-
-
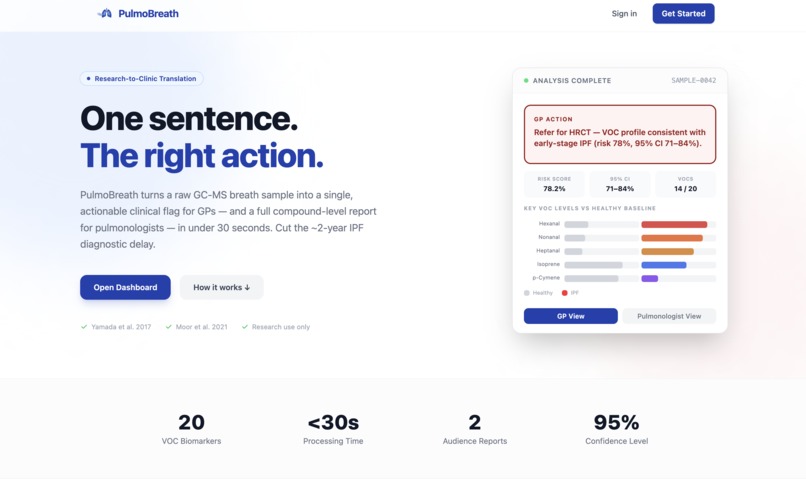
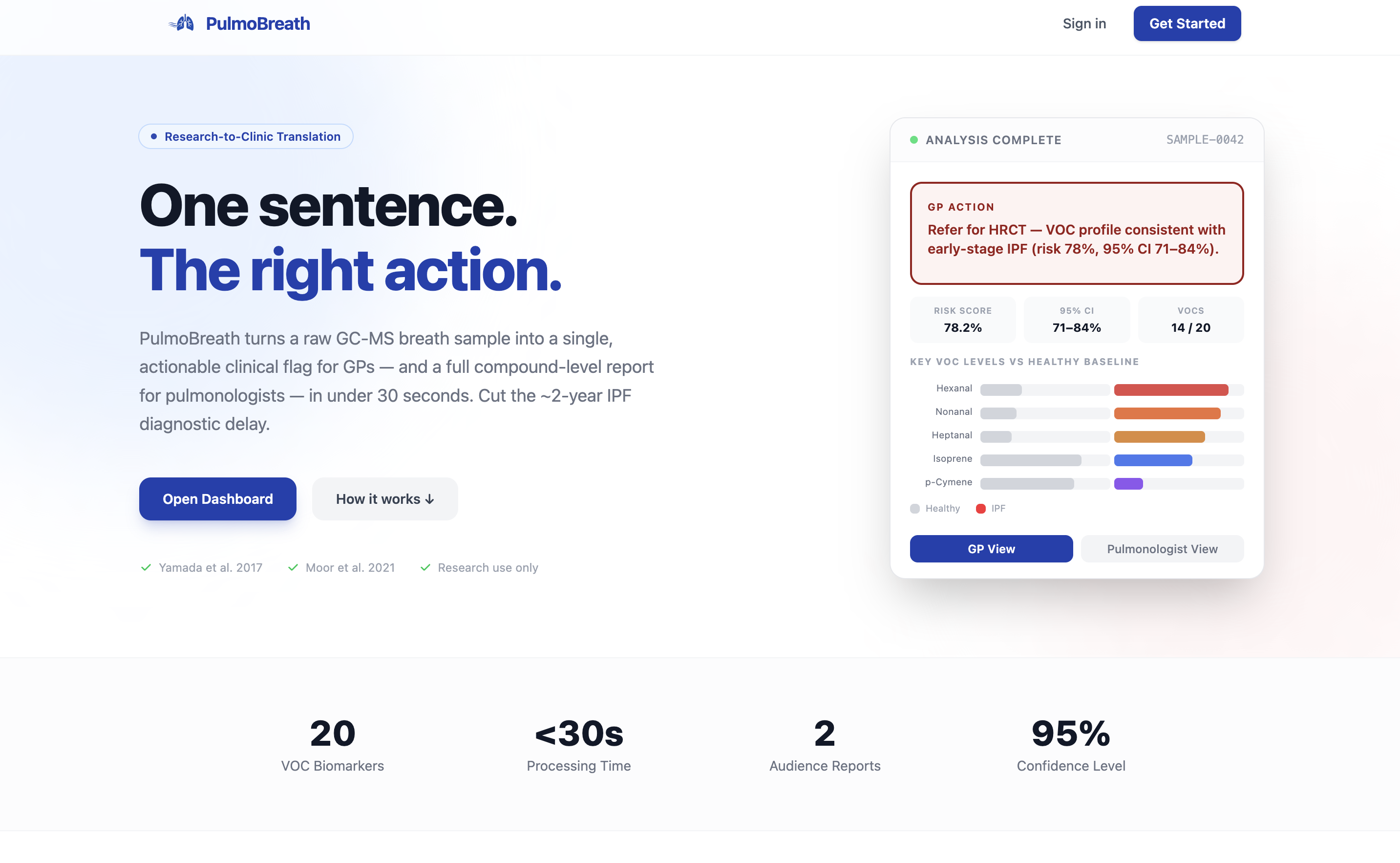
Landing page
-
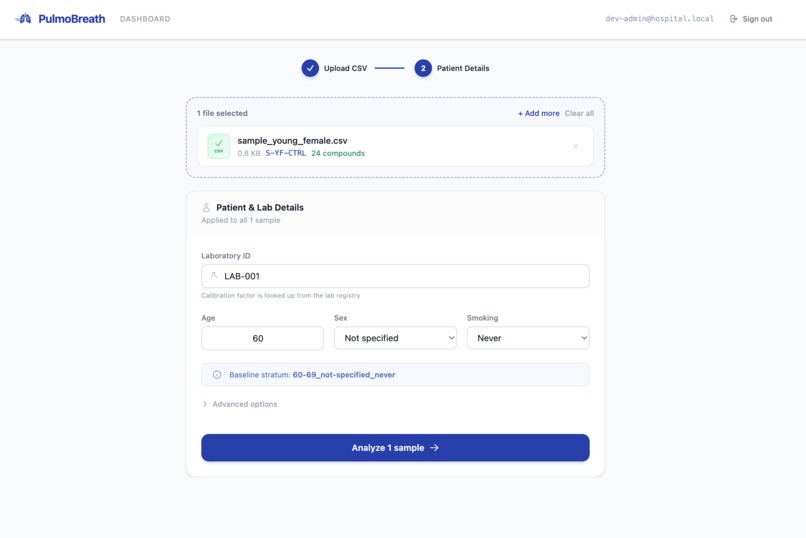
