-
-

Loading
-
Diagram
-
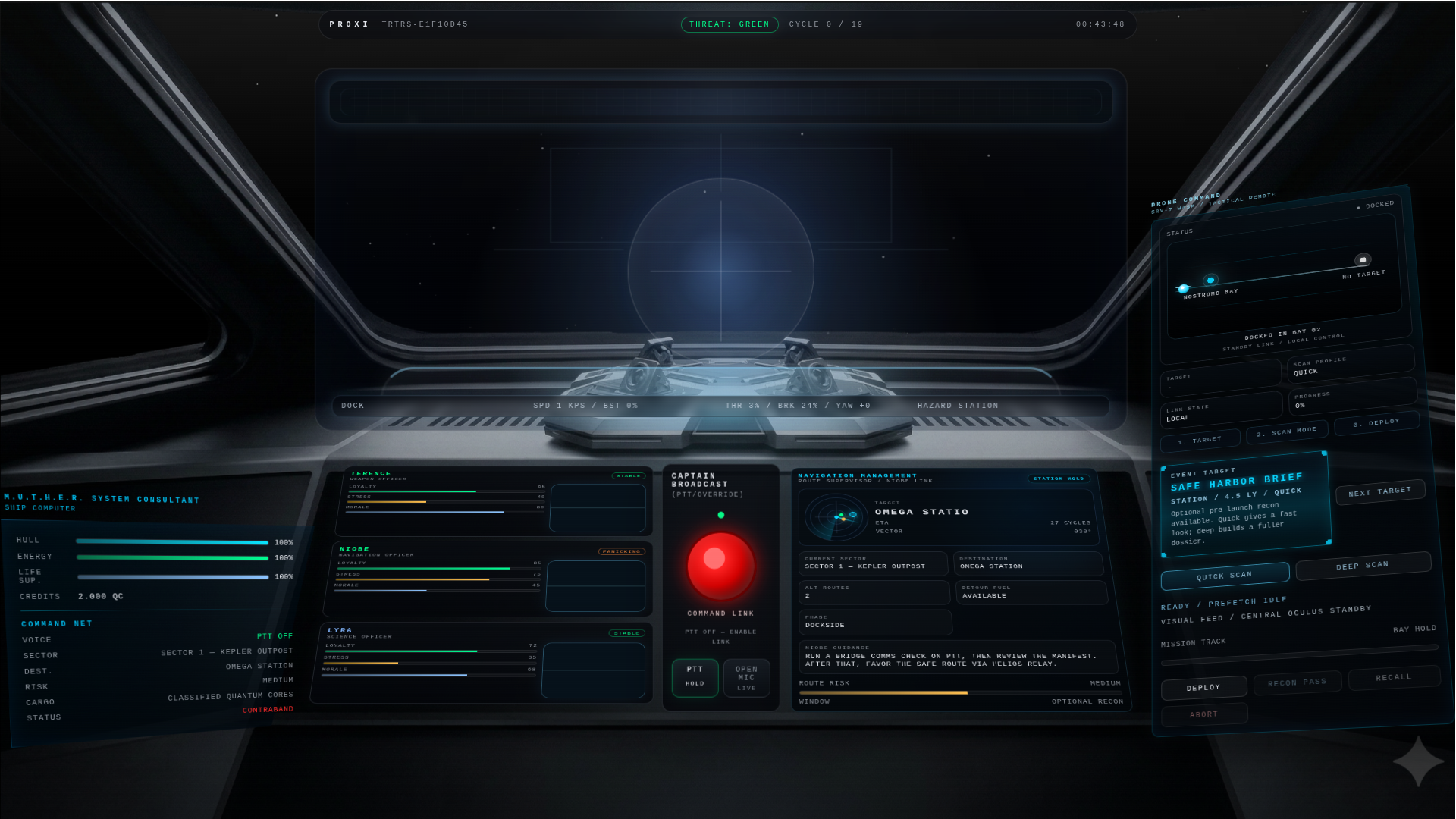
Cockpit
-
Oculus screen

Inspiration
We wanted to build a voice experience that did not feel like a chatbot with a microphone icon.
In most games, roleplay breaks the moment the player has to return to keyboards, menus, and dialogue trees. You may be playing a captain, but you still interact like a user outside the world. PROXI started from a simple question: what if speaking to the ship felt like the most natural way to play?
That led us to build a live sci-fi command experience where the player talks directly to an AI bridge crew and the world answers through voice, visuals, memory, and ship state in real time.
What it does
PROXI is a live multimodal storytelling experience disguised as a command game.
