-
our frontpage!
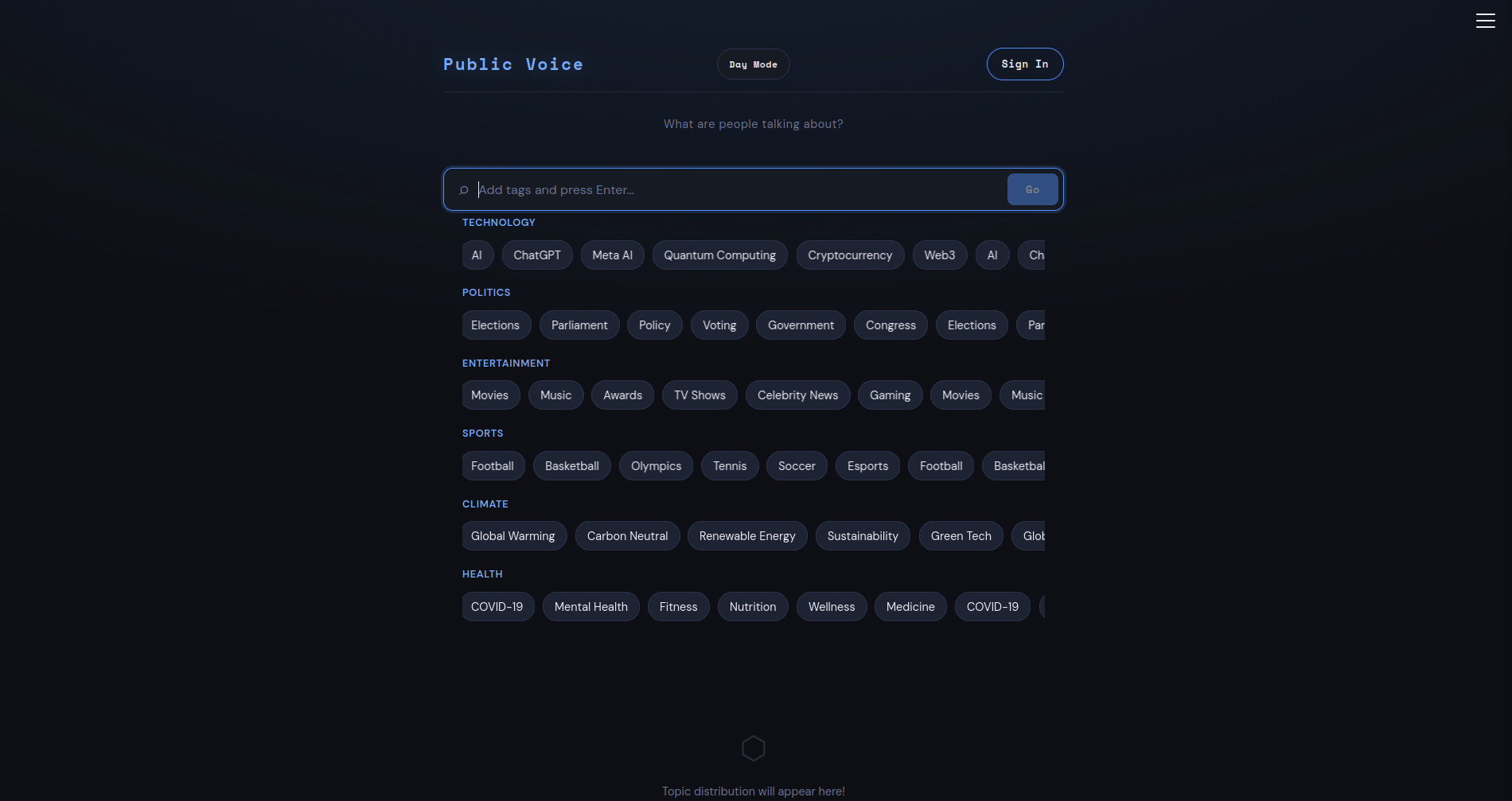
Public Voice AI-Powered Media Sentiment & Topic Intelligence
Inspiration
The modern digital landscape generates an overwhelming volume of media content every day. Media managers, communications professionals, and researchers often struggle to cut through the noise and understand what is actually being said about the topics that matter to them. We wanted to build a tool that could do this at scale — one that goes beyond keyword searches and actually understands the sentiment and thematic structure of the content it analyses. Public Voice was born from the belief that understanding public discourse should be accessible, fast, and genuinely insightful.
What it does
Public Voice analyses digital media content and surfaces the topics, themes, and sentiments that matter most. Users enter a query and the platform returns a breakdown of the key topics driving the conversation, along with a sentiment score for each — visualised as colour-coded bars that shift from red (negative) through amber to green (positive). The tool is designed for media managers, brand strategists, journalists, and anyone trying to understand the digital landscape at a glance. Coverage and sentiment are presented together so users can see not just what people are talking about, but how they feel about it.
How we built it
The project was written primarily in Python. We used BERT-based models at the core — both for topic classification and for clustering related content into meaningful groups. The classification pipeline identifies which broad topics a piece of media content belongs to, while the clustering layer groups similar content together to surface emergent themes. Sentiment scoring is also handled by a fine-tuned transformer model, producing a continuous score between 0 and 1 that captures nuance rather than a simple positive/negative binary. The frontend was built with React and Recharts, with the sentiment score driving both the height and colour of each bar in the visualisation.
Challenges we ran into
The most significant challenge was making foundation models viable in a production context. Large pre-trained BERT models carry substantial weight — both in terms of memory footprint and inference latency — which made real-time responses impractical out of the box. We explored several strategies to address this, ultimately finding that a combination of task-specific fine-tuning and selective pre-training on domain-relevant data gave us the best trade-off between accuracy and speed. Getting the classification and clustering pipelines to agree on topic boundaries was also a non-trivial problem, requiring careful iteration on how we represented and compared embeddings.
Accomplishments that we're proud of
We are proud of getting foundation models to perform reliably at the speed required for an interactive tool. The combination of fine-tuning and pre-training that we landed on significantly reduced request times without meaningfully sacrificing the quality of topic and sentiment outputs. We are also proud of the visualisation layer — the sentiment-to-colour mapping gives an immediately readable picture of the emotional landscape across topics, which we think is a genuinely useful interface for the kind of users we had in mind.
What we learned
We learned that deploying transformer-based models in a latency-sensitive context requires a very different mindset to training them. Fine-tuning and pre-training are not just about improving accuracy — they are powerful tools for making models smaller, faster, and more focused on the task at hand. We also learned a great deal about the relationship between topic modelling and sentiment analysis: the two are deeply intertwined, and treating them as separate problems produces worse results than building pipelines that reason about them together.
What's next for Public Voice
We want to extend Public Voice with real-time data ingestion so that the platform can track how sentiment around a topic shifts over time — not just what people are saying now, but how the conversation is evolving. We are also exploring multilingual support, since the digital landscape is far from English-only and media managers increasingly need to monitor sentiment across languages and regions. Longer term, we see potential in offering alerting and reporting features so that users can be notified when sentiment around a key topic shifts significantly.

Log in or sign up for Devpost to join the conversation.