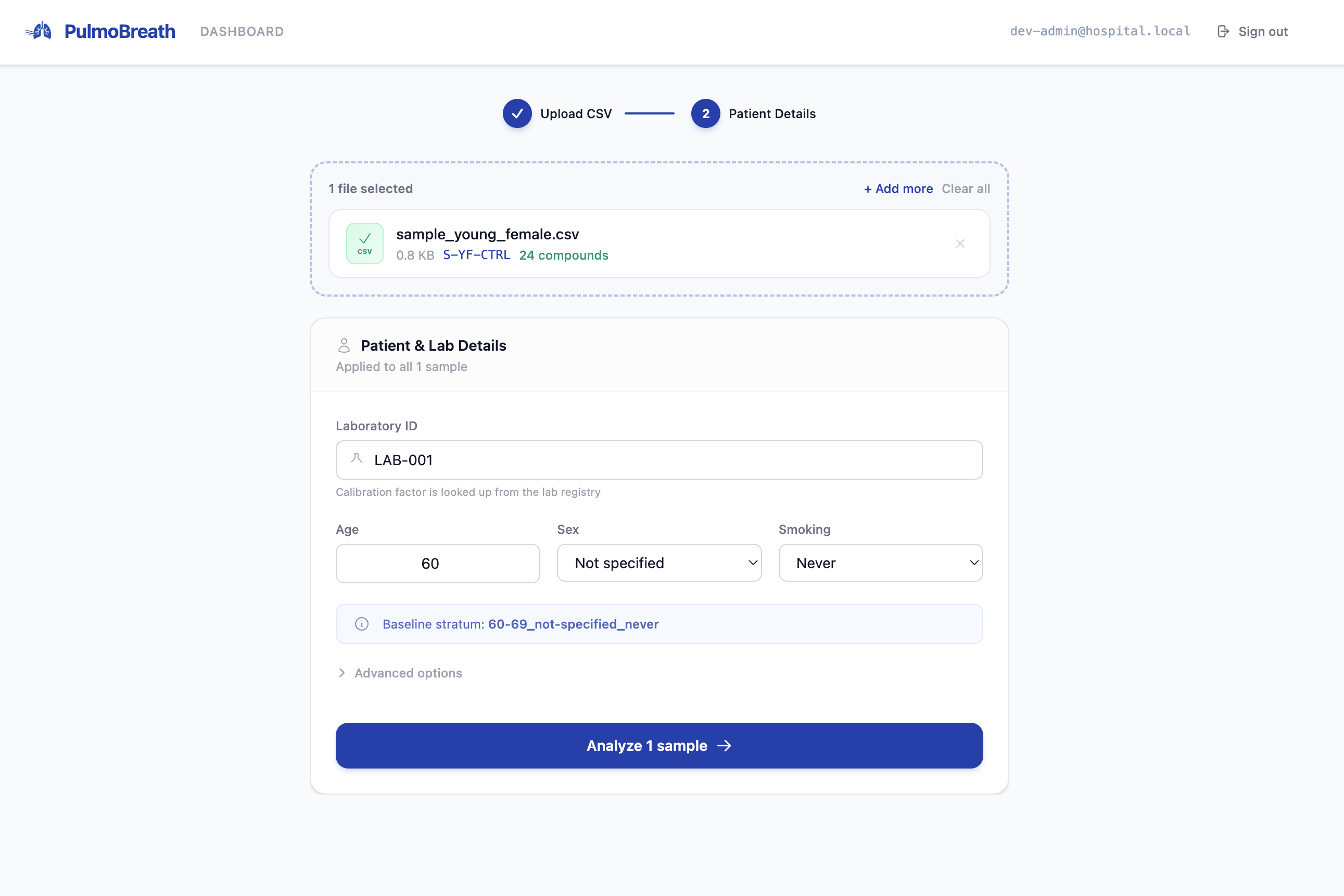
Upload CSV
-
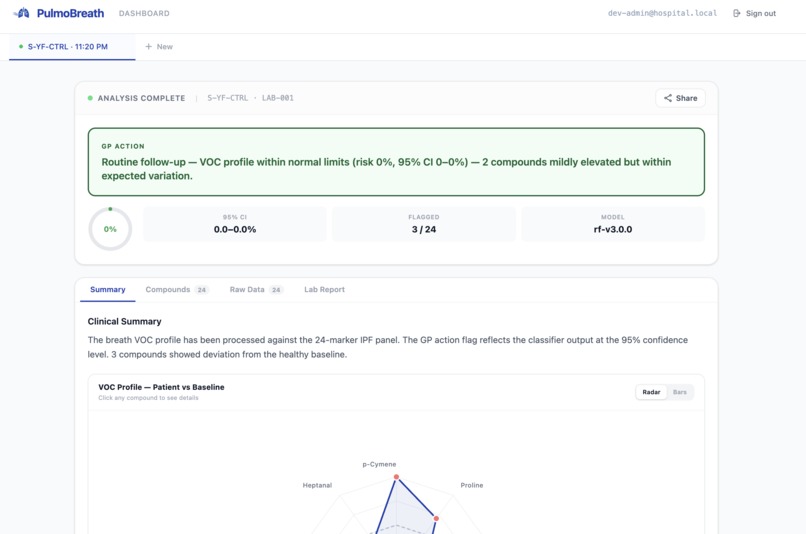
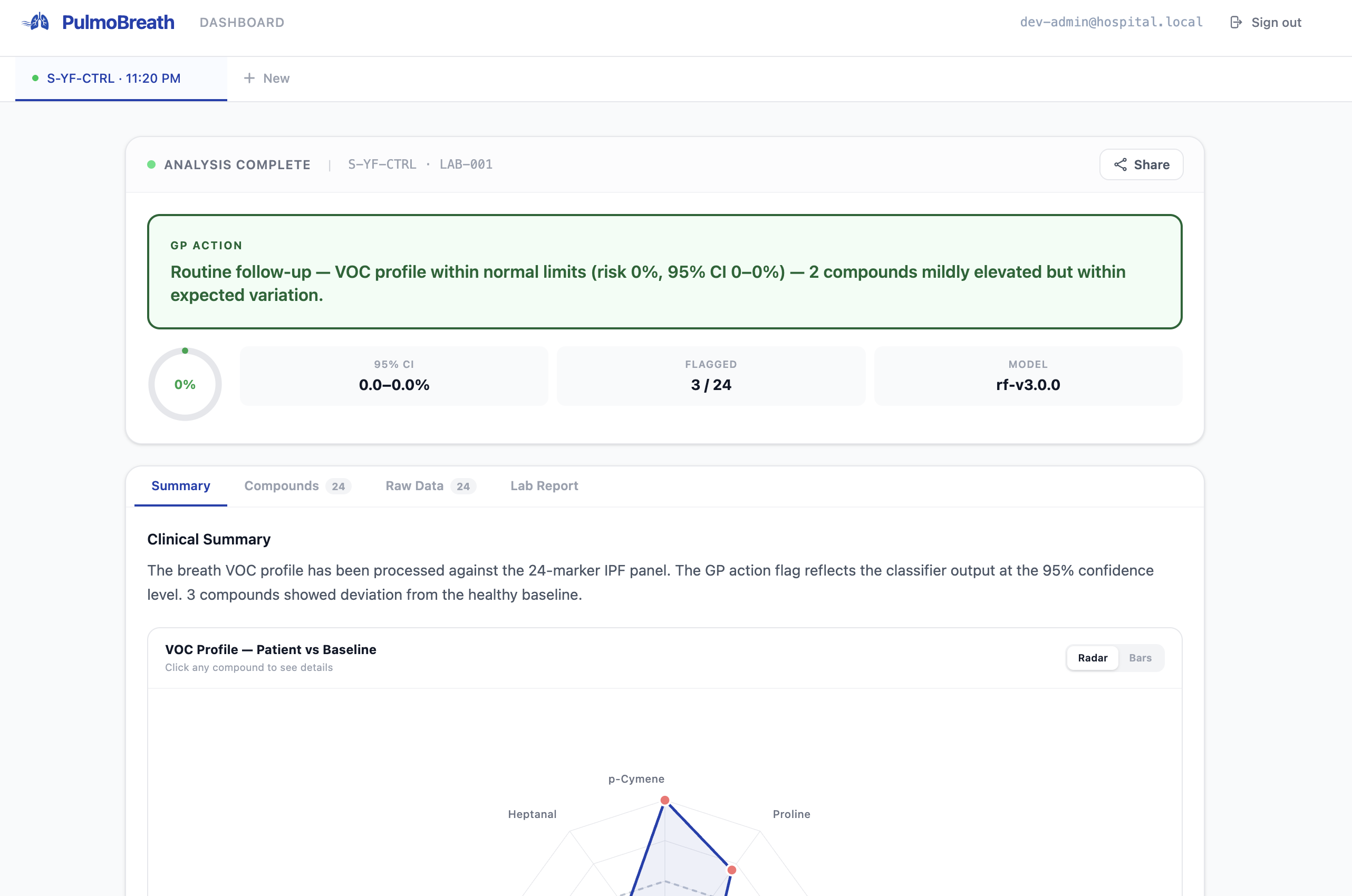
Healthy Patient
-
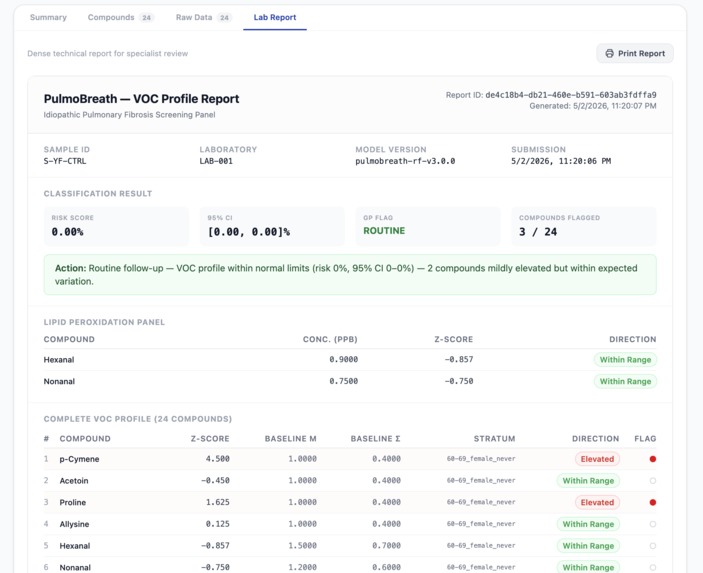
