-
-
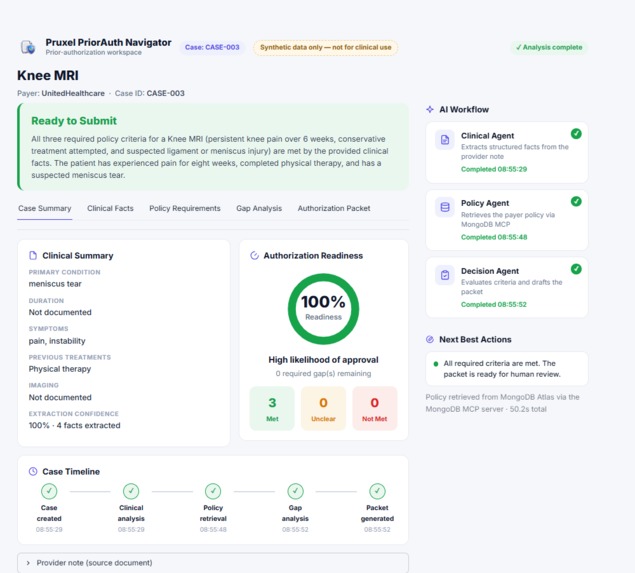
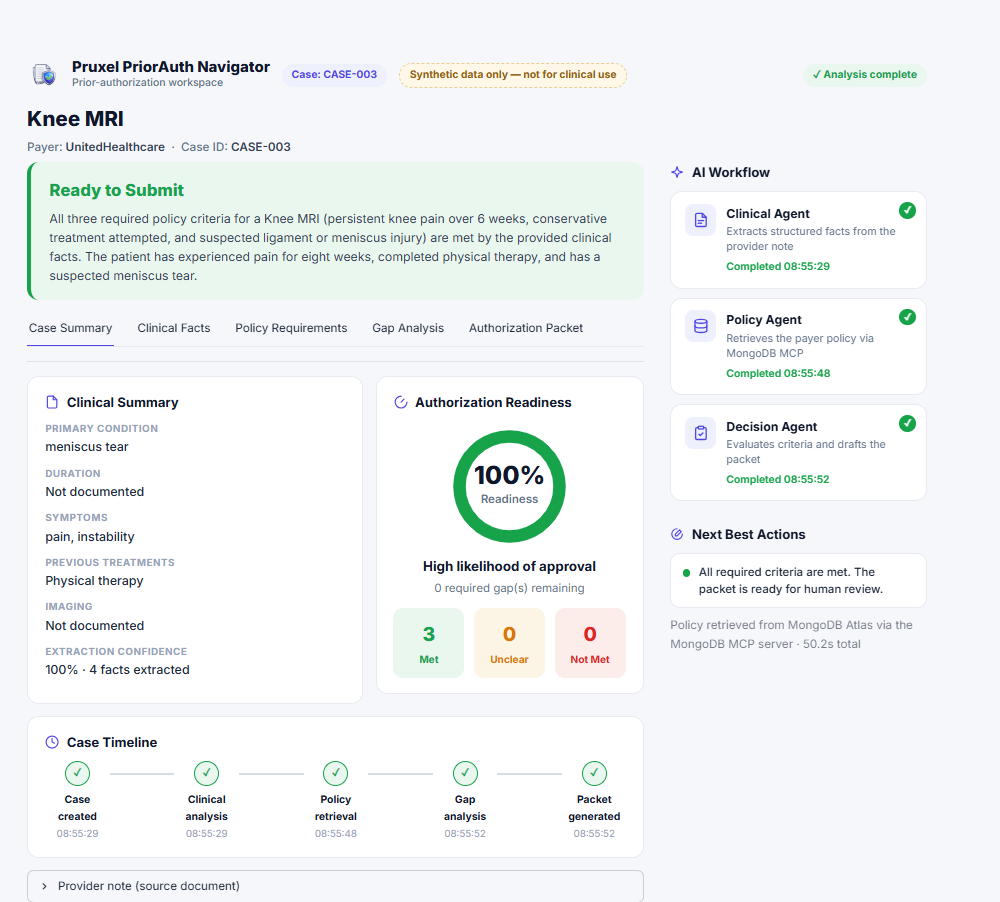
Complete case: all 3 criteria met, 100% readiness, drafted packet ready for human review.
