DeepTrends Project Story
Inspiration
The rapid pace of machine learning research presents a unique challenge for developers, researchers, and practitioners trying to stay current with the field. With thousands of papers published monthly on arXiv alone, it's nearly impossible to manually track emerging trends, identify breakthrough research, or understand the evolving landscape of ML topics. This information overload inspired us to create DeepTrends—a tool that democratizes access to research insights and makes academic knowledge more accessible to everyone.
We recognized a genuine need in the market for an intelligent system that could not only aggregate research but also analyze trends, extract meaningful insights, and present them in an intuitive, digestible format. Our vision was to bridge the gap between cutting-edge research and practical application, helping developers and researchers make informed decisions about which trends to follow and which papers deserve their attention.
What it does
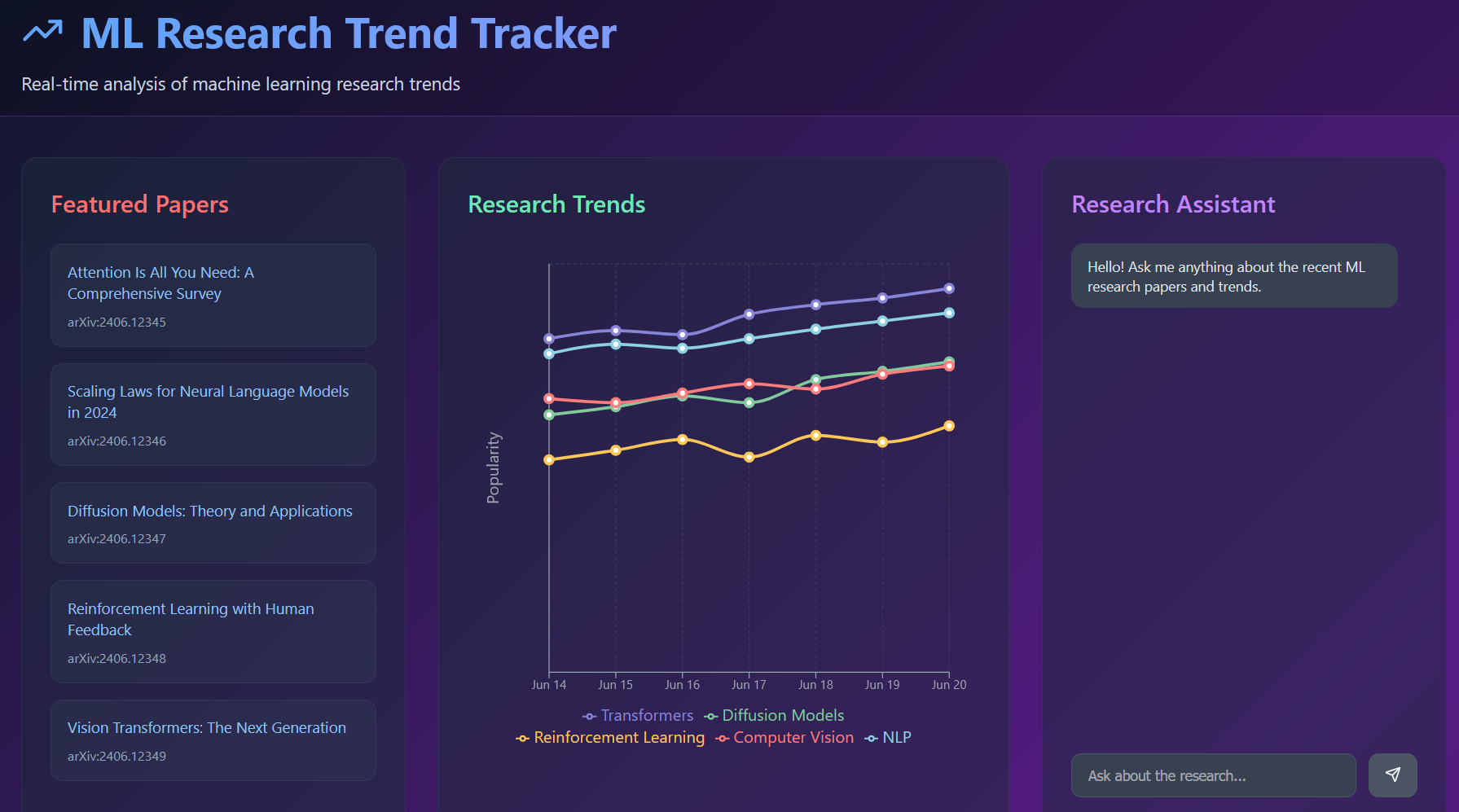
DeepTrends is an ML-powered research trend tracker that automatically discovers, analyzes, and visualizes emerging patterns in machine learning research. The platform:
