Inspiration
I shop secondhand constantly. And every time I find something I love on Depop or Poshmark, I hit the same wall. No reviews, no ratings, nothing telling me if it runs small, if the fabric shrinks, if it's actually worth it. I'm making a real financial decision completely blind. Phia already solves where to buy something for less. I built Provenance to solve whether it's worth buying at all.
What it does
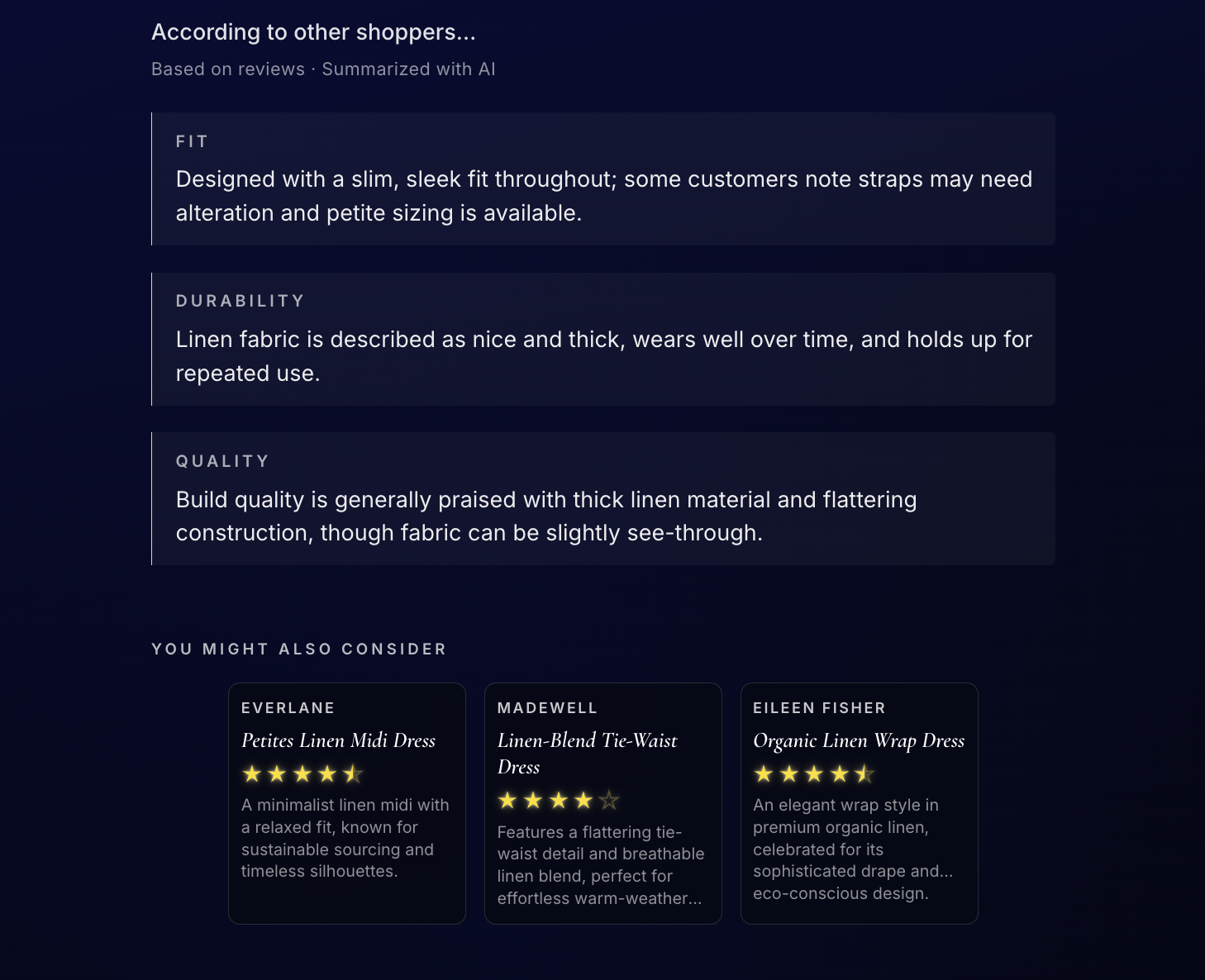
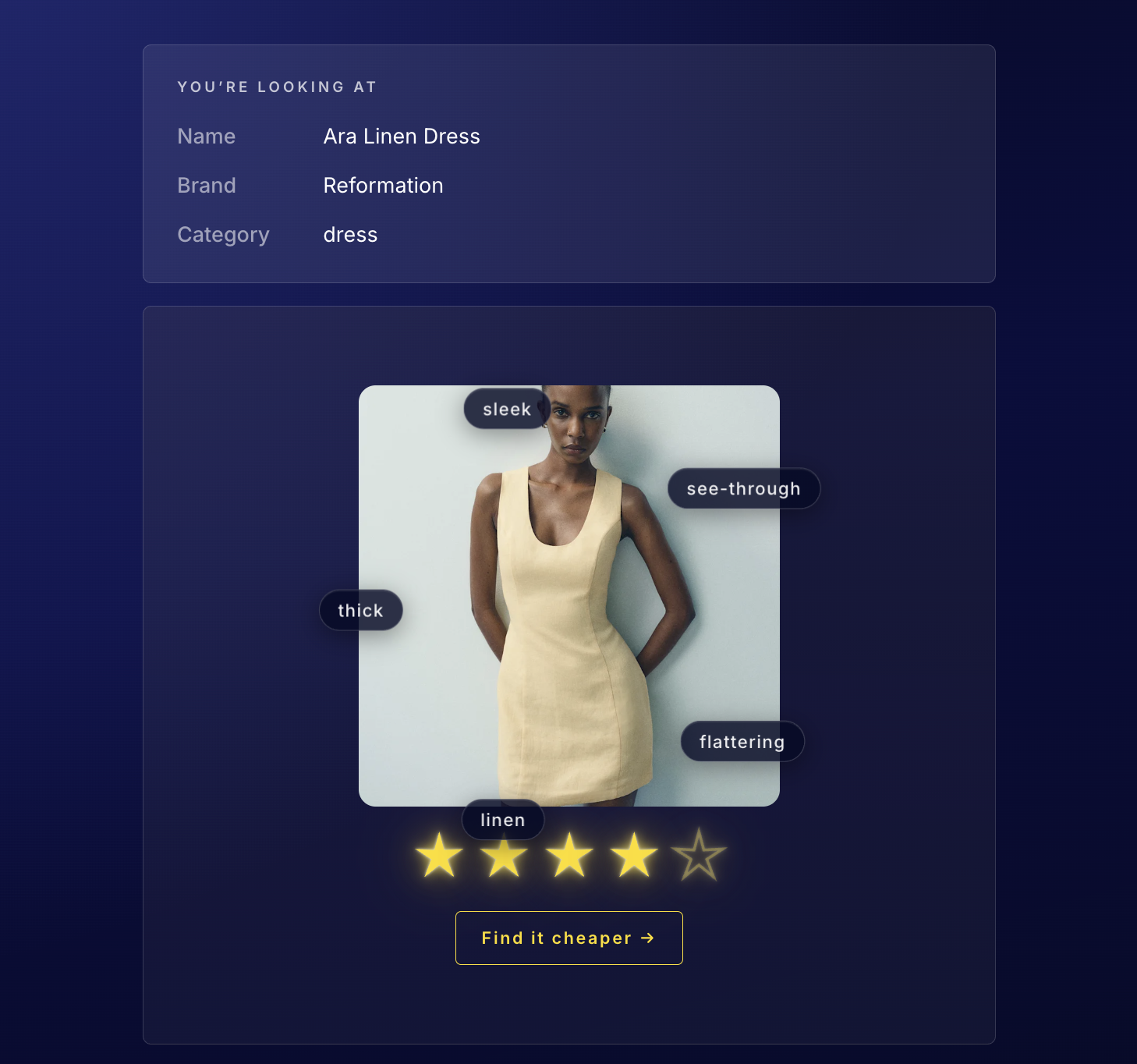
Provenance takes any product URL from any store, any platform, secondhand or retail, and returns a complete sentiment profile sourced from public reviews across the internet. In seconds, a shopper sees a star rating based on overall sentiment, three category insights covering Fit, Durability, and Quality, five keywords pulled directly from real buyer language, a product image, a similar items comparison panel, and a Find it cheaper button that hands them directly to Phia.
How I built it
The pipeline has three steps. First, the URL is sent to Claude, which infers the product name, brand, and category from the URL structure alone with no page scraping required. Second, that product name and brand go to SerpAPI, which runs a Google search and returns review snippets from retail sites, blogs, Reddit, and buyer Q&A sections, all concatenated into one review blob. Third, that blob goes back to Claude with a structured prompt returning a clean JSON object containing the star rating, fit, durability, quality insights, and keywords. A separate Claude call generates the similar items panel.
Challenges I ran into
