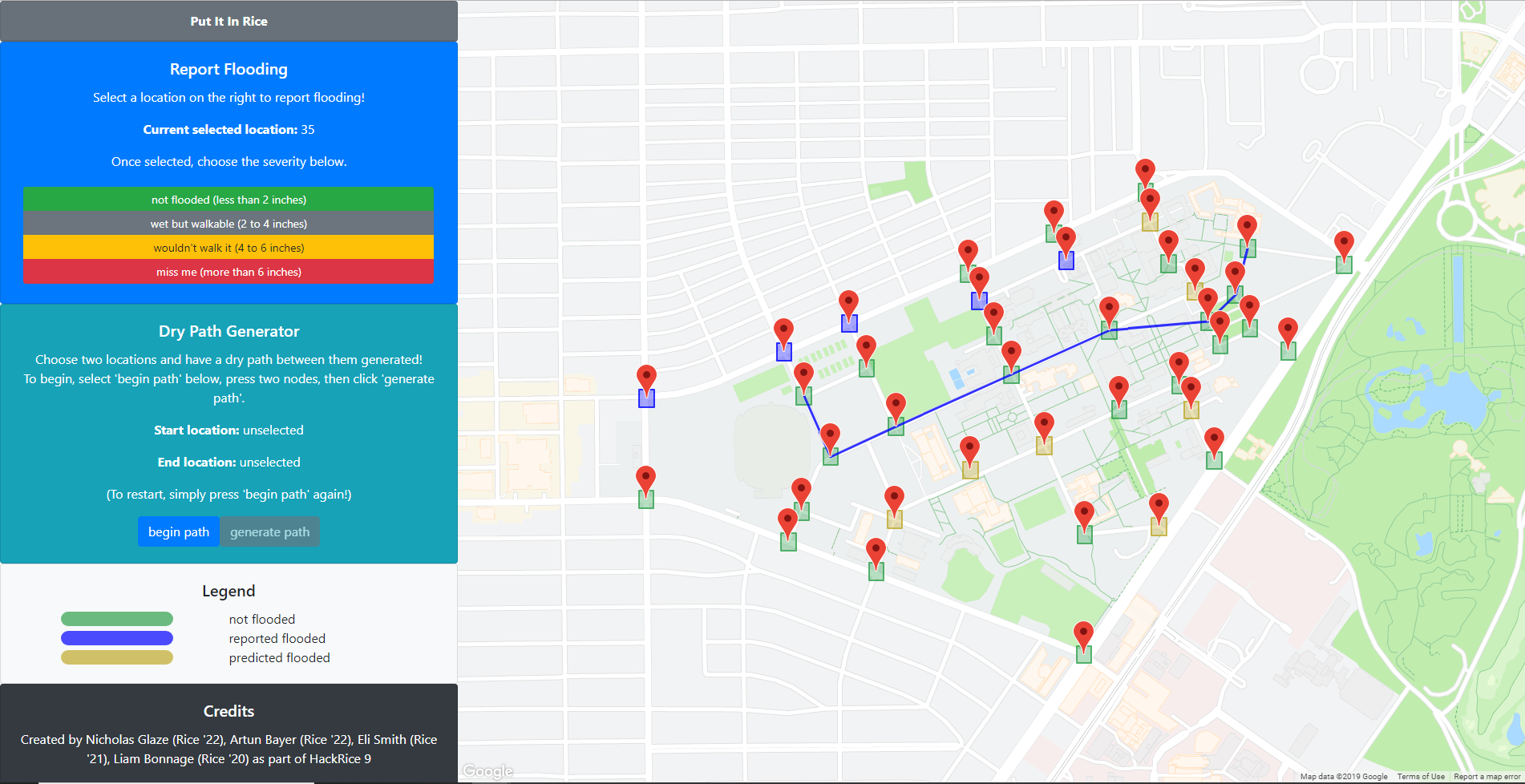
When a student goes to the website, they'll see a map of Rice with lots of markers placed around campus. Each marker will have a colored box under it, indicating the reported status of that spot: green for not flooded, blue for reported flooding, and yellow for predicted flooding (more on that later).
Flood reporting:
When they click on a marker, they'll be given the option to report what level of flooding they currently see at that spot on campus (no flooding, wet but walkable, etc.) Their report will be saved into our database, and the localized flood level is updated according to the average of all of the current day's reported water levels at that spot. If the average water level is above our threshold for "flooded" (currently 4+ inches)
Flood prediction: One classic challenge with user-reported data is that sometimes, users won't report enough data at a marker for its flood level to be accurately represented. This would especially be a problem at some of Rice's entrances, where not as many students would be. However, these nodes are some of the most critical for OC students to know the status of, since they'll want to know which entrances are safe to get in and out of campus through.
We account for this with two models: an XGBoost model, trained for the more critical, but less traveled nodes (entrances), and a basic linear model, trained for the rest of the nodes.
-Linear model: Using a weather API, we will access precipitation from all of the past days that people have reported flood levels for. Then, using our old user-reported data (generated data for now), we will regularly train a set of thresholds for our nodes, each corresponding to the amount of rain needed to flood that node.
The linear model won't always be as accurate, so we also implemented an XGBoost model, trained on only some of the nodes to preserve memory. -XGBoost model: One trained per node. Given the flood statuses of every other node, predict the flood status of the node for which the model is trained. Trained using our generated data; over this data, all of the models we trained were incredibly accurate (95%+).
Path finding: Students can also use the website to find the shortest dry (non-flooded) path from one spot on campus to another. By representing the markers as nodes in a graph, connected by edges to nearby nodes, we allow the user to select any two nodes on the graph; our website will then compute (using Dijkstra's) and output the shortest dry path (if one exists), or the shortest wet path (along with a warning), if no dry path exists.
How we built it
Database: mongoDB cluster Flood prediction: XGBoost, Random Forest, networkx (for graphs) Server: Python Flask Website: ReactJS
Challenges we ran into
-Creating the best graph structures (where to place nodes, which edges to draw) -Creating representative training data -Choosing appropriate website packages -Exposing correct data from mongoDB database -Prioritizing the best features to implement
What's next for Put it in Rice
-Viewing historical and predicted future flooding data -Hosting our website on the cloud -Press any location, not just nodes
Built With
- javascript
- python
- react
- sklearn
- xgboost

Log in or sign up for Devpost to join the conversation.