
Inspiration 💡
Cultural collections are full of stories but provenance (who owned what, when, and how) is often buried in long, tricky paragraphs. Curators and restitution researchers need a faster way to spot red flags (Nazi-era trades, post-1970 exports, seizures) and then explain why an object needs attention. We set out to turn raw provenance text into a searchable, explainable, policy-aware experience you can explore live.
What it does 🎯
Provenance Radar lets you:
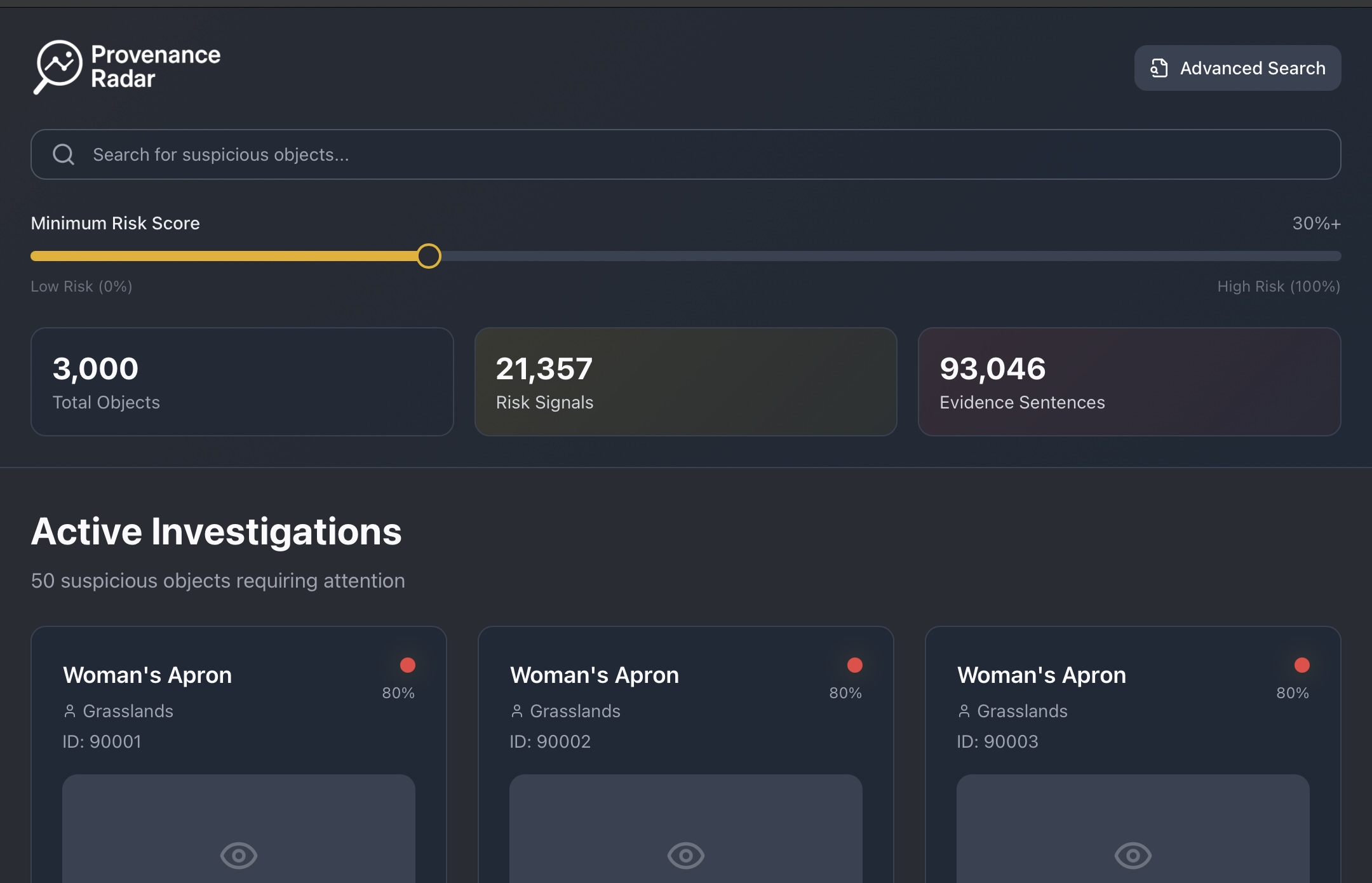
- Spot likely cases quickly — A ranked list of artworks with clear scores and simple clues showing why they surfaced.