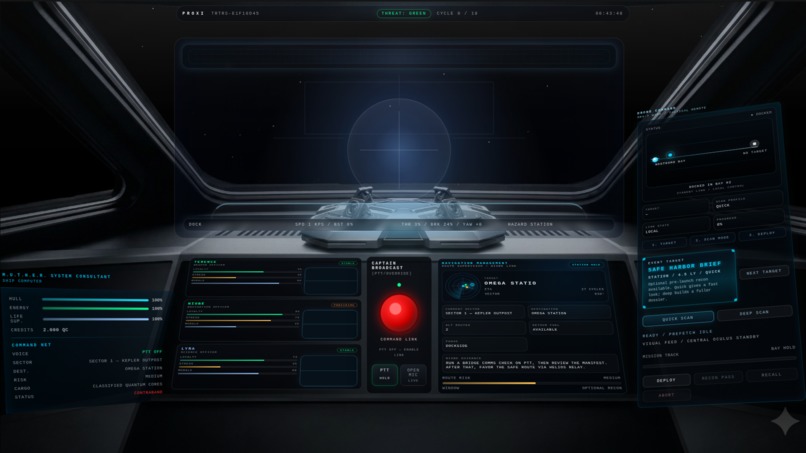
You play as the captain of a smuggling vessel carrying contraband quantum cores to Omega Station. Instead of navigating the game through keyboard-heavy menus, you speak to the bridge. M.U.T.H.E.R. responds as the ship computer, the crew reacts with distinct personalities, and the mission evolves through procedural events, generated media, tactical drone recon, and changing ship state.
The experience combines:
- live voice interaction
- agent-driven crew responses
- Gemini interleaved output
