-
-

Welcome to the PupLife Games!
-

The main game menu.
-

The game areas around the central arena display a popup outlining the intended functionality.
-
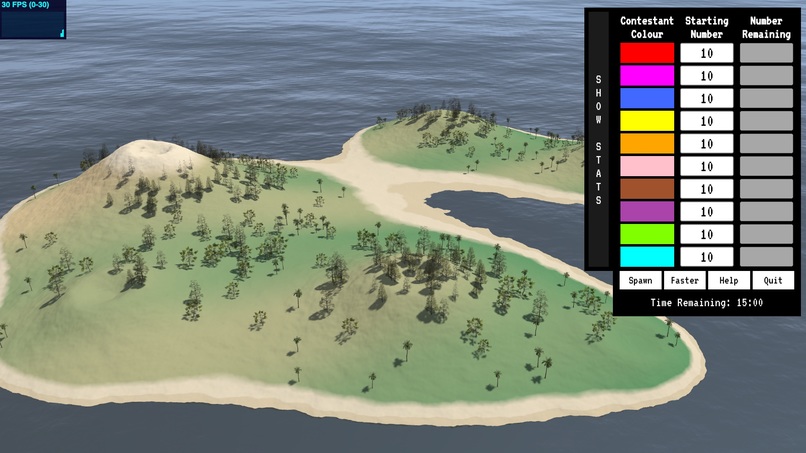
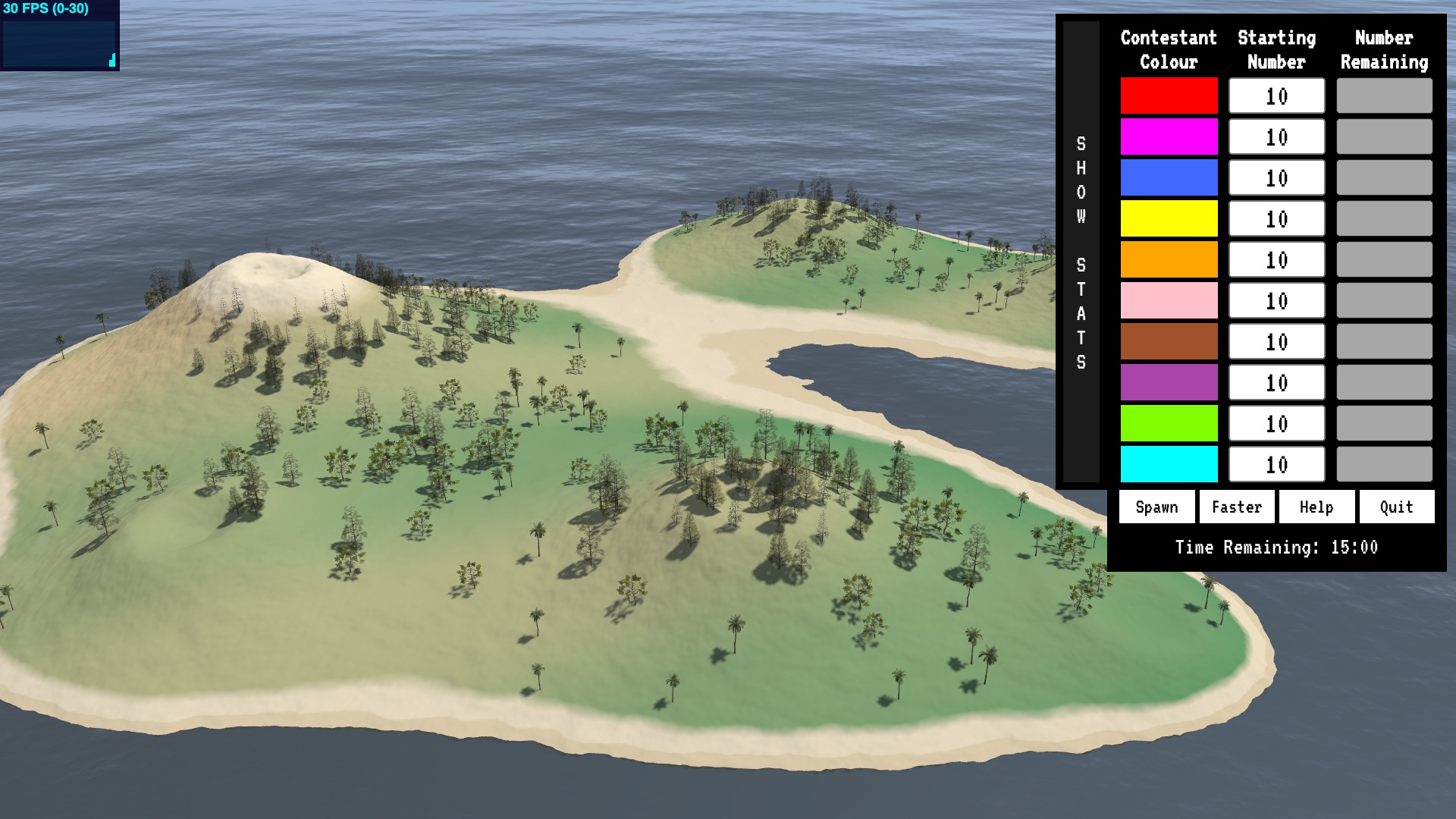
The arena.