-
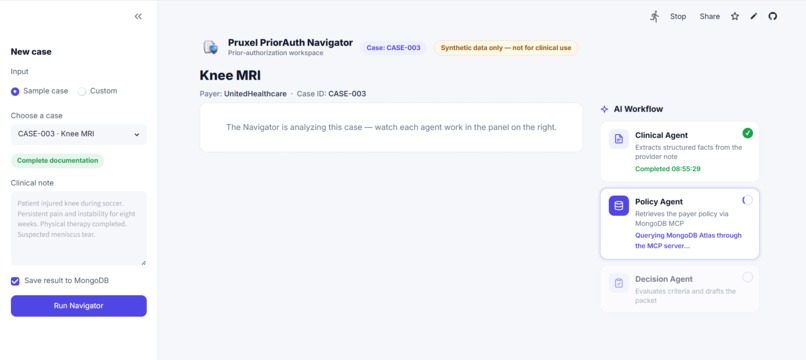
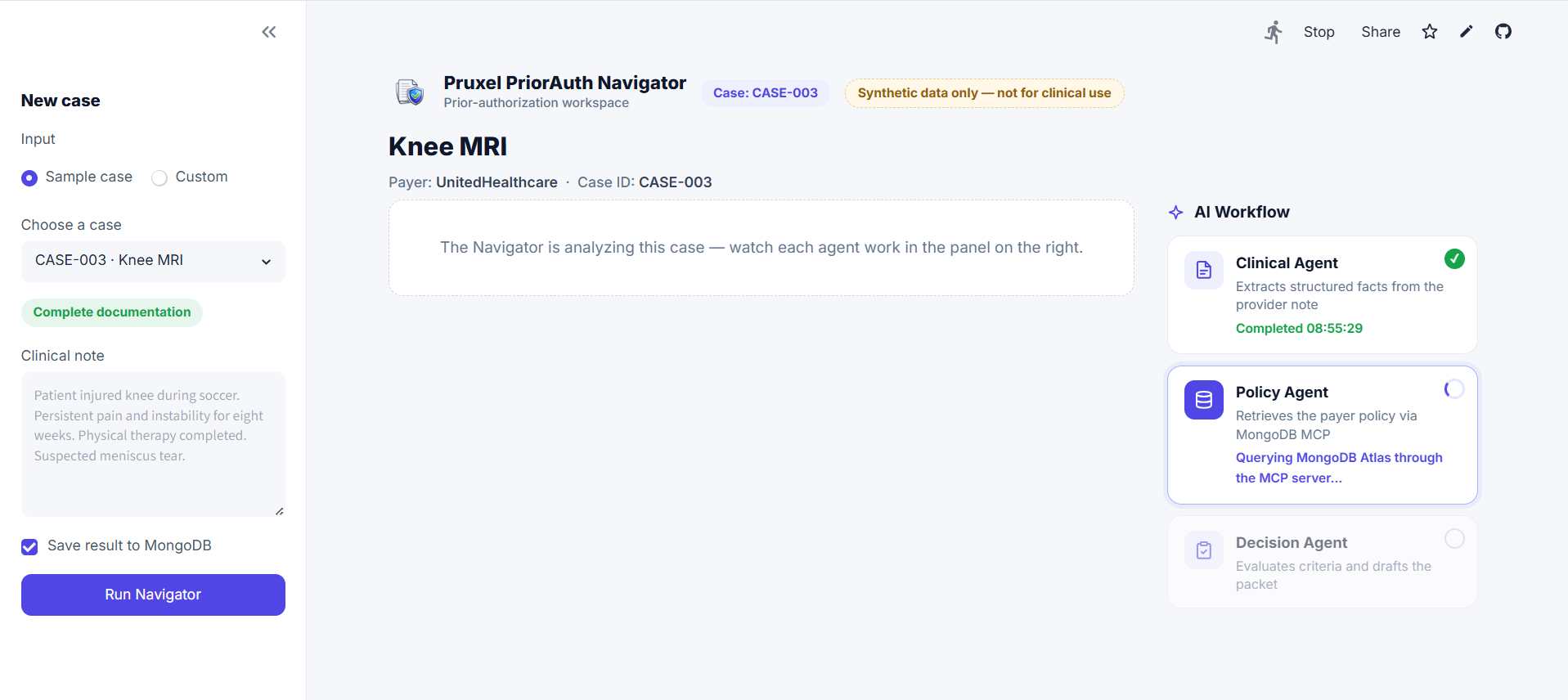
Agents work live: the Policy Agent is querying MongoDB Atlas through the MongoDB MCP server.
