Inspiration
Our teammate Kenil got LASIK. He came out of it with a permanent dark spot in his vision that nobody had told him to expect. He was given statistics beforehand, the way every patient is, but no one who had actually lived through that specific outcome ever got the chance to tell him what it was really like, or whether it fades, or how to think about it.
That's the gap we wanted to close. Before an elective or irreversible procedure, people are told probabilities. What they actually want is a real person who's been through it, telling them the truth.
What it does
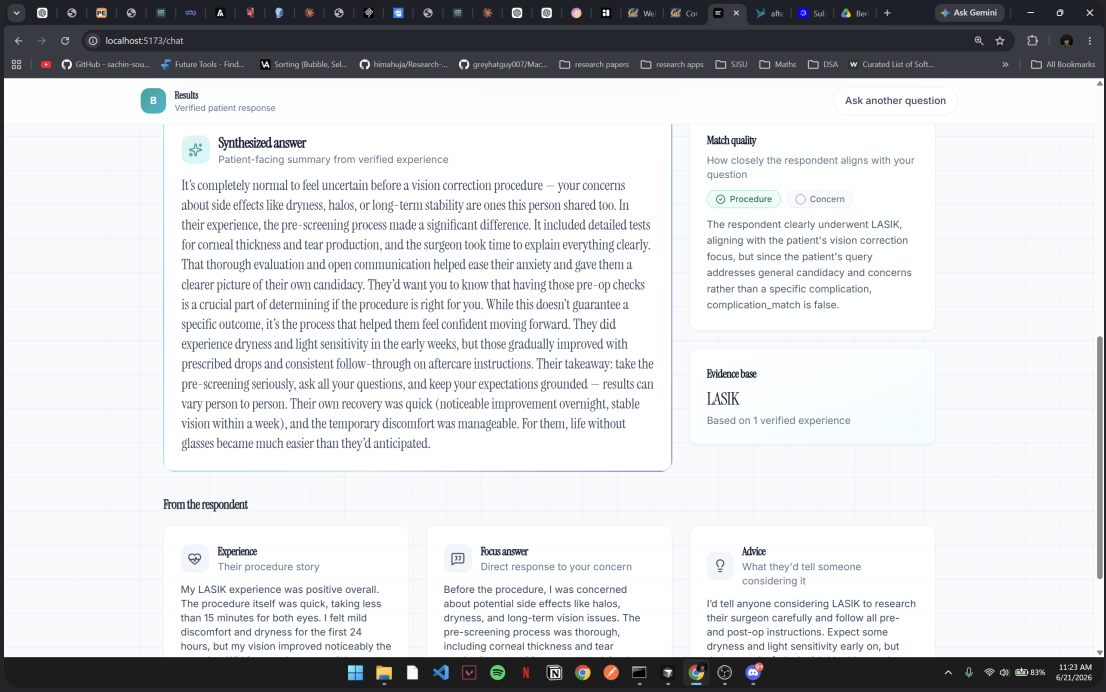
A patient uploads their pre-surgery consult notes, the actual document their doctor gave them. Pulse AI reads it, pulls out the procedure and the patient's specific concern, and launches a real study on Terac targeting people who've genuinely had that exact procedure. While it waits for a real, verified respondent, the agent doesn't guess or generate a placeholder answer. It pauses, durably, for as long as it takes, then resumes the moment a real account comes in. The response a patient sees is built from that real person's actual words, clearly scoped to how closely their situation matches the patient's own, and never inflated into more confidence than the sample size actually supports.
If \( n \) is the number of verified respondents behind a given answer, Pulse AI always shows \( n \) explicitly rather than letting a single account read as a general outcome. Right now \( n = 1 \) for every answer, and the product says so.