-

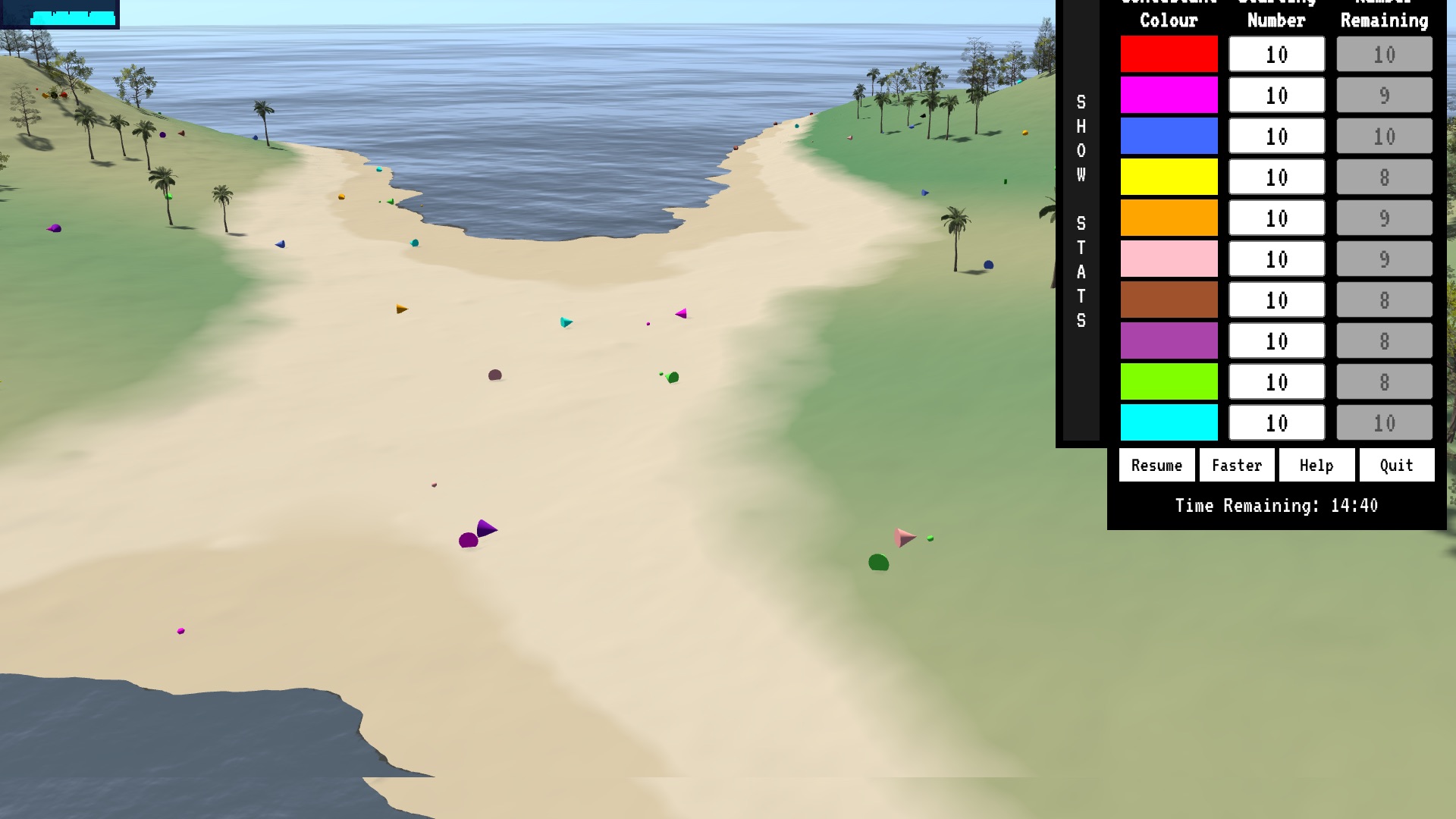
Contestant stats showing.
