Inspiration
Modern payment systems must handle failure, risk, and coordination across multiple services. These behaviors are usually hidden behind simple APIs, making it hard to understand how systems actually behave under stress.
Through studying system patterns like SAGA-based transaction management, circuit breakers, and fraud scoring, I identified a gap: it is difficult to observe how these mechanisms interact in practice.
PulsePay was built to make these behaviors observable.
What it does
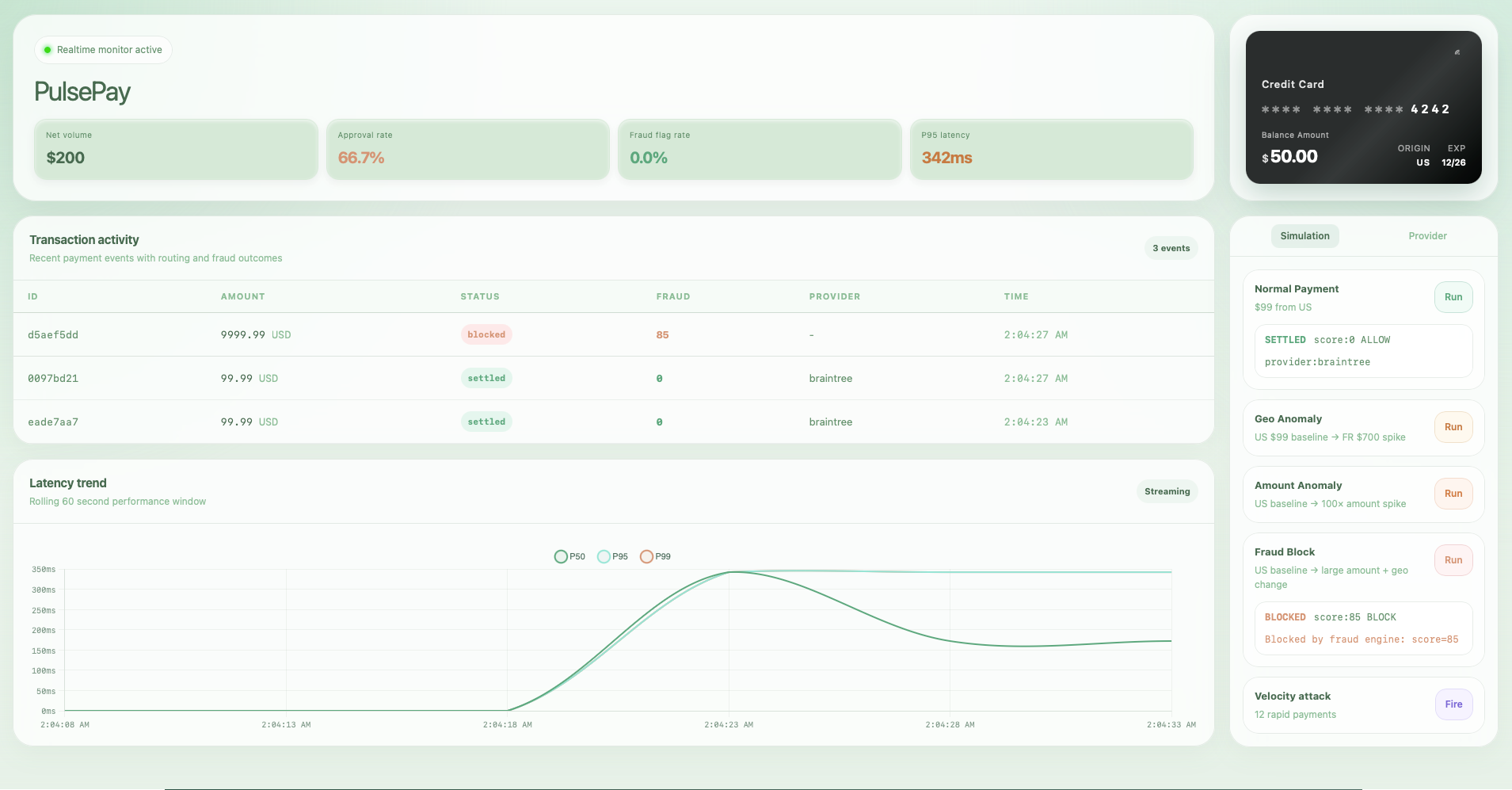
PulsePay is a payment orchestration platform that models how such systems behave under load, failure, and risk. It is implemented as a working system with a live demo and observable behavior.
Specifically, it demonstrates how a system:
- routes transactions across multiple providers with failover using circuit breakers
- evaluates fraud risk using multiple signals such as velocity, amount anomalies, and geo patterns
- coordinates multi-step transactions using a SAGA workflow with compensating actions
- maintains consistency through idempotent operations and a double-entry ledger
Practical Relevance
This system reflects patterns used in real-world payment and high-reliability backend systems.
It is applicable to:
- payment processing platforms requiring fault tolerance
- distributed systems where consistency must be maintained without global transactions
- backend systems that need to handle failures and dynamic routing
How I built it
I designed the system around common challenges in payment systems: distributed consistency, fault tolerance, and risk evaluation.