Lab report overview
-
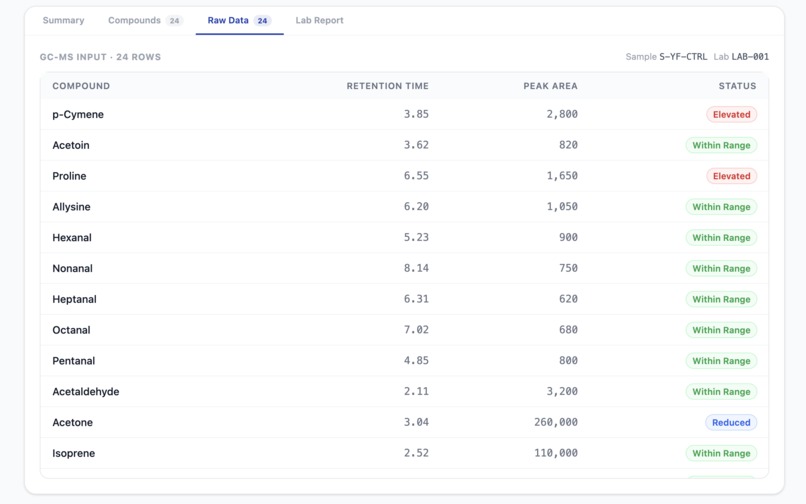
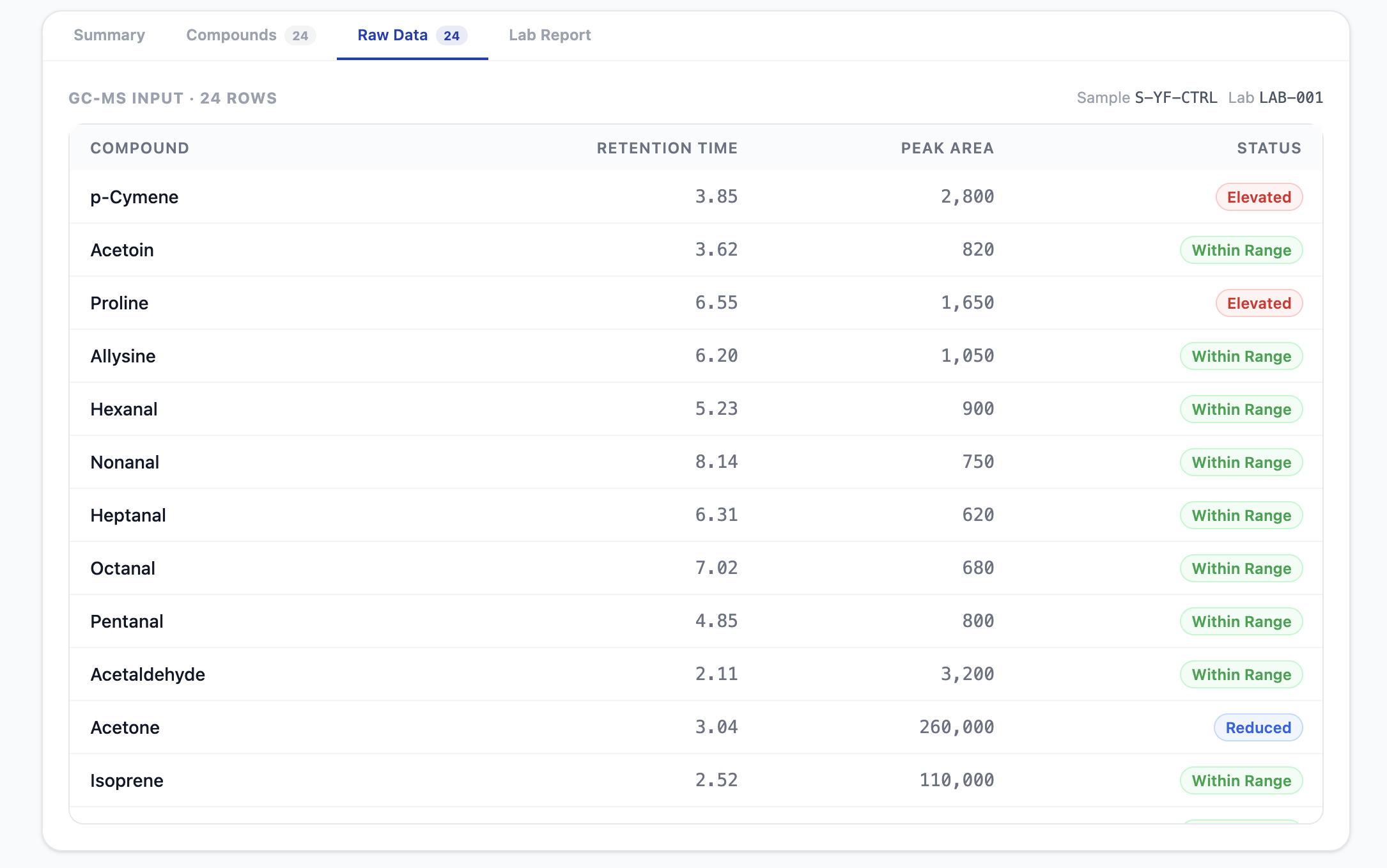
Raw data from breath report
-