- generated imagery and cinematic video beats
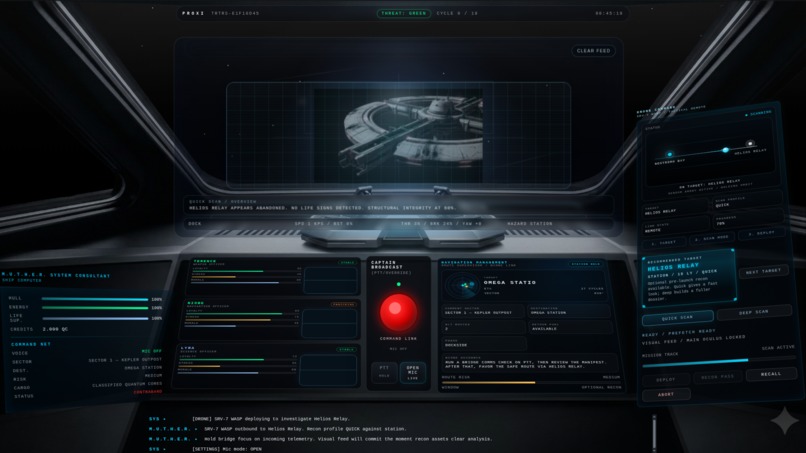
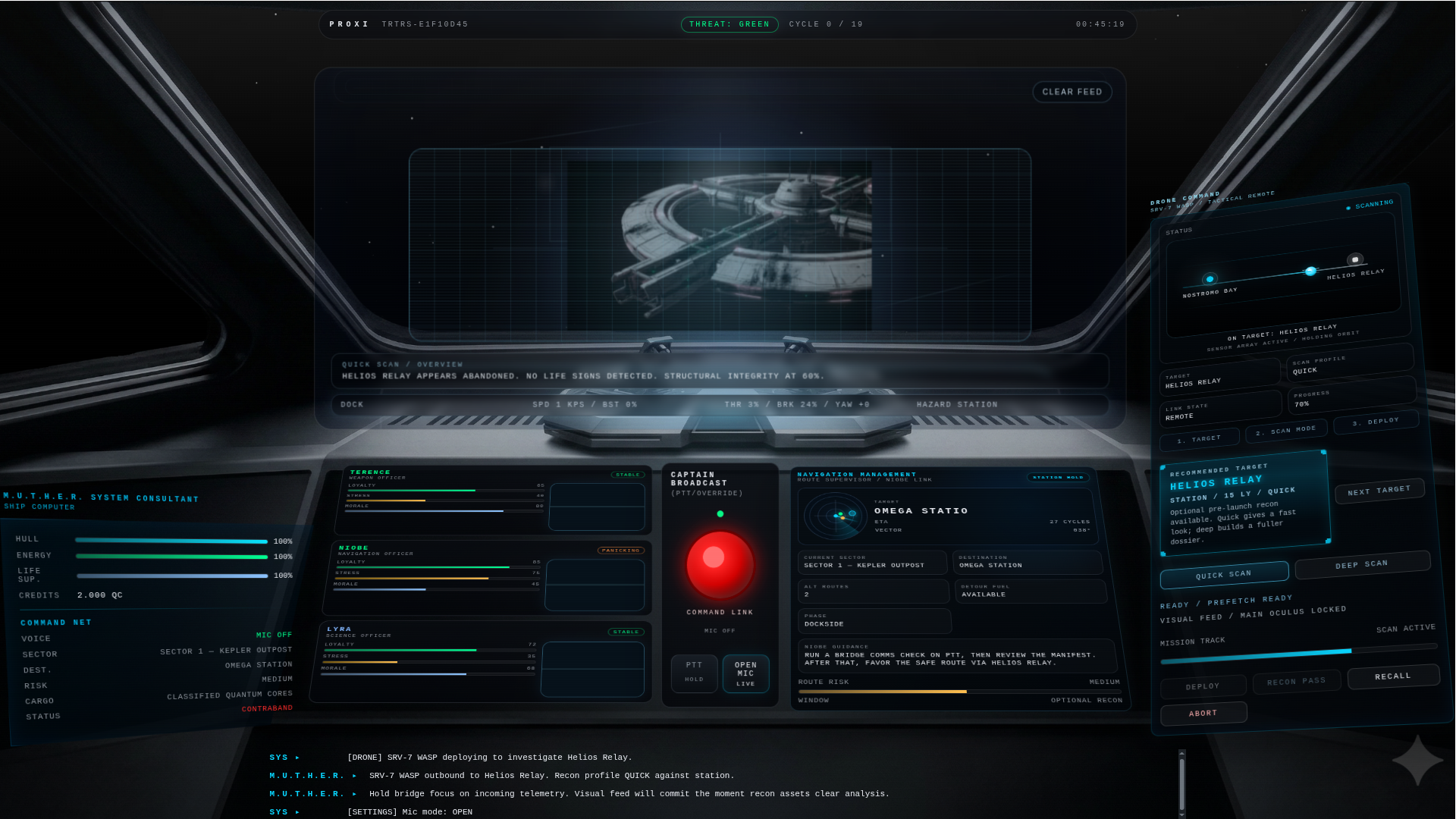
- drone recon and visual evidence
- semantic and evidence memory
- real-time tactical UI updates
Our goal was to make the player feel less like someone operating an interface and more like someone standing inside a living story world.
How we built it
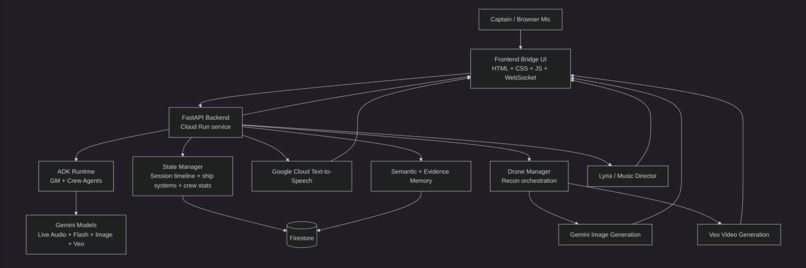
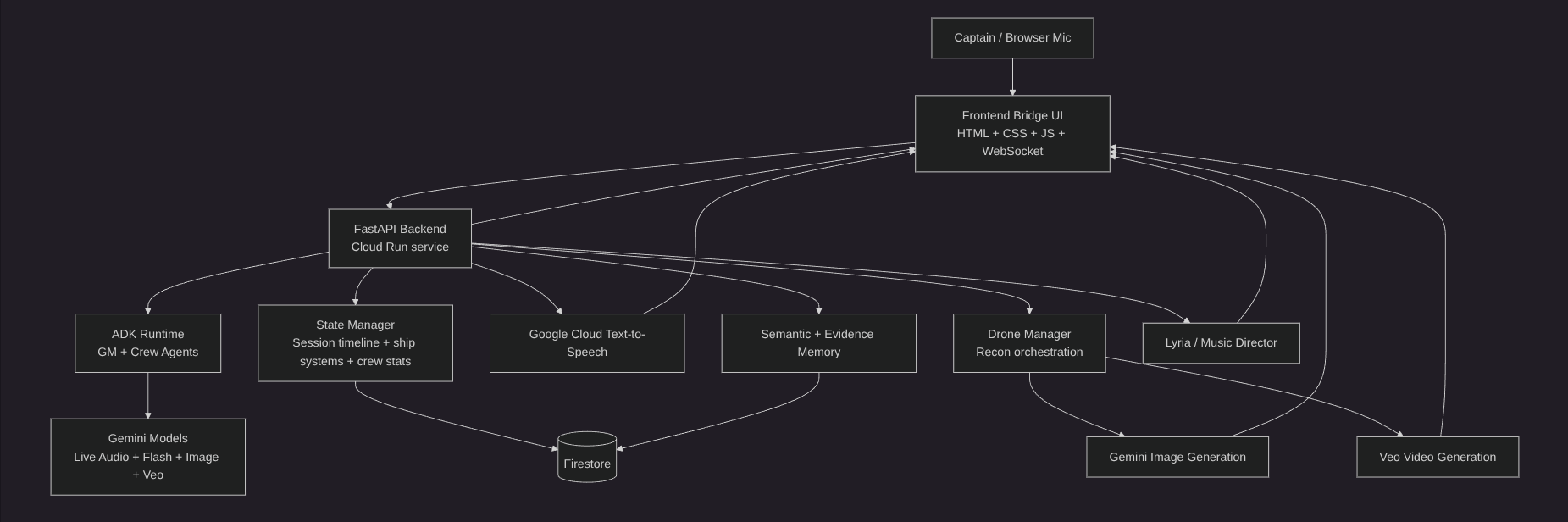
We built PROXI as a browser-based frontend with a Python backend running on Google Cloud.