-
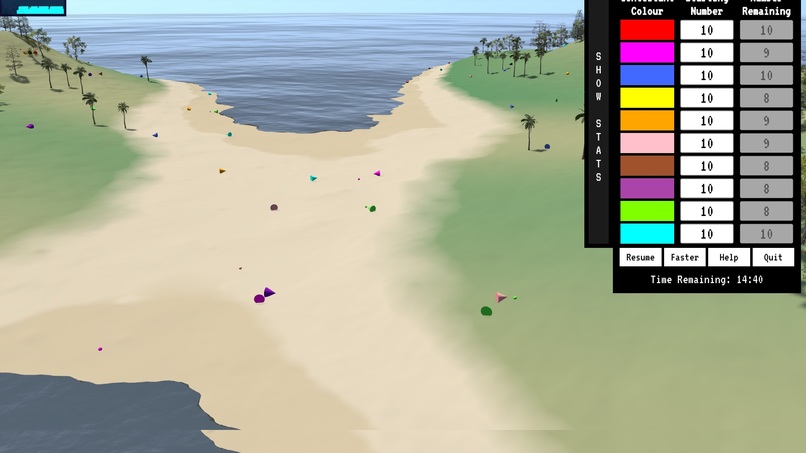
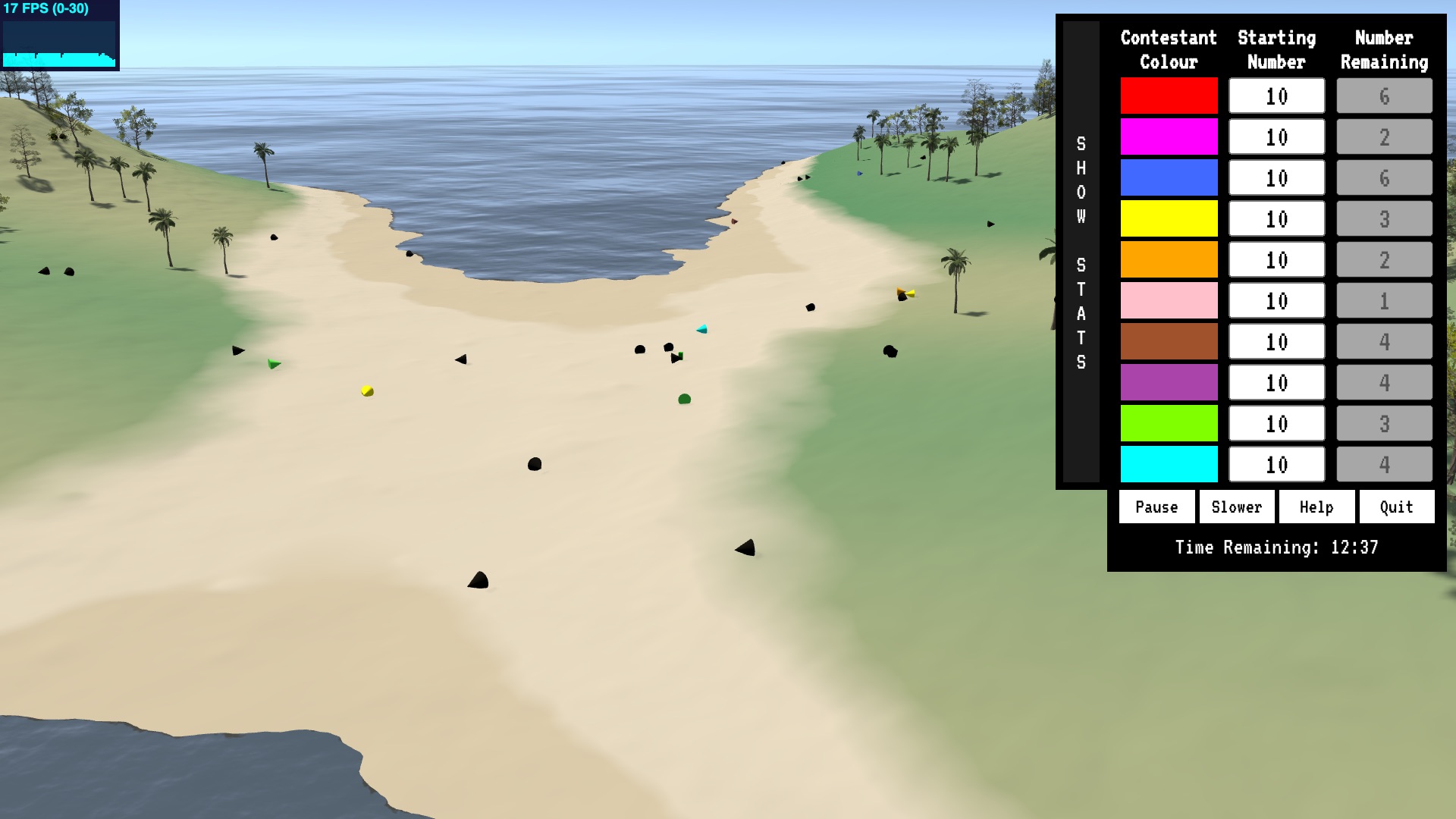