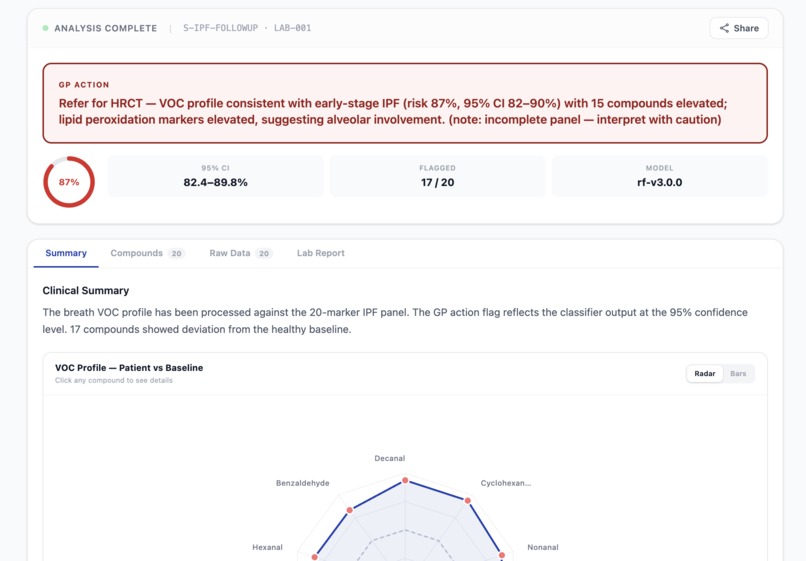
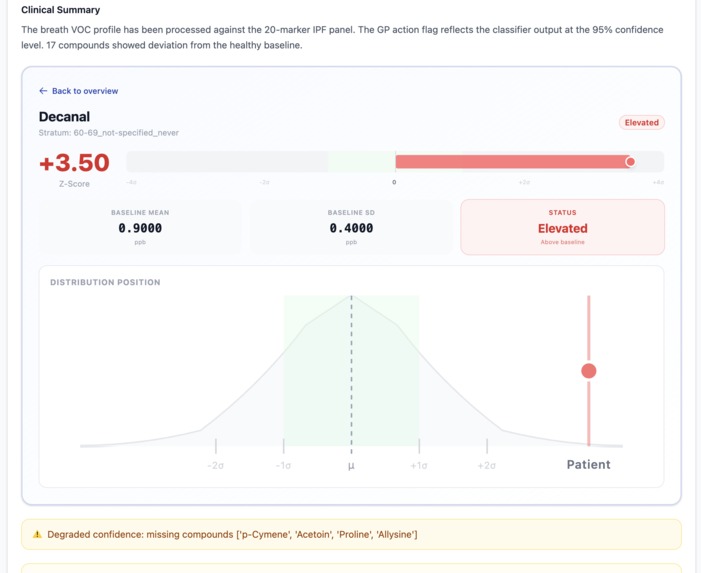
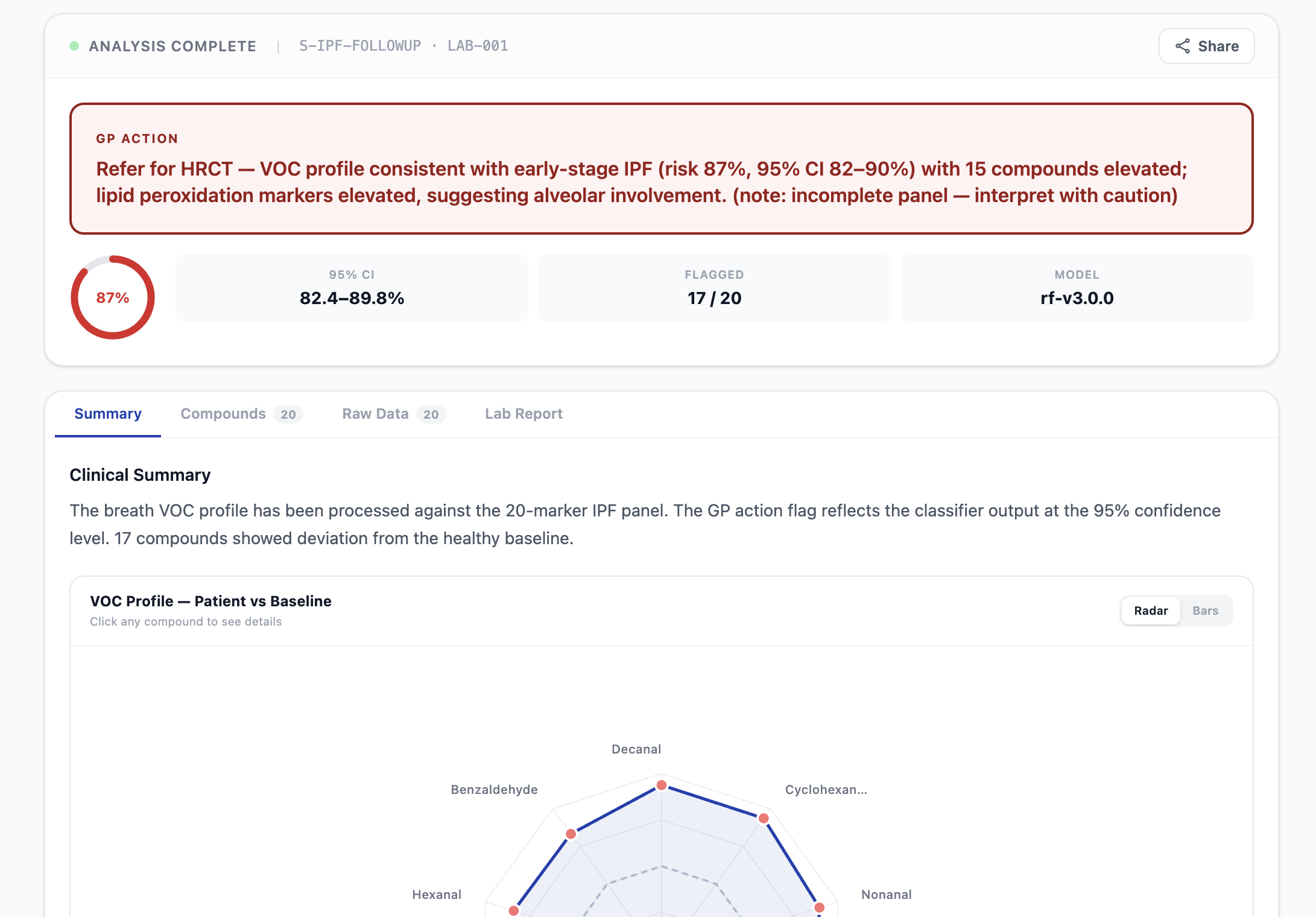
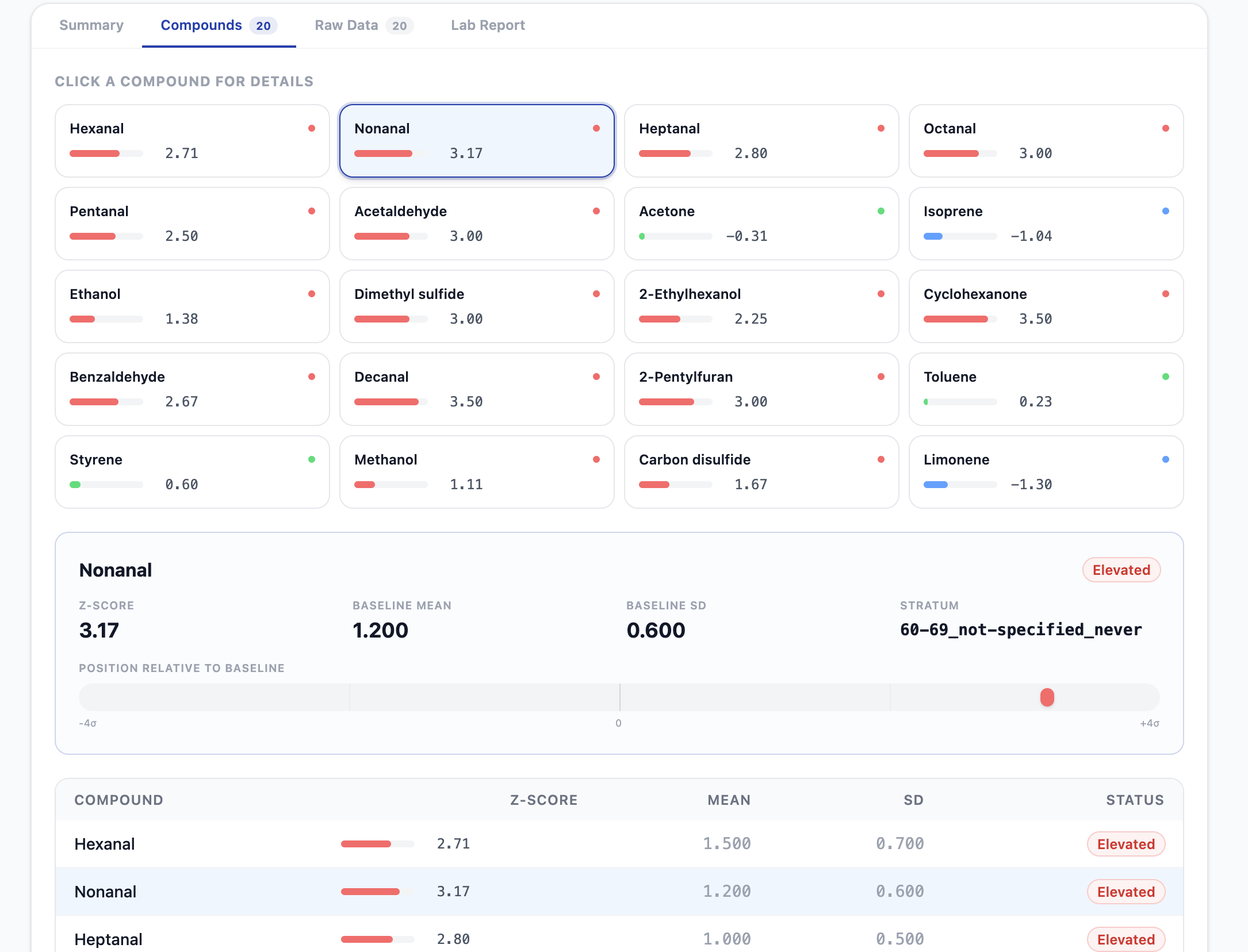