- Aggregates research papers from arXiv across key ML domains including artificial intelligence, computer vision, natural language processing, and neural computing
- Performs intelligent analysis using sentiment analysis on abstracts, BERTopic for topic clustering, and keyword frequency analysis to identify trending themes
- Generates automated insights by scoring papers based on citations, author reputation, recency, and relevance to popular topics
- Creates interactive dashboards that display trend evolution over time, topic clustering, and research momentum
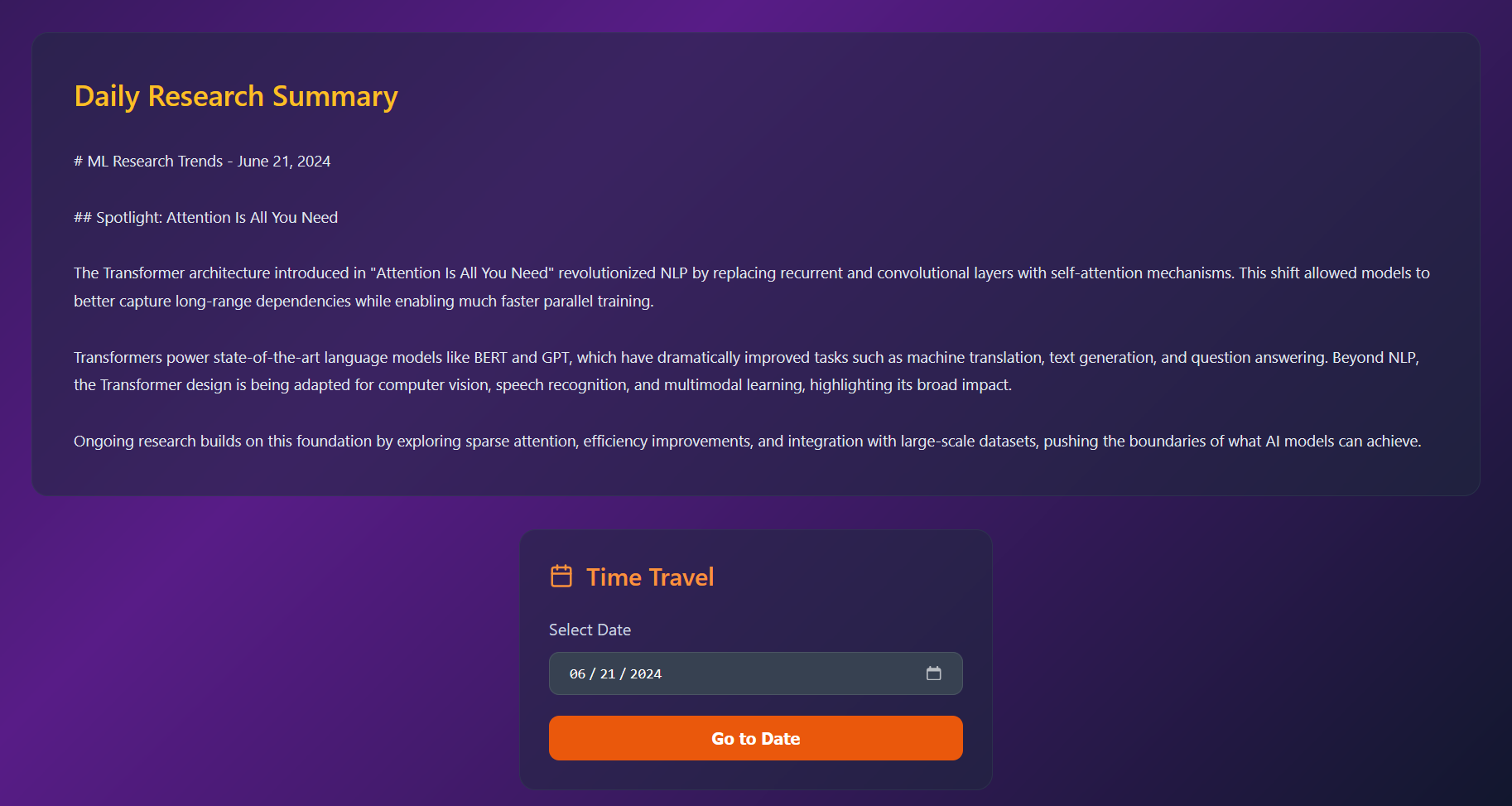
- Produces AI-generated summaries of the most significant papers and emerging research directions
- Features an intelligent chatbot powered by Anthropic's Claude that answers questions about research trends, explains paper insights, and provides contextual information about the generated blog posts
The system maintains a rolling database of the last month's papers, continuously updating to provide real-time insights into the research landscape.