The biggest early blocker was the scraping wall. The original approach used BeautifulSoup to fetch product page HTML, but Depop, Poshmark, and Zara all block bot requests and return empty pages. So, I have to pivot. Claude can infer product name, brand, and category from the URL string alone, since product URLs almost universally contain brand and product name slugs in their structure. This made the identification layer faster and more reliable. Additionally, CSS layout conflicts from rapid iteration caused elements to overlap the product image, resolved by enforcing strict normal document flow throughout.
Accomplishments that I'm proud of
Building a fully functional, real-time AI pipeline from scratch in under 24 hours, solo! The URL-only product identification approach is something I'm particularly proud of because it turned a blocker into an elegant solution. The final product works on any URL from any platform and returns genuinely useful, nuanced sentiment that a real shopper would act on.
What I learned
Less is more. Dropping the scraping layer entirely made Provenance faster, more reliable, and more elegant. Also, getting Claude to return clean parseable JSON consistently required the same precision and iteration as any other part of the stack. And scoping it under time pressure is a skill in itself, which I am glad to have practiced.
What's next for Provenance — Social Shopping for Phia
A few things I'd build with the Phia team with more time. First, a Chrome extension so Provenance works directly on any product page without needing to copy and paste a URL. Second, pulling real-time secondhand listing data into the similar items panel so comparisons are based on actual available inventory, not mock data. Third, Reddit integration as an additional review source since fashion communities there are brutally honest in ways that retail review sections aren't. And of course, integration inside Phia so the sentiment score lives directly on every listing.


Log in or sign up for Devpost to join the conversation.