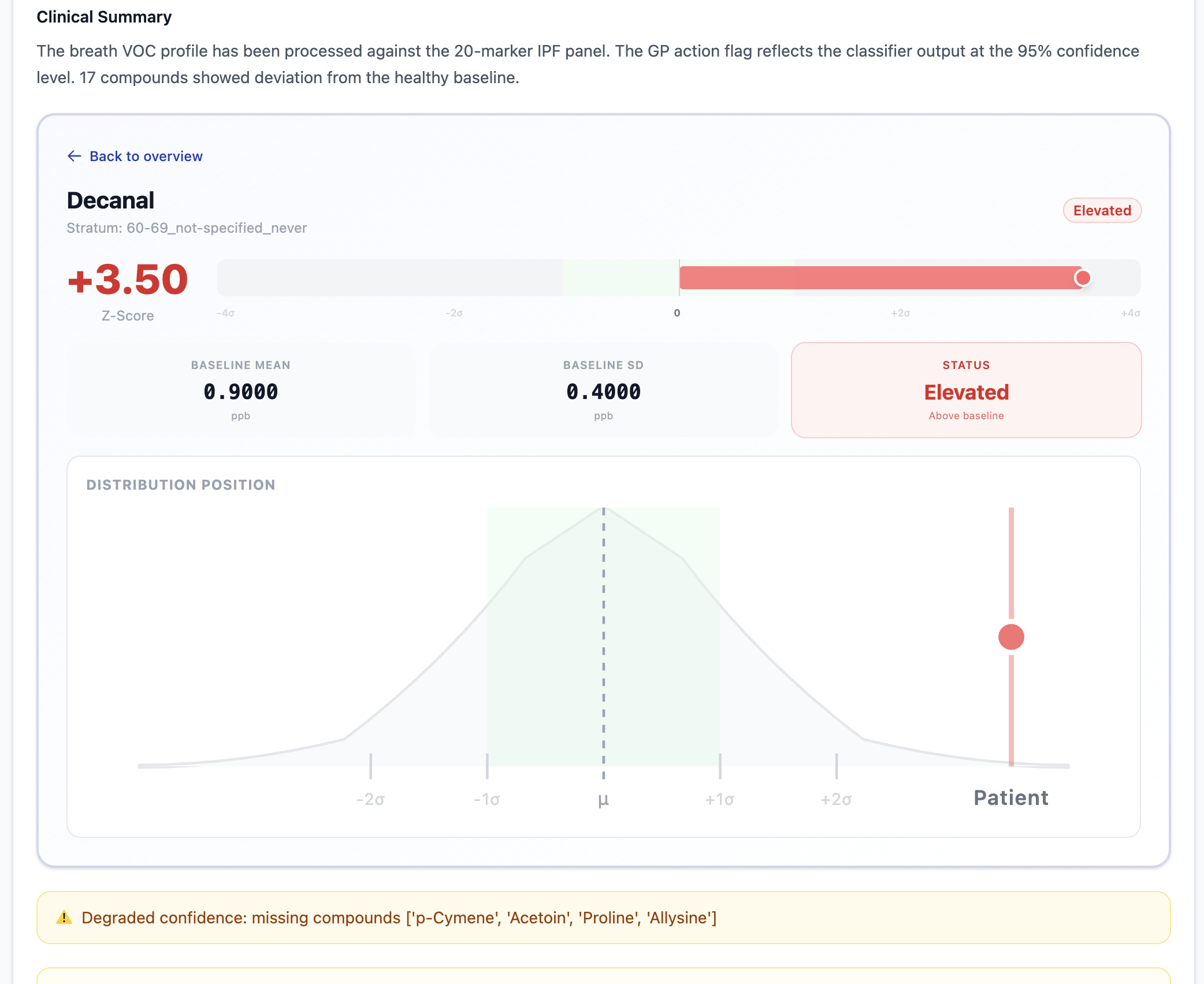
Unhealthy patient report
-
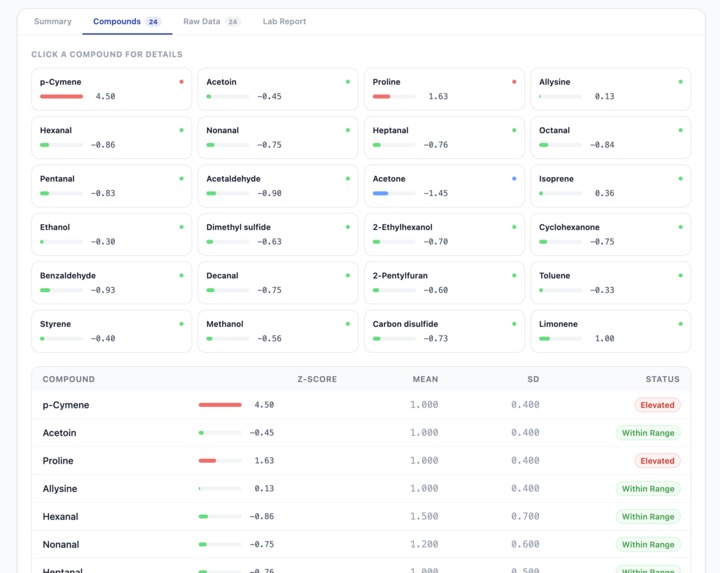
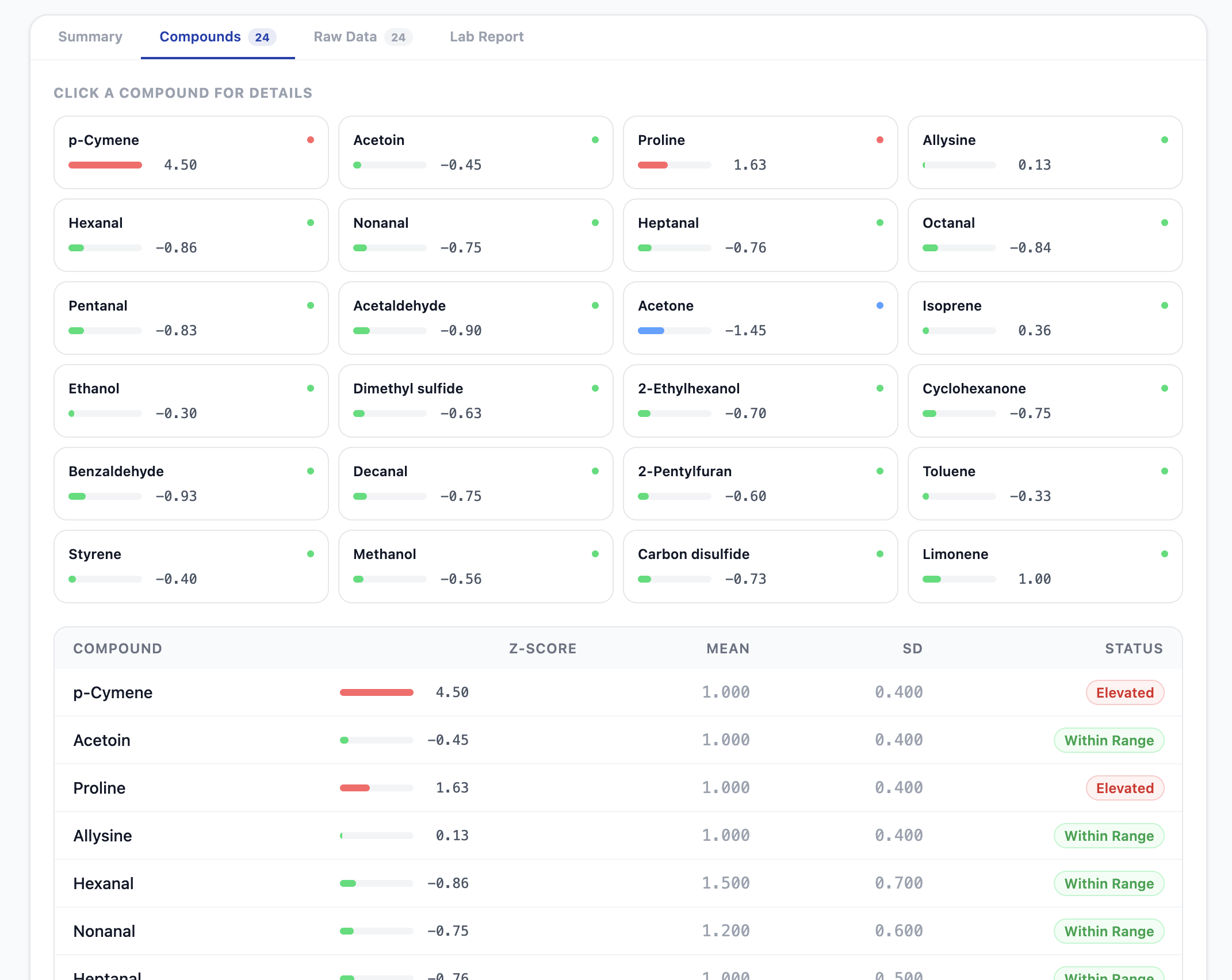
Unhealthy patient compounds report