In the heat of battle.
-
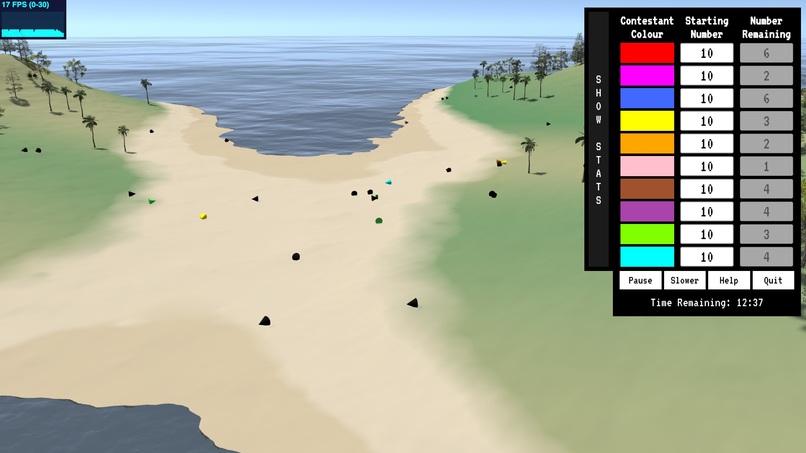
Dead bodies litter the battlefield.