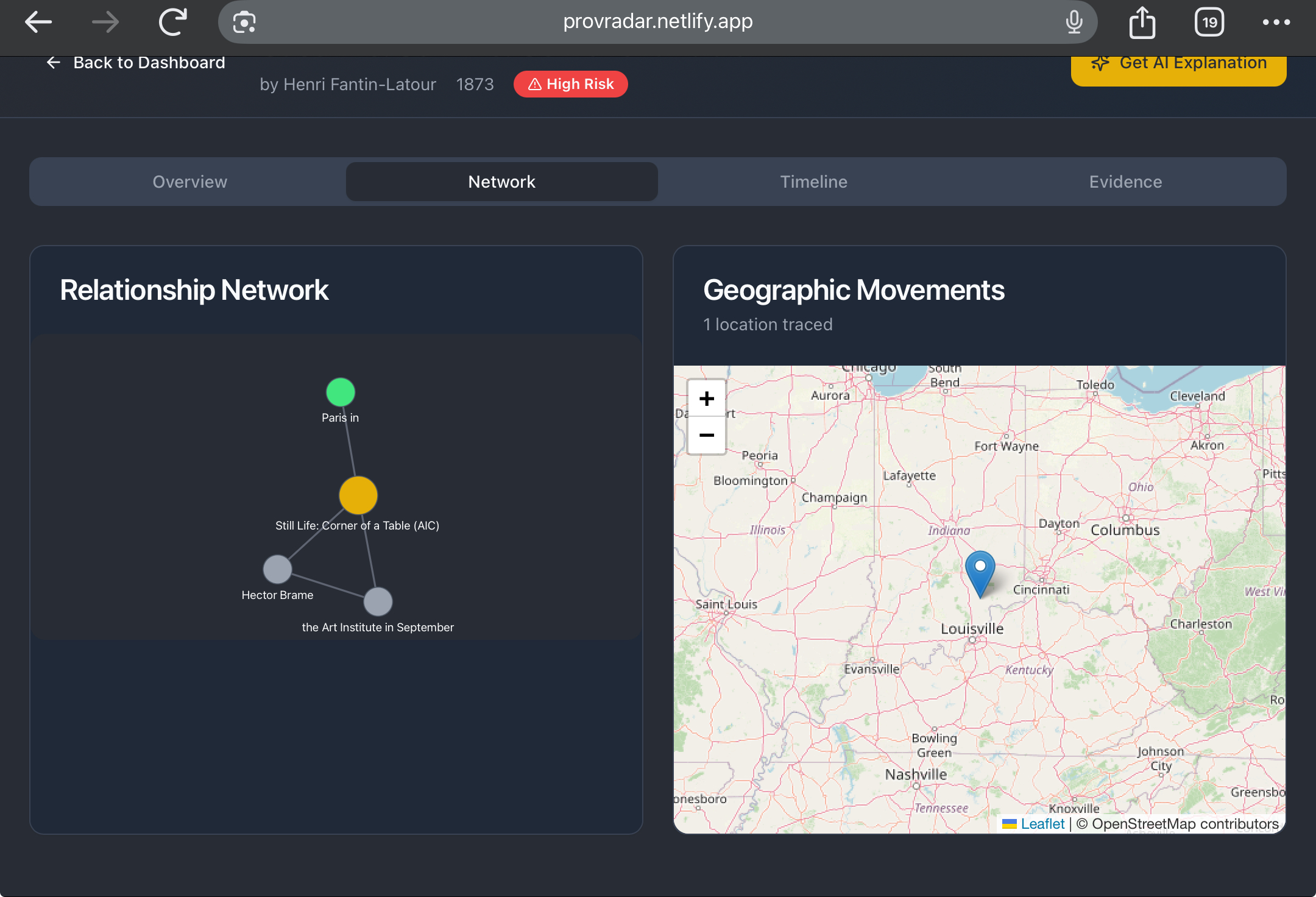
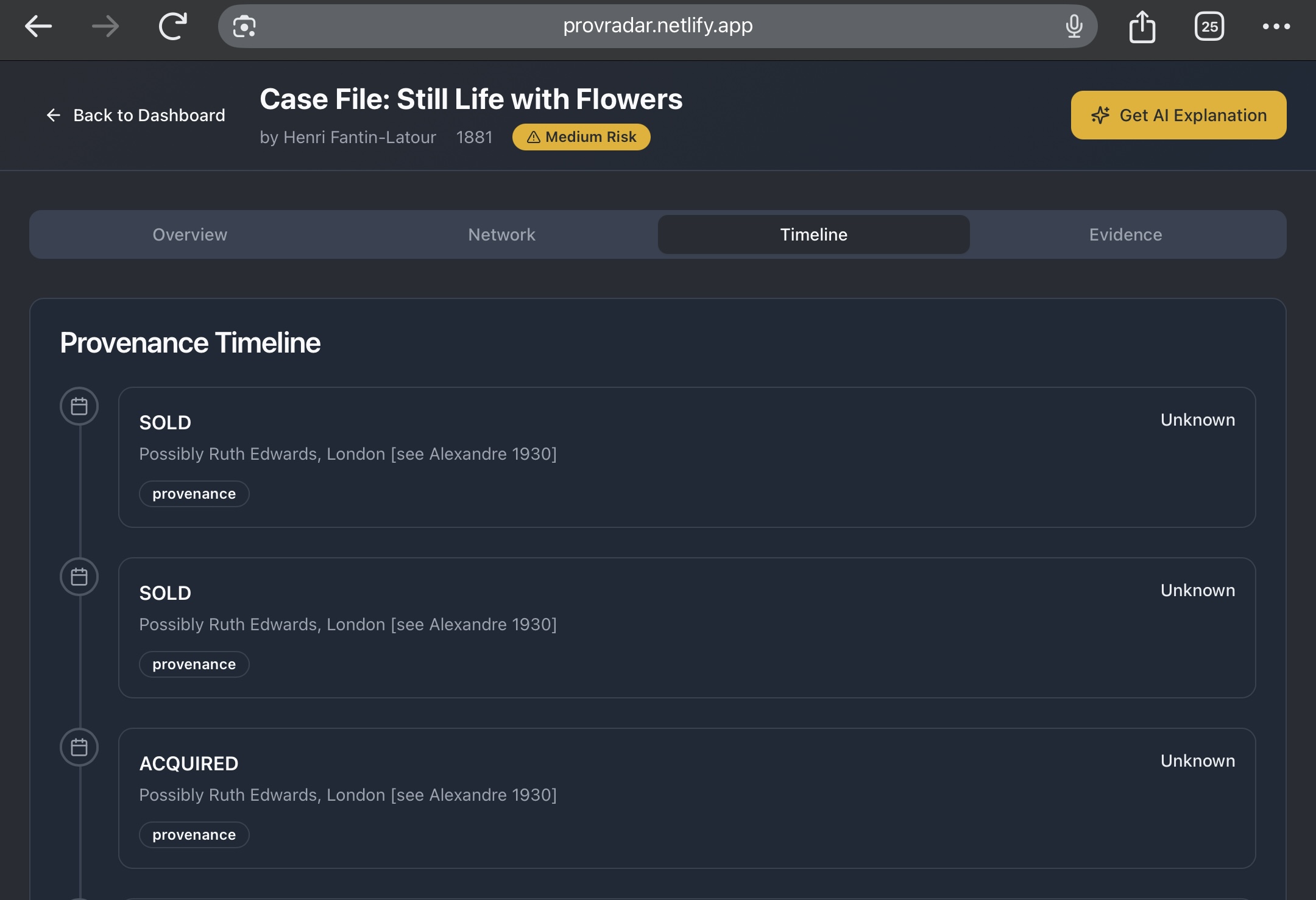
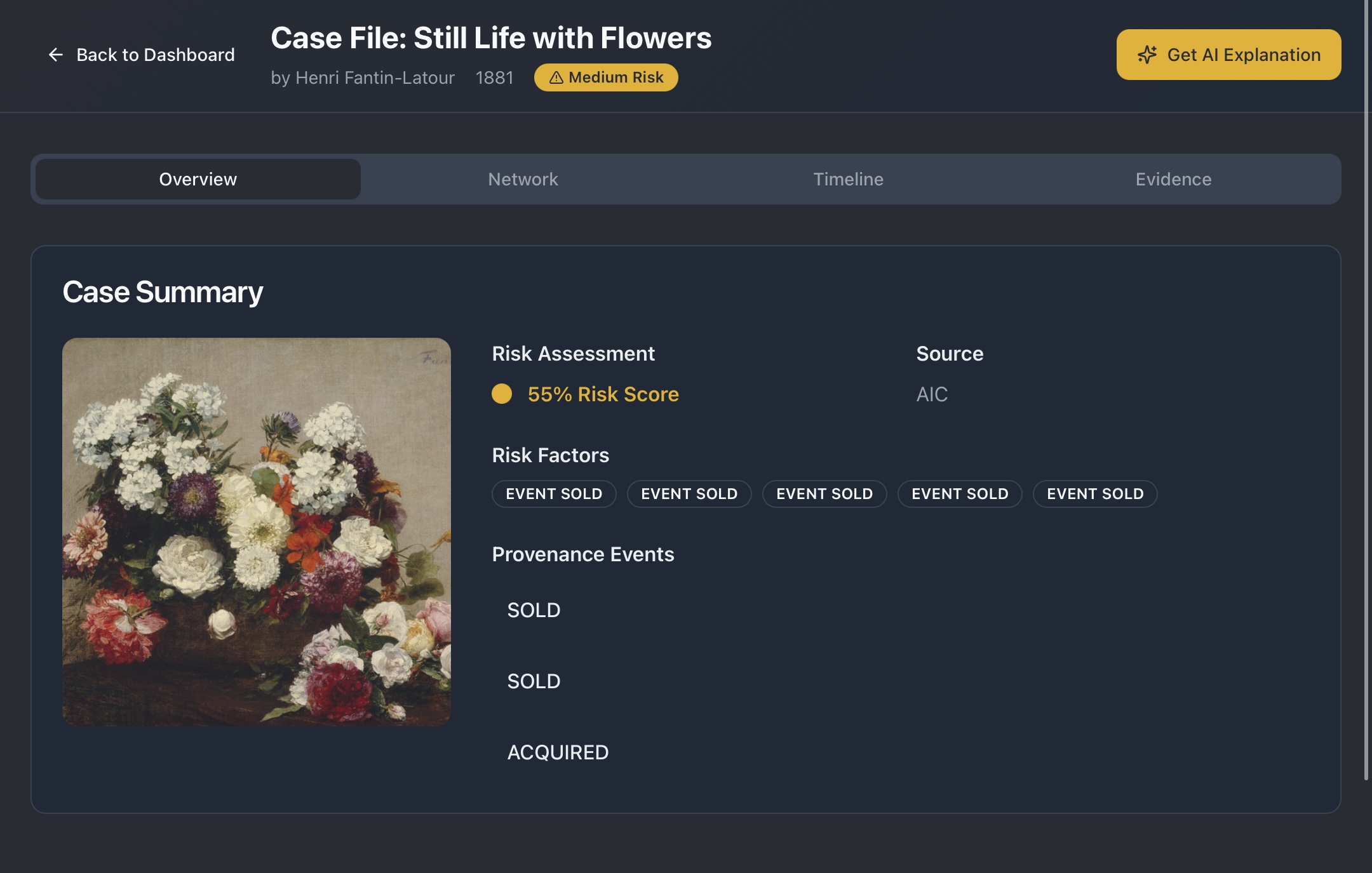
- Open a casefile — See the original sentences, a tidy timeline, and a visual map of owners and places in one view.
- Search by meaning — Type what you’d say out loud (“sold in Berlin in 1941 via auction”) and see the closest matches across the whole corpus, grouped by artwork so you don’t wade through repeats.