The frontend is a live bridge UI built with HTML, CSS, and JavaScript. It handles cockpit rendering, voice interaction, crew panels, waveform displays, interleaved media surfaces, drone controls, and real-time state updates over WebSockets.
The backend is a FastAPI service deployed on Google Cloud Run. It manages game state, procedural mission flow, media orchestration, live agent coordination, and runtime broadcasting.
For the AI stack, we used:
- Google ADK for agent orchestration
- Google GenAI SDK for Gemini model access
- Gemini live native audio for voice interaction
- Gemini Flash for orchestration and runtime generation
- Gemini image generation for visual outputs
gemini-embedding-2-previewfor evidence memory retrieval- Veo for cinematic video generation
- Lyria for music direction
- Google Cloud Text-to-Speech for synthesized ship/system voice
- Firestore for cloud-backed state and memory support
Architecturally, ADK handles the live bridge agents and dialogue orchestration, while a separate media director layer stages image, interleaved, and video generation around mission events.
Challenges we ran into
The biggest challenge was making the experience feel live instead of stitched together.
Voice systems can quickly become noisy, especially when narration, crew dialogue, UI updates, and media generation all happen at once. We had to carefully tune pacing, event timing, startup behavior, and audio layering so the experience felt cinematic rather than chaotic.
Another challenge was multimodal continuity. Once generated visuals, recon findings, and prior mission decisions enter the experience, players expect the world to remember them. That pushed us to build both semantic memory and evidence memory, so earlier discoveries could shape later events and recalls.
We also had to solve practical deployment issues near the end, including Cloud Run staging, secure websocket behavior over HTTPS, and asset packaging for the deployed build.
Accomplishments that we're proud of
We are most proud that PROXI does not feel like a standard assistant demo.
It feels like a live bridge:
- the captain speaks directly to the ship
- crew members respond with different priorities and personalities
- tactical state changes in real time
- mixed media appears as part of the story surface
- drone recon creates memorable visual moments
- memory gives continuity across the run
We are also proud that the project satisfies the challenge requirements in a meaningful way rather than superficially: Gemini is central to the experience, ADK is used for agent orchestration, and the backend is deployed on Google Cloud Run.
What we learned
We learned that voice UX needs state, not just transcription.
A voice interface becomes much more believable when it knows what phase the player is in, what the ship is doing, which character is speaking, and what has already happened. We also learned that multimodal storytelling works best when text, visuals, and audio are staged together instead of being treated as isolated features.
Another major lesson was that immersion is often broken by interface conventions. By pushing the keyboard into the background and letting voice drive the roleplay, the entire emotional texture of the experience changed.
What's next for PROXI
Next, we want to deepen the simulation and make the bridge feel even more alive.
That includes longer mission arcs, richer crew relationships, stronger interruption handling during live voice conversations, more reactive recon flows, and tighter multimodal pacing so cinematic moments happen with even greater precision.
Longer term, we see PROXI as a foundation for voice-first narrative games where the player does not just prompt a system, but inhabits a world that listens, remembers, and responds.
Built With
- css
- fastapi
- gemini
- gemini-2.5-flash-native-audio-preview-12-2025
- gemini-3.1-flash-image-preview
- gemini-3.1-flash-lite-preview
- gemini-embedding-2-preview
- google-adk
- google-cloud-firestore
- google-cloud-run
- google-cloud-text-to-speech
- google-genai-sdk
- html
- javascript
- lyria
- python
- veo
- websocket

Log in or sign up for Devpost to join the conversation.