How we built it
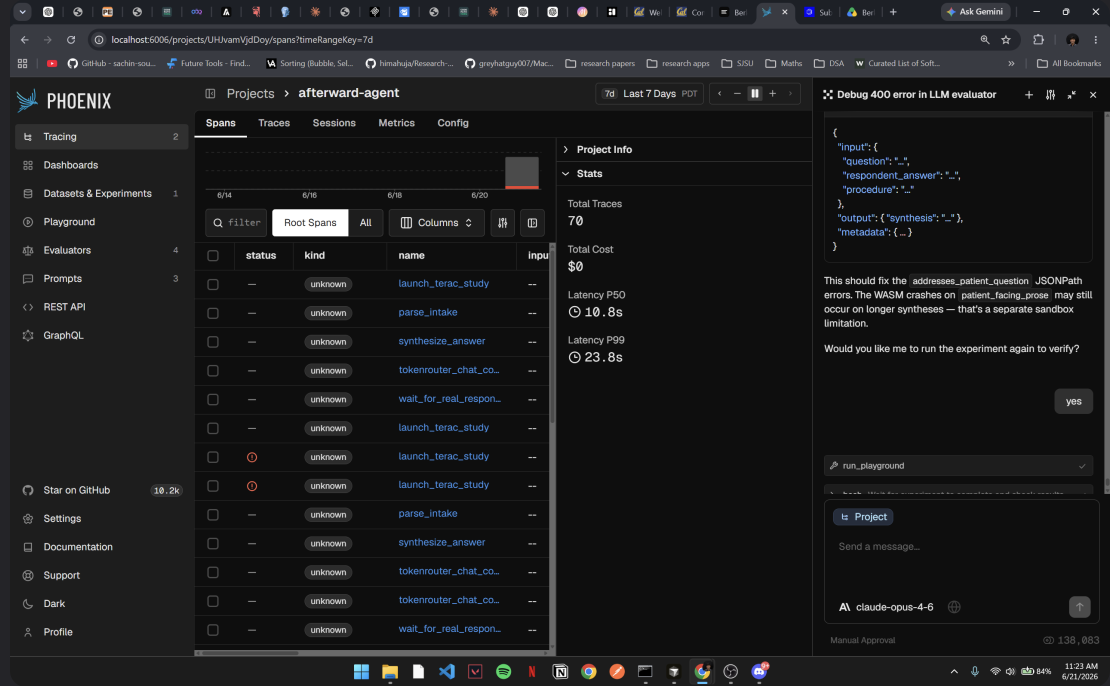
The core is an agent built on Agentspan, Orkes' durable execution SDK, structured as a sequence of tool calls: parse the intake document, launch a Terac study, pause and wait for a real respondent, check how well that respondent's situation actually matches the patient's question, synthesize an honest answer, then log the run for evaluation. The pause step is the part we cared about most. Real human response time can't be forced into a few seconds, so the workflow has to survive that gap without losing the original question or any prior step's output, which is exactly what Agentspan's approval-gated tools are built for.
Every model call in the pipeline runs through PaleBlueDot's TokenRouter rather than a single hardcoded provider, so cheap extraction steps and careful patient-facing writing each get routed to an appropriately sized model, with automatic failover if a provider has an issue. Every completed run is traced through Arize Phoenix and logged for evaluation, with the explicit goal of catching one specific failure mode: the AI claiming something a real respondent never actually said.
Challenges we ran into
The honest one is selection and matching, not infrastructure. Two people who've had the exact same procedure can have completely different experiences, so a system that just hands back any matching respondent's story risks implying relevance that isn't there. We built an explicit match-quality check for this rather than papering over it, and the first time we tested it end to end with a real respondent, the system correctly flagged a partial match. The respondent had the same procedure but a meaningfully different complication than the patient asked about, and it said so honestly instead of presenting it as a clean answer. That moment is the actual proof of the thing we set out to build.
We also went through a real architecture correction mid-build. We initially assumed Terac would push completion data to us as a webhook, then learned there were no webhooks available yet, which meant rebuilding the resume mechanism around polling instead of an inbound callback. Catching that early, rather than discovering it the night before judging, mattered.
What we learned
Retrieval is safer than generation when the subject is someone's real medical decision. Early on we considered letting the model infer or extrapolate an answer when no real respondent was available, and we deliberately ruled that out. An AI inventing a plausible-sounding account of a stranger's medical experience is a worse outcome than telling a patient honestly that no one has answered yet.
What's next
A real outcome-distribution view rather than individual anecdotes alone, since showing only verified stories risks skewing toward people motivated to share strong experiences. We'd also want broader procedure coverage and faster respondent recruitment paths so the wait between a question and a real answer keeps shrinking.
Built With
- 21st.dev
- agentspan
- arize
- arize-phoenix
- claude
- fastapi
- ngrok
- opentelemetry
- orkes
- palebluedot
- palebluedot-tokenrouter
- phoenix
- python
- radix-ui
- react
- shadcn/ui
- tailwind-css
- terac
- tokenrouter
- typescript


Log in or sign up for Devpost to join the conversation.