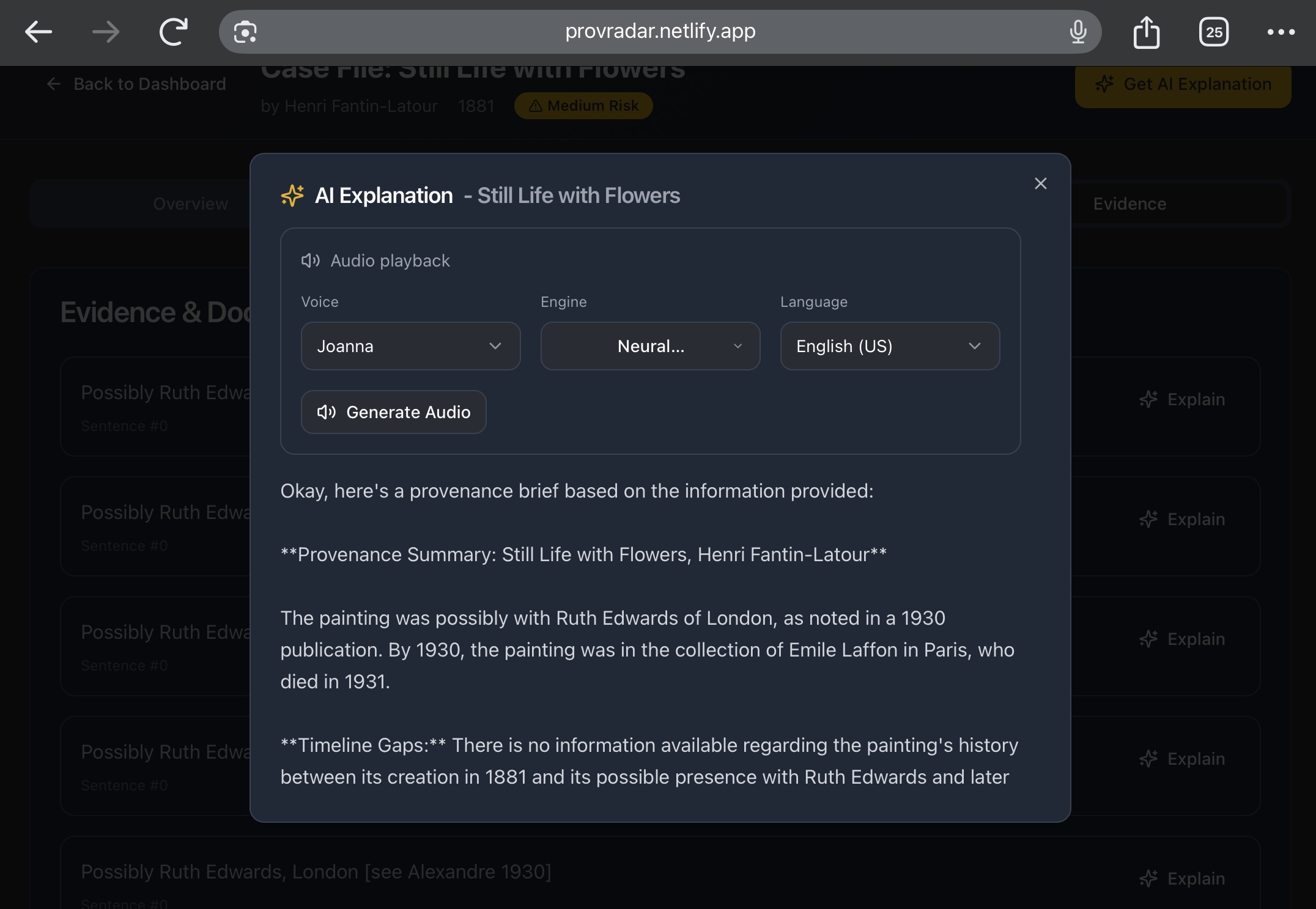
- Get quick explanations — Optional notes powered by Gemini AI that summarize why an object looks risky and suggest next steps (for humans to verify, not replace).
