-
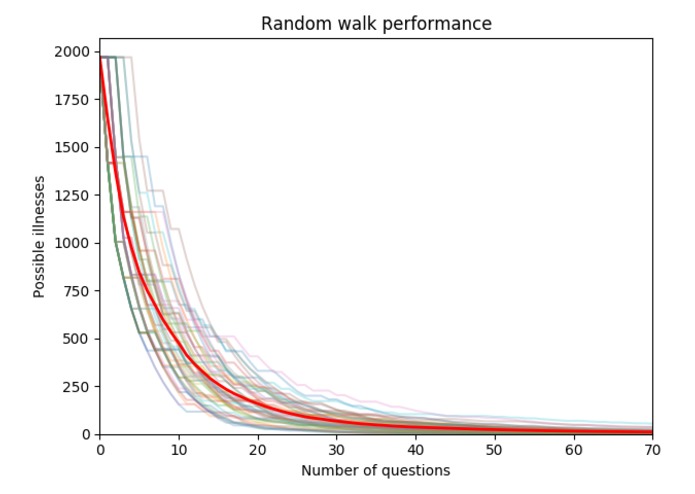
Performance over random walk
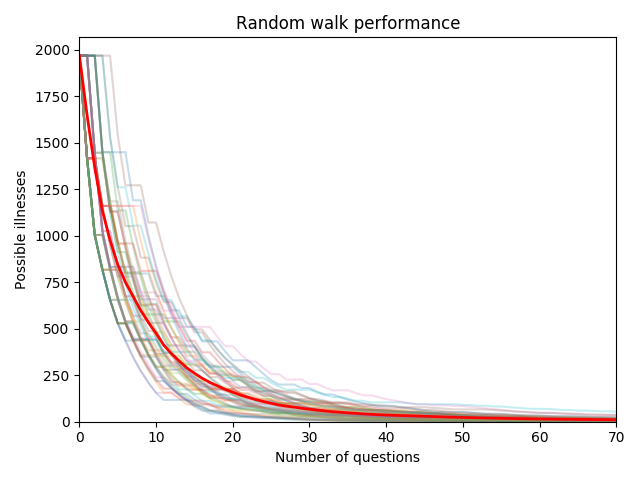
The main objective is to minimize the number of questions one must ask for determine what rare disease one can have given a list of those related to the human phenotype ontology (aka. the questions).
With more or less success this was an iterative process, most of the thinks I've tried didn't work as expected so this has been mostly a learning project for graph manipulation.
Iterations
0 - Base case
14832 - Different phenotype
1 - Prune nodes not referenced by the disease dataset
The main problem found in this case is the use of alternative ids in order to reconstruct the graph. With that done the number of nodes has been reduced to 6850.
2 - Cutoff based on answers
Depending on the previous answers we can prone some branches. Given a random walk of 1/3 True answers the mean length over 100 runs was 251
3 - Dropping potential illnesses by selected phenotype
As seen on the plot the performance over 50 random walks is between 20-80.
Repo usage
# Dependencies
pip install -r requirements.txt
# Static pruning
python importance_determination.py
# Dynamic pruning
python main_prunning.py
# Generate possible illness by individual phenotype
python tree.py
# Generate random walks simulations
python main_ill.py
# Plot random walk
python plot_runs.py
Built With
- graph
- pronto
- python

Log in or sign up for Devpost to join the conversation.