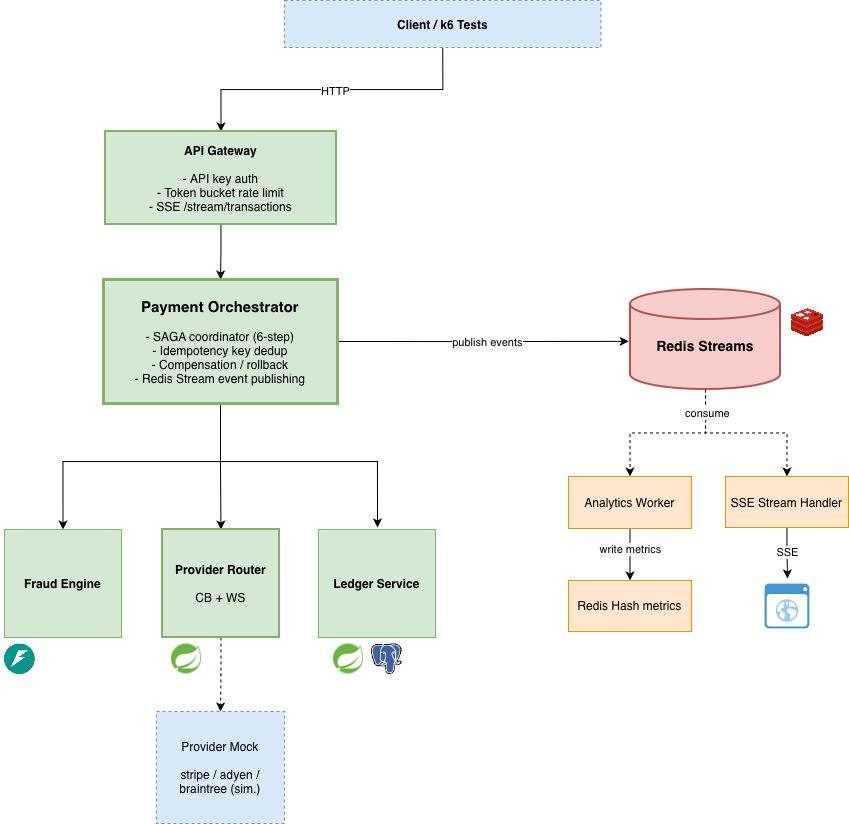
The architecture separates responsibilities across services:
- a central orchestrator manages a multi-step SAGA transaction
- a fraud engine computes risk scores from real-time signals
- a provider router handles weighted routing and failover
- a ledger ensures consistent financial state using idempotent operations
Each transaction follows a structured flow:
- risk is evaluated through a scoring model
- the orchestrator executes a sequence of steps across services
- failures trigger compensating actions instead of global rollback
- the system converges to a consistent final state
I chose an orchestration-based SAGA design to keep control flow explicit and avoid the blocking and coupling issues of two-phase commit. The system was also validated under load using k6 and failure injection to observe behavior under stress. More technical details are available in the repository README and PROJECT_DEEP_DIVE.md.
Challenges I ran into
A major challenge was maintaining consistency in a distributed system without relying on strong global guarantees.
Using SAGA instead of two-phase commit meant designing reliable compensation logic and ensuring every step was idempotent. Failures can occur at any point, so the system must recover without corrupting state.
Another challenge was handling partial failures. For example, when a provider fails, the system must detect it and reroute traffic using a circuit breaker without introducing instability.
Making these behaviors observable was also non-trivial. It required designing event streams and a clear state model so that each transition in the system could be tracked and understood.
Finally, I had to balance realism with simplicity. The system needed to reflect real-world constraints while remaining structured enough to reason about and demonstrate clearly.
Accomplishments that I'm proud of
- Implementing a SAGA-based transaction flow with compensation instead of rollback
- Designing a system that remains consistent using idempotency and a double-entry ledger
- Building a circuit breaker and routing mechanism that adapts to failures
- Creating a fraud scoring system that combines multiple behavioral signals
- Making distributed system behavior observable through event streams and a live dashboard
What I learned
I learned that correctness in distributed systems depends on design choices rather than strong guarantees.
In particular:
- consistency requires idempotency and careful state transitions
- failure handling must be built into the flow, not added afterward
- observability is essential to understand system behavior
- coordination patterns like SAGA trade simplicity of reasoning for resilience and scalability
What's next for PulsePay
Possible improvements include:
- calibrating fraud scoring using data-driven thresholds instead of fixed weights
- moving fraud evaluation to an asynchronous model to improve throughput
- expanding failure scenarios and recovery strategies
- improving horizontal scalability, especially around idempotency coordination
- enhancing analytics to better surface system-level insights
Team
Built independently.
Built With
- docker
- fastapi
- fastify
- grpc
- microservices
- next.js
- postgresql
- redis
- springboot

Log in or sign up for Devpost to join the conversation.