How we built it 🏗️
Data & pipeline
We start with public museum data (e.g., the Art Institute of Chicago). We fetch records, split the long provenance paragraphs into sentences, and create compact “fingerprints” of each sentence so the app can understand meaning, not just keywords. We add light rules to pick up events (sold, exported, exhibited…) and years, then score helpful signals so promising objects float to the top.
The database (our center of gravity)
All of this sits in TiDB Cloud, a cloud database that feels like MySQL but scales comfortably. It stores objects, sentences, extracted events, and scores in one place, so the app can search, sort, and load casefiles instantly. Even when the data grows, the experience stays snappy.
The API
A small Flask service (hosted on Hugging Face) feeds the frontend: lists, objects, graphs, timelines, semantic search, policy windows, and the optional “explain” notes. We also normalize raw risk numbers into an easy 0–99 style scale so scores are consistent and readable.
The app
A simple React frontend renders three panels,Context, Graph, and Details, with a dark, focused interface. Click a lead, and you’re straight into sentences, events, people, places, and dates, no hunting.
Assistive AI & narration
- Gemini AI drafts short, cautious summaries and suggested checks directly from the on-screen context (you can toggle it on or off).
- For demos and accessibility, we use puter.com’s free TTS to generate voice narration, so anyone can play a quick walkthrough without recording audio.
Architecture

Challenges we ran into 🧩
- TiDB vector search spikes: full-corpus
ORDER BY VEC_COSINE_DISTANCEcould hit1105OOM → fixed with a candidate CTE (pre-TopK) + index hints and an adaptive retry that shrinks candidates. - Duplicate search hits: semantic search ranks sentences, not objects →
ROW_NUMBER() OVER (PARTITION BY object_id)to return one best sentence per object (no dupes, no 404s). - Risk score semantics: upstream scores were ratios (2.0 = 200%). Mapped on the percent domain with a piecewise curve; API now overwrites
risk_scoreand keepsrisk_score_raw. - ABI/runtime hiccups on Spaces: NumPy 2.x clashes → ran SBERT Torch-only (
convert_to_tensor=True), pin NumPy defensively. - Date serialization: mixed MySQL/Python types broke graphs/timelines → one
to_iso()everywhere. - Edge reliability: public DB over TLS → per-request connections, retries/backoff, strict SQL modes, tuned timeouts.
Accomplishments that we're proud of 🏅
- A full path from museum text to a clean, explorable casefile—end-to-end.
- Leads that aren’t a black box: each score comes with simple, visible clues.
- One-click context: graph, timeline, and sentences in the same place. Gemini AI notes that save time drafting, while keeping humans in charge.
What we learned 📚
- Do the heavy lifting in SQL: TiDB + window functions + CTEs keep search fast and predictable.
- Dedupe at the source: one row per object from the API simplifies the UI and kills 404s.
- Normalize + log: transform ratios to human scales server-side and log raw→norm to debug instantly.
- Stay Torch-native: avoiding NumPy in embeddings sidesteps ABI issues and reduces cold-start surprises.
- Be boring with dates: a single
YYYY-MM-DDhelper saves hours of edge-case chasing. - Graceful degradation wins: candidate shrinking, fallbacks, and cache headers keep the demo feeling solid.
- AI as assist, not authority: Gemini for concise briefs/next checks; humans verify.
What's next for Provenance Radar 🚀
- Add more collections (Cleveland, Rijksmuseum, MoMA, Wikidata SPARQL) and refresh nightly.
- Open the repo for collaboration between art experts and software engineers.
- Improve event picking with light NER and alignment to authorities (e.g., people and place vocabularies).
- Link related cases across institutions, owners, places, and time windows.
- Reviewer workflows: save leads, add notes, export briefs, share permalinks.
- Stronger transparency: standardized disclaimers, confidence hints, and clear “why” for every flag.
Provenance Radar turns messy sentences into an explainable, policy-aware map of ownership—fast enough to explore live, and clear enough to trust. Backed by TiDB, guided by Gemini AI for summaries, and easy to demo with puter.com’s free TTS.
TiDB cloud account: cmatondo2000@gmail.com
Built With
- flask
- gemini
- puter
- python
- react
- tidb
- typescript

Log in or sign up for Devpost to join the conversation.