-
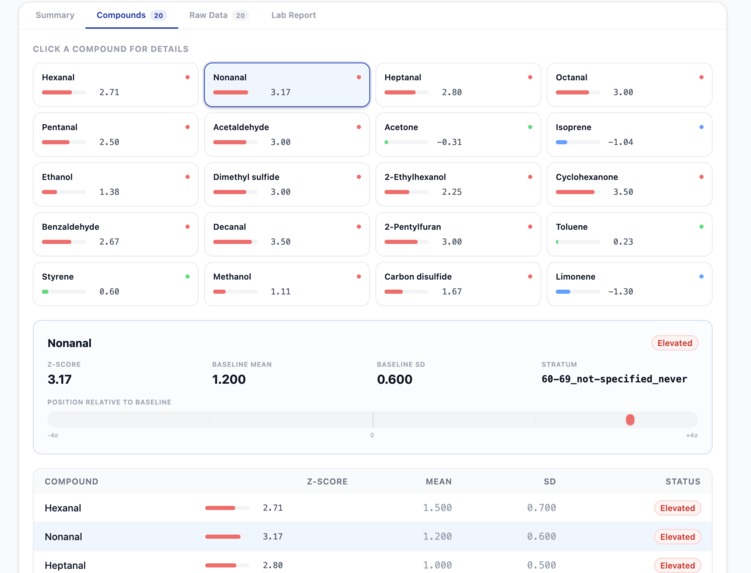
-
-

Healthy patient, patient facing report

Inspiration
PulmoBreath — One Sentence. The Right Action.