-
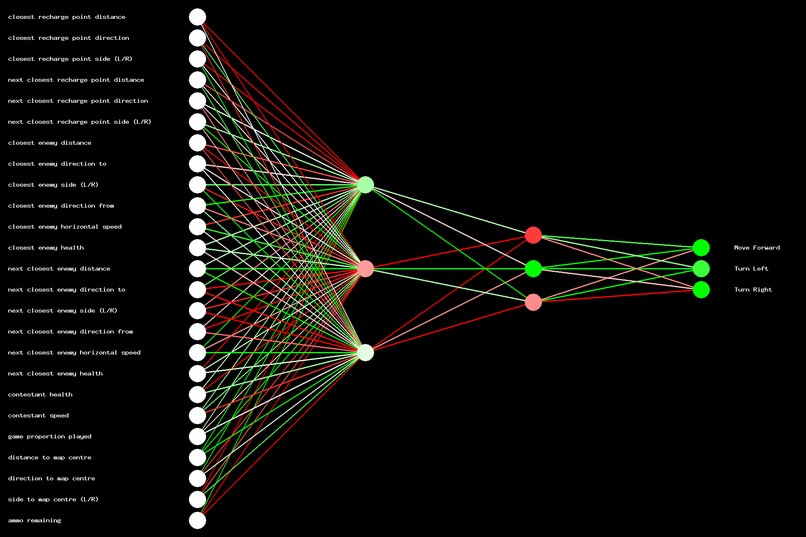
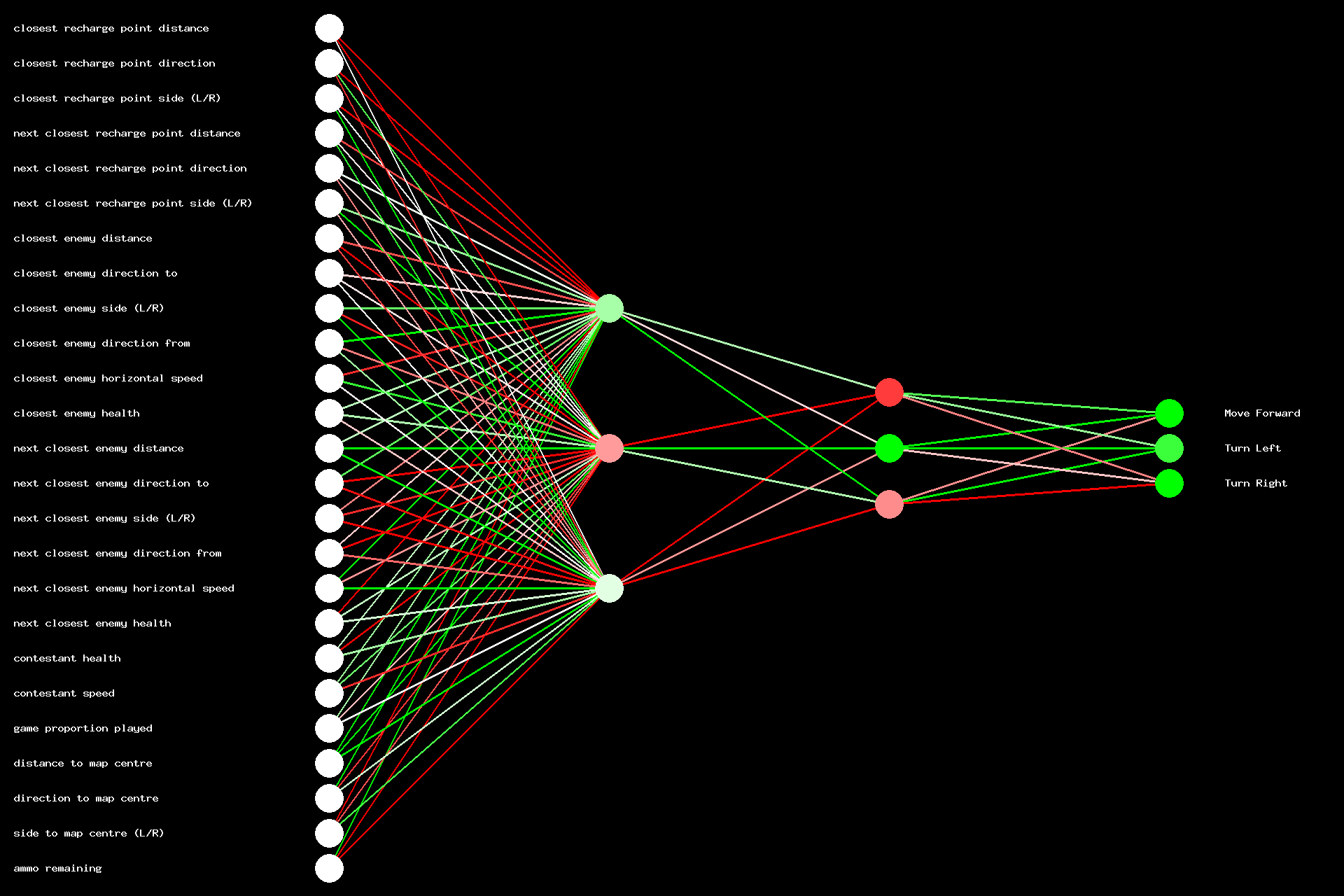
Contestant number 10's primary neural network after training.