-
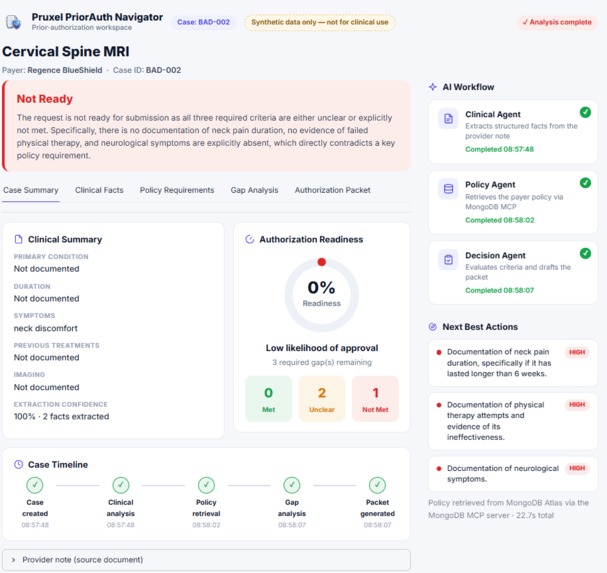
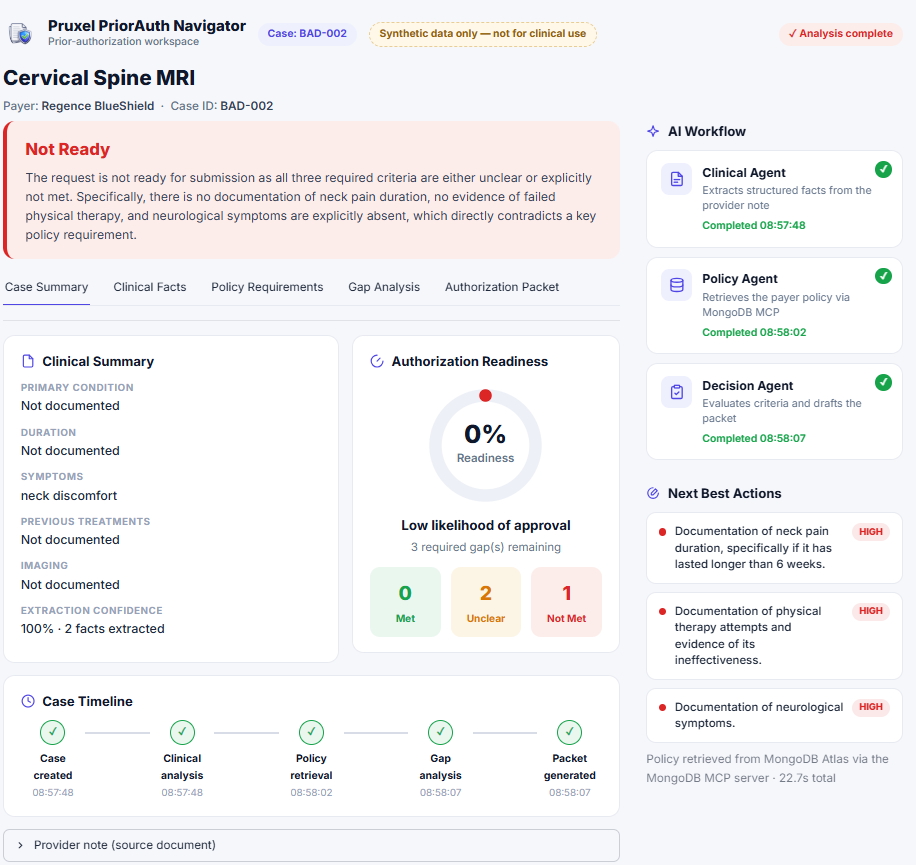
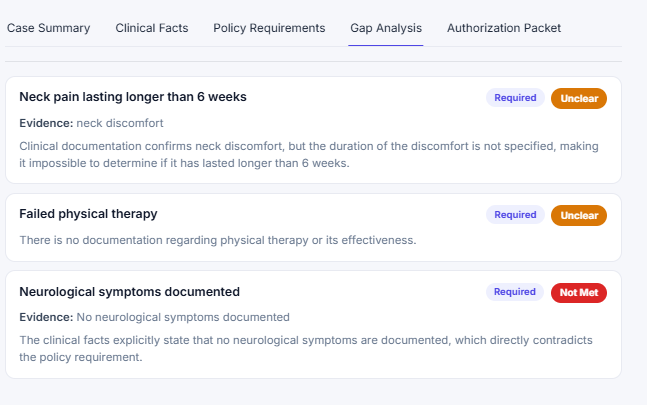
Incomplete case: 0% readiness, fails safe to Not Ready, with the exact missing documentation.
-
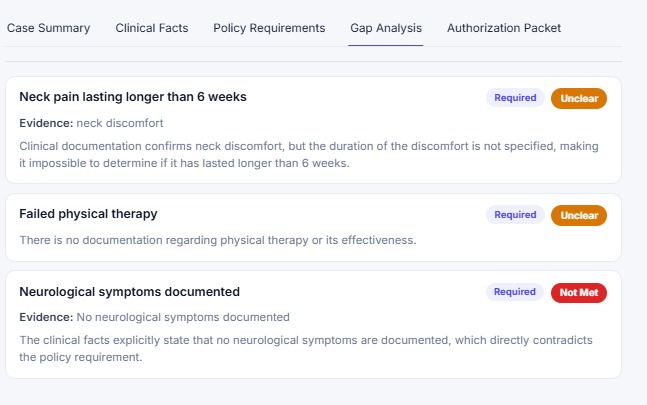
Every policy criterion gets a verdict with evidence quoted from the provider note.