A research-to-clinic translation platform that compresses the ~2-year IPF diagnostic delay into a 30-second pipeline.
Built for the Kiro Hackathon · May 2026
💡 Inspiration
Idiopathic Pulmonary Fibrosis (IPF) is a progressive, irreversible lung disease that kills more people than many cancers — yet the average patient bounces between 3+ specialists over two years before getting a diagnosis. The bottleneck isn't the science. Breath biomarker research (Yamada et al. 2017, Moor et al. 2021) has identified volatile organic compounds (VOCs) that distinguish IPF patients from healthy controls with promising accuracy. The bottleneck is translation: raw GC-MS chromatography output is incomprehensible to the GP who actually sees the patient first.
We asked a simple question: What if a GP could upload a breath sample CSV and get back a single, actionable sentence in 30 seconds?
That question became PulmoBreath.
🔬 What It Does
PulmoBreath takes a raw GC-MS breath sample file and runs it through a fully automated pipeline:
CSV Upload → Validation → Normalisation → VOC Atlas Lookup → AI Classification → Clinical Report
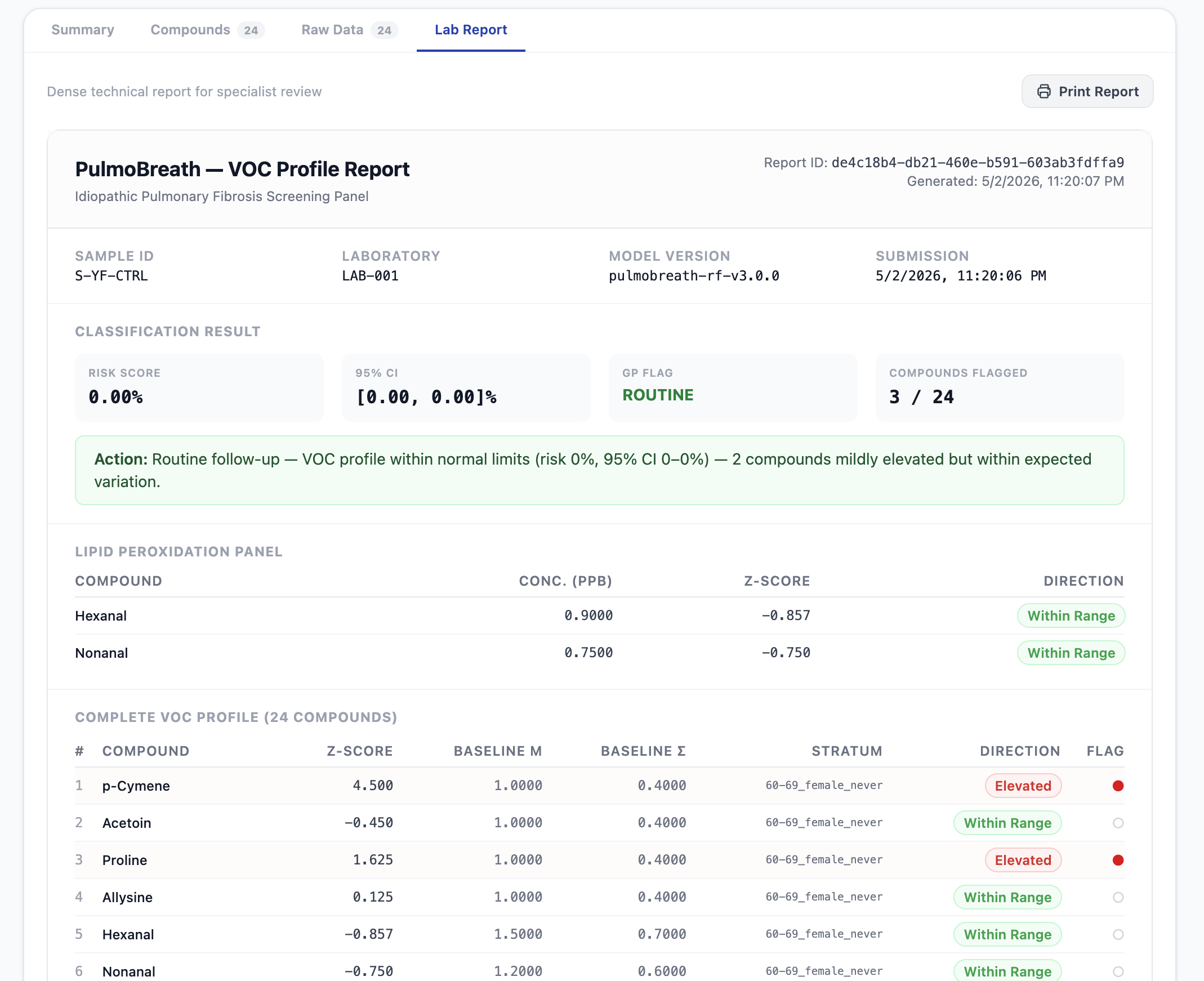
The output is a dual-audience clinical report:
- For GPs: A single plain-language sentence — e.g., "Refer for HRCT — VOC profile consistent with early-stage IPF (risk 78%, 95% CI 71–84%)." One sentence. One action. Done.
- For Pulmonologists: A dense technical breakdown with per-compound z-scores, pathway annotations, lipid peroxidation panel analysis, confidence intervals, and data-gap warnings.
The platform also includes:
- A GP screening checklist for ordering breath tests without specialist knowledge
- SLA tracking with breach detection for sample turnaround times
- A Monte Carlo cohort generator for synthetic training data grounded in published literature
- A VOC Atlas MCP server exposing population baselines as queryable tools
🏗️ How We Built It
Spec-Driven Development with Kiro
This project was built almost entirely through Kiro's spec-driven workflow. We started by writing a detailed requirements document covering 12 formal requirements — from GC-MS ingestion to turnaround SLA tracking — and then iterated with Kiro on a design document that defined every component interface, data model, and error handling path.
The spec produced a 24-task implementation plan with clear dependency ordering. Each task referenced specific requirements for traceability, and property-based tests were placed immediately after the component they validate. Kiro worked through the tasks incrementally, and we reviewed at checkpoints.