Inspiration
The PupLife Games were inspired by some of our favourite game genres, a decades-long passion for AI, and a more recent discovery of the delights of NFTs and the Theta blockchain and community. Add in some some fun and easy play-to-earn mechanics and you have something pretty unique in the gaming space.
AI is set to revolutionise just about everything. It already is. From reading the news for you, to writing your code, drawing the images for your NFT collection, and in a plethora of other ways, AI is helping us save the most precious commodity of all. No, not TFuel. Time.
And with the PupLife Games, AI is set to save you even more. Because in the PupLife Games, you don’t even play the game. We’ve got the AI doing that for you. That’s why we’re calling it a 3rd person game. You, the player, can just sit back and watch. Or spend time with the family, or in nature, or whatever. It’s your time.
What it does
This hackathon version of the PupLife Games is not a complete game. It is a proof of concept of the AI architecture and training method, and we hope the response from the community when they see just a tiny fraction of our vision in action will be sufficient to fuel development of the remainder of the game.
But indulge us as we take a moment to paint a bigger picture by outlining the core features of the game as we envisage it.
We wanted to build a game that would be playable on any device at any time, whether you had a few seconds or a few hours.
We wanted to capture some of the thrill and excitement of a first person shooter but without requiring the time commitment to actually learn to play (let alone the desire).
We also wanted a game that had a lot of depth to it. Role-playing games, where players build characters, level them up with experience, provides an appealing journey that we wanted to incorporate in the PupLife Games.
And finally we wanted a variety of play-to-earn opportunities, that would suit a variety of player types. We are building an entire economy around the PupLife Games so there should be something for everyone.
For the game itself, there’ll be breeding, training, a marketplace and other features. Then there’s the arena where the games will take place.
Your job is to breed, train and equip the toughest contestants. Gain experience in the games to level up your character (you choose the level up path you want to take) making them faster, stronger, or more intelligent. With eight attributes based on a combination of breeding and experience there’s a lot of room to experiment with different character types.
As your character advances you will be able to participate in higher level tournaments where the best contestants will be able to win prizes.
Not everyone will want to be that involved, and that’s perfectly fine. If you want to dominate in the games perhaps someone who has done the work may be willing to part with a prebuilt character on the marketplace — for the right price. All contestants are NFTs on the Theta blockchain, and all characteristics including their DNA, attributes, level ups, and achievements will be stored on the blockchain itself.
What if you’re not interested in gaming, but just want to make passive income on your NFTs with as little effort as possible? We’ve got you covered too! From staking, which is already active (using 2023’s Theta hackathon runner up SmartStake) to crafting and forging items for in game use, breeding, or trading on the marketplace.
The Arena
The arena is where the action takes place. Games are located on a remote island. Up to 100 contestants are dropped onto the island in random locations and have 15 minutes to survive and try to eliminate as many of their fellow competitors as possible. Contestants will additionally need to recharge health and ammo by seeking out and moving over active recharge points.
Players (that is, people) will be able to affect play by various means such as airdrops or other external influences. These interactions will have a small cost and there will be limits, but it’s an extra option available to players who want to be more involved in the games experience.
The games themselves are currently a proof of concept. We’ve developed a basic 3D island upon which the action takes place. As yet we haven’t decided for certain what type of arena the game will launch with, and multiple arenas are possible in future, with new arenas becoming available as characters level up.
For now it’s just a bit of fun to visualise the action. The graphics are all basically placeholders and haven’t been optimised for display purposes. We built it with Javascript and Three.js in the front-end and node.js in the backend to conduct the training.
Update: We took advantage of the final week by which the hackathon deadline was extended to implement a "level of detail" algorithm for the terrain, which shows more detail close up and less in the distance. This one improvement resulted in a more than 97% decrease in the number of triangles needed to render the terrain (from over 8 million to around 200k), which has had a noticeable positive impact on performance! Plus, it leaves a large triangle budget for individual character models to be added in future. We added a "SHOW WIREFRAME" button to the UI that will show the current terrain geometry, for those who are interested in such things.