-
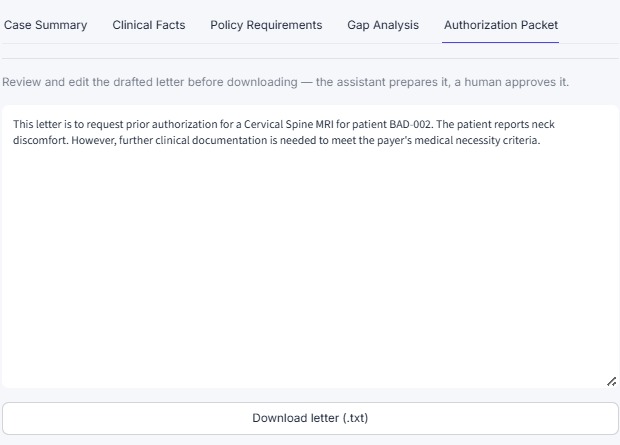
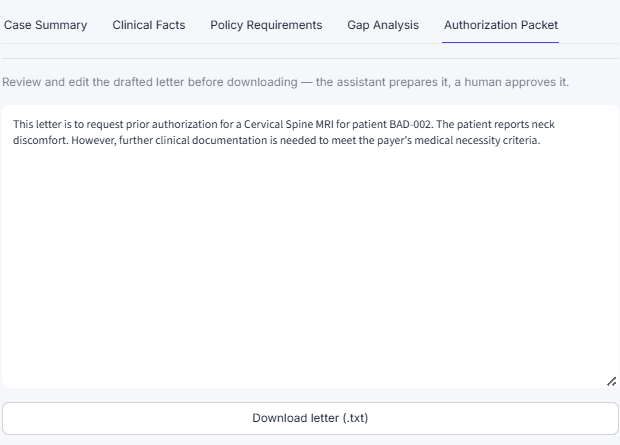
AI drafts the authorization letter; a human reviews, edits, and approves before download.
Inspiration
Prior authorization is one of the heaviest administrative burdens in US healthcare. Staff spend hours matching a patient's chart against a payer's coverage rules and writing justification letters, and small omissions cause denials that delay care. I wanted to find out whether a team of cooperating AI agents could handle the tedious preparation — so a human reviewer only has to approve, not assemble from scratch.
What it does
Given a clinical note, the requested procedure, and the payer, the system runs three specialized agents:
- Clinical Agent reads the free-text note and extracts structured facts — diagnoses, prior treatments and their durations, exam findings — each tied back to where it appeared in the note.
- Policy Agent retrieves the relevant payer policy from MongoDB Atlas through the MongoDB MCP server, and turns it into a checklist of criteria.
- Decision Agent compares the facts against each criterion, produces a gap analysis, drafts an authorization letter, and returns a recommendation: Ready to Submit, Submit with Caveats, or Not Ready.
A deterministic safety gate (outside the model) guarantees the system never reports "Ready" while a required criterion is unmet or unclear — it fails safe. The app uses synthetic data only and is decision-support with a human in the loop, not for clinical use.
How I built it
- Google Agent Development Kit (ADK) with a
SequentialAgentorchestrating the three sub-agents over shared session state. - Gemini 2.5 Flash as the reasoning model.
- MongoDB Atlas as the policy and case store, queried by the Policy Agent through the MongoDB MCP server — database access is a real MCP tool call, not a hard-coded query.
- Pydantic output schemas to force structured, validated output from the extraction and decision steps.
- A Streamlit front end that runs the pipeline and lights up each agent live, then renders the decision, gap analysis, and drafted letter.
Challenges I ran into
- ADK doesn't allow an agent to use both tools and a strict output schema, so I split the roles: the Policy Agent uses MCP tools, while the Clinical and Decision agents use schemas, and I validate the Policy Agent's JSON downstream.
- Shutting down the MCP server (a Node process) and asyncio cleanly on Windows was painful. I ended up running the pipeline in a dedicated subprocess and streaming progress back to the UI — which also made the live agent animation reliable.
- Making the "Ready" verdict trustworthy: I moved the final decision gate out of the model into deterministic Python, so a required gap can never be hand-waved.
What I learned
- Practical multi-agent orchestration, and where to keep determinism versus LLM judgment.
- How to wire a real MCP server into an agent so data access is a first-class tool.
- That the hard part of an agent demo is reliability and honest failure modes, not the happy path.
What's next
- Atlas Vector Search for semantic policy retrieval across many payers.
- PDF export of the authorization packet, and "what would flip this to Ready" suggestions.
Built With
- gemini
- google-agent-development-kit
- google-cloud
- model-context-protocol
- mongodb-atlas
- python
- streamlit

Log in or sign up for Devpost to join the conversation.