The spec files live in .kiro/specs/pulmo-breath/:
requirements.md— 12 requirements with acceptance criteriadesign.md— architecture, component interfaces, 18 correctness propertiestasks.md— 24 implementation tasks with test sub-tasks
The MCP Knowledge Bridge
One of the most interesting architectural decisions was exposing the VOC Atlas as a local MCP server. Instead of having the pipeline query SQLite directly, we wrapped the atlas in four MCP tools (query_baseline, query_profile_zscores, list_compounds, get_atlas_metadata) using fastmcp.
This means:
- The pipeline calls the atlas through MCP tool calls
- The Kiro agent can query population baselines directly during development
- Agent hooks can cross-reference atlas data during automated analysis
- Swapping the local atlas for a live Owlstone VOC Atlas connection in the future requires only updating the MCP server — not the client
The MCP server is configured in .kiro/settings/mcp.json with auto-approved tools, so the agent can query it without friction.
The AI Classifier
The classifier is a Random Forest trained on Monte Carlo synthetic cohort data sampled from published IPF/healthy population statistics. We deliberately avoided real patient data — the cohort generator samples from $\mathcal{N}(\mu, \sigma)$ distributions parameterised by Yamada et al. 2017 and Moor et al. 2021.
Key safety features:
- Anti-dominance guards on the fallback logistic regression path: z-score clipping to $[-4, 4]$ and per-compound contribution caps at $\pm 3.0$ prevent any single biomarker from dominating the risk score
- Bootstrap confidence intervals (200 iterations) using tree subsampling for the RF model and coefficient perturbation for the LR fallback
- Degraded confidence mode when compounds are missing from the panel — the classifier still returns a score but flags it explicitly
The 15-compound feature set has clinically grounded coefficient directions:
| Compound | Direction | Source |
|---|---|---|
| p-Cymene | Negative (↓ in IPF) | Yamada 2017 |
| Acetoin | Positive (↑ in IPF) | Yamada 2017 |
| Proline | Positive (↑ in IPF) | Moor 2021 — collagen breakdown |
| Allysine | Positive (↑ in IPF) | Moor 2021 — collagen cross-linking |
| Hexanal, Nonanal | Positive (↑ in IPF) | Lipid peroxidation markers |
The Frontend
The React + TypeScript + Tailwind frontend features:
- A landing page with animated pipeline visualisation, VOC bar charts, and an interactive compound explorer
- Firebase authentication with protected routes
- A dual-panel translation view showing raw GC-MS data alongside the clinical report
- A risk gauge, z-score bars, radar chart, and deviation chart for the pulmonologist view
- Compound drilldown with pathway annotations and direction badges
The Test Suite
We wrote 18 formal correctness properties validated by Hypothesis property-based tests, plus unit tests, integration tests, and performance tests across 19 test files:
| Property | What It Validates |
|---|---|
| VOC Profile JSON Round-Trip | Serialise → deserialise preserves all values |
| Classifier Determinism | Same input → same output, always |
| Cohort Statistical Convergence | Sample means within $3 \cdot \text{SE}$ of population means |
| GP Flag Threshold Consistency | $\geq 0.7$ → referral; $< 0.7$ → routine |
| Z-Score Computation Correctness | $z = \frac{x - \mu}{\sigma}$ to floating-point precision |
| Lipid Peroxidation Annotation | Annotation iff both Hexanal and Nonanal $z > 1.5$ |
| MCP Atlas Round-Trip | Query baseline → compute z-score at mean → $z = 0.0$ |
| Turnaround Non-Negativity | Delivery after collection → duration $\geq 0$ |
🧗 Challenges We Faced
1. Grounding the Classifier Without Real Data
The biggest challenge was building a clinically meaningful classifier without access to real patient data. We solved this with the Monte Carlo cohort generator — but getting the coefficient directions right required careful reading of the literature. Yamada et al. 2017 reports that p-Cymene decreases in IPF (a monoterpene metabolism marker), which is counterintuitive. Getting this wrong would have flipped the classifier's signal for that compound entirely.
2. Anti-Dominance in the Fallback Path
Early testing revealed that extreme z-scores on a single compound (e.g., a contaminated Hexanal reading) could push the logistic regression fallback to output near-1.0 risk scores regardless of the rest of the profile. We implemented a two-layer guard: z-score clipping to $[-4, 4]$ followed by a per-compound contribution cap of $\pm 3.0$ on the logit. This required back-calculating the capped z-score from the contribution limit — a small but fiddly piece of math.
3. Demographic Stratum Fallback
Not every patient fits neatly into the atlas strata. A 35-year-old female never-smoker has no exact match in a database built from 40+ age bands. We implemented a Hamming-distance fallback that finds the nearest stratum across three dimensions (age band, sex, smoking status) and annotates the report with a data-gap warning. Getting the fallback to be deterministic and auditable took several iterations.
4. Dual-Audience Report Design
Writing a GP flag that is simultaneously actionable, accurate, and one sentence is harder than it sounds. The text varies based on risk tier, number of elevated compounds, lipid peroxidation status, and confidence level — so no two reports with different profiles produce identical boilerplate. We ended up with a contextual sentence builder that assembles the flag from components rather than selecting from templates.
5. Spec Scale
The Kiro spec grew to 12 requirements, 18 correctness properties, and 24 implementation tasks. Keeping the design document, the requirements, and the task list consistent as the project evolved was a real exercise in discipline. Kiro's spec workflow made this manageable — but the sheer volume of acceptance criteria meant we had to be very deliberate about checkpoint reviews.
📚 What We Learned
Spec-driven development works. Writing requirements and design before code felt slow at first, but it eliminated entire categories of "wait, what should this actually do?" questions during implementation. The 18 correctness properties caught real bugs that unit tests alone would have missed.
MCP is a powerful abstraction layer. Wrapping the VOC Atlas as an MCP server decoupled the pipeline from the storage layer and made the atlas queryable by both code and the AI agent. This pattern generalises well — any domain knowledge base could be exposed the same way.
Property-based testing is worth the investment. Hypothesis found edge cases we never would have written by hand — like z-score computation breaking down when the baseline standard deviation is extremely small, or the cohort generator producing statistically implausible samples at very low N.
Clinical software demands humility. Every screen says "Research use only." Every report carries confidence intervals and data-gap warnings. The hardest part of building a medical tool isn't the code — it's resisting the temptation to overstate what the code can do.
🛠️ Built With
| Layer | Technology |
|---|---|
| Backend | Python 3.11+, FastAPI, Pydantic, scikit-learn, NumPy, Pandas |
| Frontend | React, TypeScript, Tailwind CSS, Vite |
| Auth | Firebase Authentication |
| Database | SQLite (VOC Atlas, turnaround tracking) |
| MCP | fastmcp (VOC Atlas server) |
| WeasyPrint, Jinja2 | |
| Testing | pytest, Hypothesis (property-based testing) |
| Development | Kiro — spec-driven development, agent hooks, steering, MCP integration |
📎 Links
- Key Literature:
Disclaimer: PulmoBreath is a research prototype. It is not a diagnostic device. All clinical decisions must be made by qualified healthcare professionals. The classifier is trained on synthetic data and has not been validated in a clinical trial.

Log in or sign up for Devpost to join the conversation.