At the present time there are ten pre-trained characters available. Each character has four attributes which can be either high or low. In the final game the attributes will differ somewhat and will have values from one to 20. The purpose of the present implementation is to highlight how differences in the attributes leads to differences in performance in the games.
The AI
In the game, all contestant behaviour is completely deterministic, being based on the output of each contestant’s neural networks. The only randomness at present is in the initial placement of contestants at the beginning of the game.
Each contestant has two neural networks that are trained at the same time but are otherwise independent of each other. The size of these networks differs, depending on whether the corresponding attribute is low or high. One network (governed by the Intelligence “Int” attribute) is used to control movement (with left, right and forward outputs) and the second network (governed by the Targeting “Tgt” attribute) is used to determine if the character should shoot or not. We’ll discuss some more details about the neural networks themselves in the next section.
When the PupLife Games launches it is expected that all contestants will be trained using the Theta EdgeCloud network. Whenever a new game character is bred, equipped with new weapons or armour, or levelled up, it will need to be retrained. The training process is computationally expensive so the Theta EdgeCloud network is a perfect solution for our requirements.
As part of this hackathon entry we looked into the feasibility of using the Theta EdgeCloud for this particular use case, and can report that creating our own Docker container and launching it using a Custom Template approach is … feasible! The only holdup at the moment is that we need an API that will allow us to start and stop EdgeCloud deployments on demand, in response to training requirements from players.
How we built it
Most of the generative learning models people would be familiar with at the moment employ a form of supervised learning. Supervised learning is used when you know the results you want, and can feed the AI with large amounts of pre-existing data. Generative AI models use supervised learning.
For the PupLife Games, and many real-world tasks, a supervised learning approach is unsuitable as we don’t know what the best strategy is. As we want the AI to discover that for themselves, we use an approach known as reinforcement learning. This type of learning strategy rewards good behaviour and punishes bad behaviour.
The exact way in which we incorporate the rewards and punishments is using a genetic algorithm. We start with 100 contestants, each with the neural network weights chosen in a random fashion. We unleash them on the battlefield and then after the game is over, rank them. The contestants that performed better are selected to breed the next generation with. On each generation mutations can occur at random, and these mutations can be either positive or negative. It’s like natural selection in the wild, but much more intense and rapid.
This approach is not suitable for GPU learning, but thankfully the Theta EdgeCloud team has provided a Custom Template option on their Model Explorer that allows a custom Docker container to be launched. We adopted the approach of building a Docker image with a web server and a node.js backend with the training algorithm loaded. To train an agent, a remote connection to the web server is made and the specific training configuration specified. Once the training is complete, the results of the training can be downloaded from the web server. As mentioned earlier, we haven’t deployed this solution yet as we’re waiting on an EdgeCloud API that will allow us to programmatically start and stop deployments.
For moving around, we used neural networks with 25 inputs and 3 outputs. The more intelligent contestants had two hidden layers of three neurons each (as per the following image), whereas the less intelligent contestants had one hidden layer. The following image is a representation of the neural network of one of the more intelligent contestants. The lines are weights; red indicates a strongly negative weight, pink is lightly negative, white is zero (no influence), light green is lightly positive and dark green is strongly positive. The colour of the nodes in the hidden and output layers are biases added to the overall score from the previous layer and use the same colour coding. We’ll leave it as an exercise for the reader to figure out what it’s actually doing.

The weapon targeting neural network is a lot simpler. It just takes a few inputs — the direction and distance to the enemy and the relative speeds. As you can see from the demo, it definitely needs some improvements in places — some of those contestants have a pretty bad aim! It doesn’t help that the projectiles move slowly. We chose the current type that basically rolls along the ground because it was simpler to aim without having to consider the vertical dimension; and the slow speed is both better visually plus it puts more demands on the targeting algorithm as it has to look further ahead. In the full version of the game there will be many different types of projectiles to choose from, to suit your playing style.
Each contestant was trained for 25,000 hands in self-play, and after all ten contestants had been trained in this manner they were trained in group play for another 25,000 games each, for a total of 500,000 training games played.