How we built it
DeepTrends combines multiple technologies in a full-stack architecture:
Backend (Python/Flask):
- Built a robust data pipeline using the arXiv API
- Implemented BERTopic for semantic clustering of research topics from paper abstracts
- Integrated Hugging Face transformers for sentiment analysis of research content
- Created a scoring algorithm that weighs papers by citations, author impact, recency, and topic relevance
- Used SQLite for efficient data storage and retrieval
- Developed a Flask API to serve processed data to the frontend
Frontend (React):
- Created an interactive dashboard using React with modern UI components
- Built dynamic data visualizations and trend charts
- Implemented responsive design with CSS and modern styling
- Built real-time data fetching and display capabilities
AI Integration:
- Leveraged Anthropic's Claude API for generating intelligent summaries and insights
- Built an interactive chatbot interface that answers user questions about research trends and paper details
- Implemented a sliding window chat system for context-aware content generation
- Used LangChain for document processing and management
Data Processing Pipeline:
- Automated paper collection from specific arXiv categories
- Real-time trend analysis using frequency counting and semantic similarity
- Temporal analysis to track topic evolution over time
Challenges we ran into
Web Development Complexity: As a team with stronger ML backgrounds, we faced significant challenges in full-stack web development. Learning React, managing state, and creating responsive UI components required extensive research and iteration.
Styling and Design: Working with CSS and achieving a professional, intuitive interface proved more challenging than expected. We had to balance functionality with aesthetic appeal while ensuring cross-browser compatibility.
Import Management: Coordinating dependencies across Python backend libraries (BERTopic, transformers, Flask) and JavaScript frontend packages led to numerous compatibility issues that required careful debugging.
API Integration: Properly connecting the Flask backend with the React frontend, handling CORS issues, and managing asynchronous data flow presented ongoing technical hurdles.
Data Processing Scale: Processing large volumes of arXiv papers in real-time while maintaining responsive performance required optimization of our algorithms and database queries.
Accomplishments that we're proud of
Elegant User Interface: Despite the web development challenges, we created a clean, professional-looking dashboard that effectively communicates complex research trends in an intuitive way.
Successful arXiv Integration: We mastered the arXiv API and built a robust system that reliably extracts and processes thousands of research papers.
Advanced ML Pipeline: Successfully implemented sophisticated NLP techniques including BERTopic clustering and sentiment analysis to extract meaningful insights from academic text, plus an intelligent chatbot that makes research insights accessible through natural conversation.
End-to-End Functionality: Built a complete system that takes raw research papers and transforms them into actionable insights, from data collection through visualization.
Problem-Solving Resilience: Overcame numerous technical obstacles through persistent debugging, creative solutions, and effective collaboration.
What we learned
This project provided extensive learning across multiple domains:
Full-Stack Development: Gained hands-on experience with modern web development, including React component architecture, state management, API integration, and responsive design principles.
Team Collaboration: Learned effective strategies for coordinating work across different technical specialties, managing version control conflicts, and integrating diverse code contributions.
Machine Learning Applications: Deepened understanding of practical NLP implementation, from theoretical knowledge to production-ready systems handling real-world data.
System Architecture: Developed skills in designing scalable data pipelines, managing database operations, and creating efficient data flow between system components.
User Experience Design: Appreciated the complexity of translating technical functionality into user-friendly interfaces that effectively communicate insights.
What's next for DeepTrends
Expanded Data Sources: Integrate additional academic repositories including Google Scholar, Semantic Scholar, PubMed, and major conference proceedings to provide comprehensive research coverage.
Social Intelligence: Monitor ML discussions across social platforms like Twitter, Reddit's r/MachineLearning, and LinkedIn to incorporate community sentiment and real-world impact into trend analysis.
Predictive Analytics: Implement time series forecasting using Prophet or ARIMA models to predict emerging research directions before they become mainstream.
Advanced Visualization: Create interactive heatmaps, research calendars, and topic evolution networks to provide deeper insights into how research themes develop and interconnect over time.
Enhanced Analysis: Expand beyond abstracts to analyze full paper texts where available, providing more nuanced understanding of research contributions and methodologies.
Community Features: Build author impact profiles, citation networks, and collaboration patterns to help researchers identify key contributors and potential partnerships in their fields.
Personalization: Develop user profiles that learn individual research interests and provide customized trend recommendations and paper suggestions.






Log in or sign up for Devpost to join the conversation.