Challenges we ran into
One example of just one tiny challenge was when training the combatants to use the recharge points. In the arena, after being used, the recharge point reappears after 60 seconds. During training we found that contestants developed the strategy of circling the recharge point tightly until it reappeared — an effective strategy, but not particularly interesting to watch! In this case we changed the mechanism during training so that the recharge point would respawn in a random location, so contestants didn’t learn that bad behaviour!
And that’s one of the problems with AI. They might develop strategies so good that to we humans, they’re boring! We then have to manipulate the training environment in some way to discourage behaviours we perceive as not good and encourage behaviours we like.
One way to do this is by adjusting the fitness function. This is how we measure how “fit” a contestant is. In a race, it is the place in which the runners finish that determines fitness, but in the PupLife Games this resulted in the contestant putting down their weapons and just surviving harmoniously to the end. Again, an effective strategy, but not for our purposes. We solved this one by giving them a little reward for shooting each other. One of the beauties of AI is that we didn’t have to try to get this past an ethics committee!
Another challenge was the ever present issue of variance. Due to the effects of chaos, very small changes in starting conditions can result in very large changes in end conditions. Or in other words, due to chance in the starting conditions good players can often lose to bad players, and vice-versa. This high level of variance made training players difficult because it was not easy to tell just which players were good. We would typically run at least 100 test games to evaluate the performance of a contestant, but such an expensive evaluation function isn’t feasible during training.
To reduce variance we use a variety of metrics to measure the fitness of a contestant. These include amount of health gained, number of hits, how long the contestant survived for and how many other contestants they outlasted. In future versions we will add additional fitness measures. In addition to helping during training, the same fitness measures can be used in live games to determine the winners, not simply relying on the one who survives the longest. That allows different strategies to be employed, which is an essential element of an RPG.
And finally, still on AI, the quality of the strategies developed is a concern. We experiment with larger networks but found the larger networks often underperformed the smaller ones. Our approach to training clearly still needs work, and there are a couple of avenues we can pursue next, which we’ll mention in the final section.
Accomplishments that we're proud of
We’re most proud of taking a relatively unused approach to training an AI and getting it to work in our problem domain, which is very much more complex than any of the other networks we have seen that use a similar method. It’s not perfect, but we’re proud we were able to get this far in what was a relatively short amount of time.
What we learned
The majority of the time spent on the PupLife Games throughout the course of this hackathon has been on the AI. We feel like Thomas Edison must have felt, trying to invent the lightbulb. We’ve experimented with many approaches and we’ve learned about a great many that don’t work. From things like how to represent the weights in the neural network during training, to how to best code values for input to the network, and a host of other little things that all have to be right if the AI as a whole is going to work.
What's next for PupLife Games
If there is sufficient community engagement the next step will be to formalise the roadmap. We’ll then commence work on some of the interactive non-AI elements, so that players can start engaging with the game economy as soon as possible. Crafting and Forging, Breeding, the Market Place and the Meeting Place can all be made operational while at the same time work continues on improving the AI, integrating the training into the Theta EdgeCloud network, and improving and optimising the visuals.
In terms of improving the AI, our next experiment is going to be with Directed Acyclic Graphs (DAGs), rather than fixed multi-layer networks as in the current version. DAGs will allow us to modify the network architecture dynamically during training, which could result in networks that discover better strategies and other more advanced behaviours. We’ll also be looking into the use of recurrent neural networks, in order to try to elicit behaviours that might consist of multiple elements over a period of time.
Once the game has been launched for the PupLife NFT collection we’ll look into expanding to other collections and networks. We’ve already been in talks with the RugDollz to make a version for them. They are currently using our Stakeaway product (a spinoff of SmartStake for Ethereum) to provide staking rewards for owners of over 1,500 rugged NFT collections on the Ethereum network. Our goal with cross-chain versions would be to continue running as much of the game as possible on the Theta network, while supporting NFT collections and tokens on other networks.
Clearly what we’re attempting is a large undertaking and we aren’t trying to understate the difficulty of the road ahead of us. This hackathon entry has demonstrated that the concept is feasible, and with the support of the community we will meet the challenges of implementing such an ambitious undertaking head on, one step at a time.











Log in or sign up for Devpost to join the conversation.