-
-
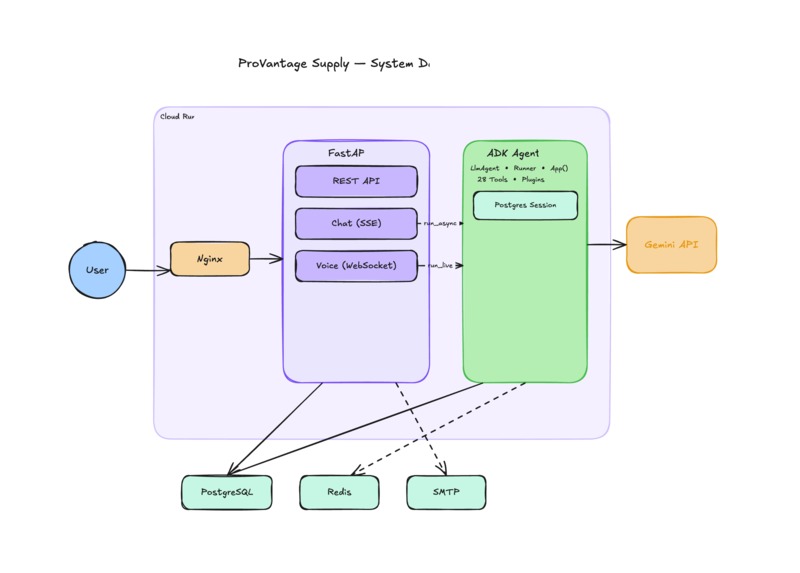
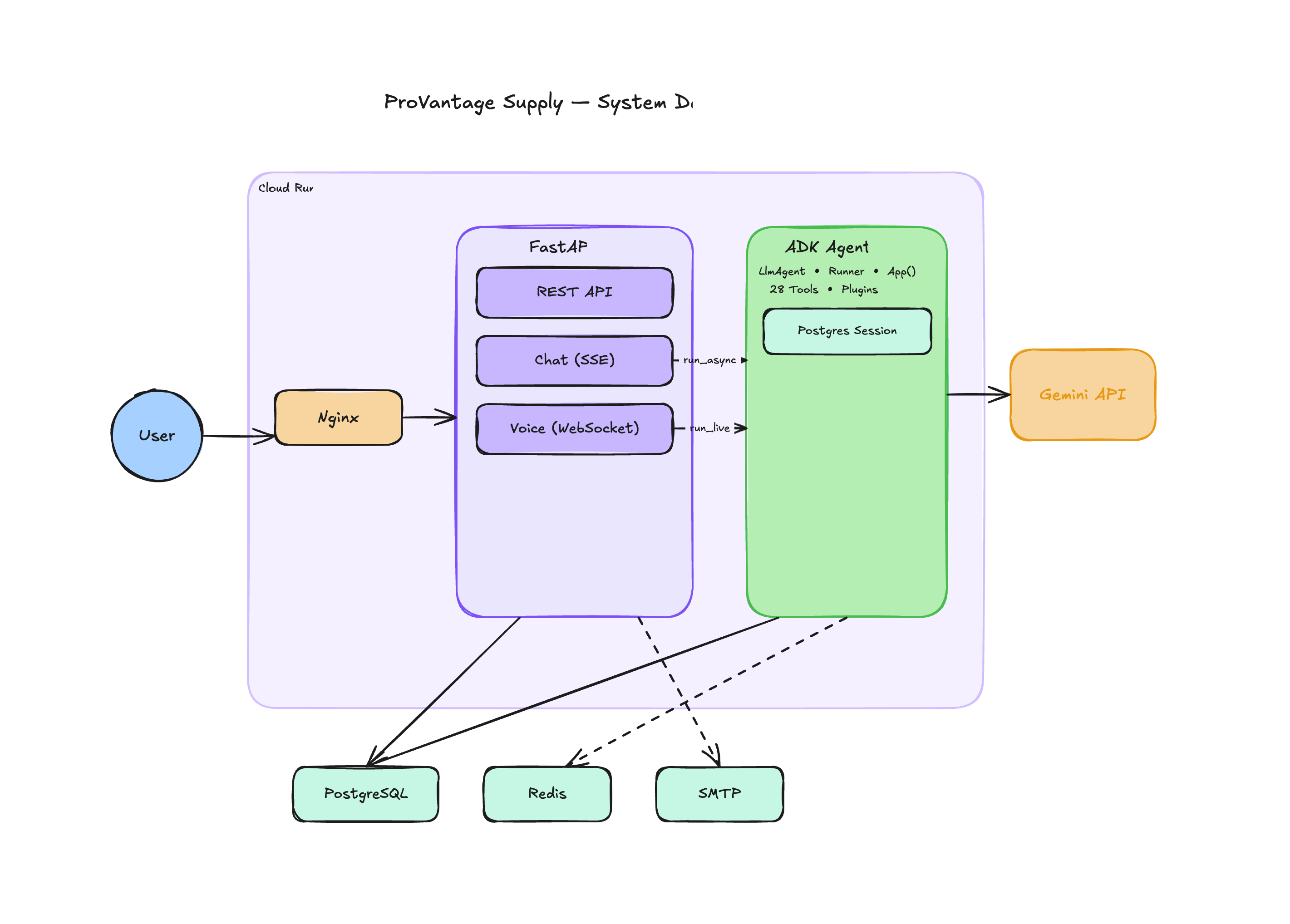
arch 2
-
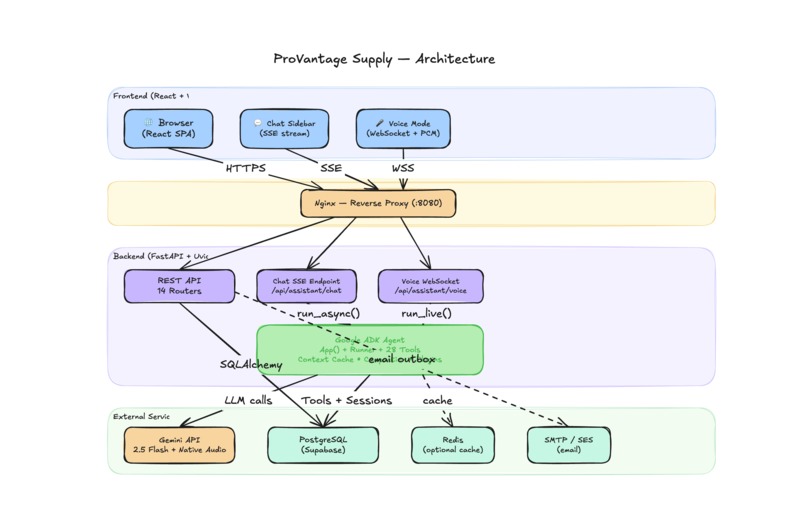
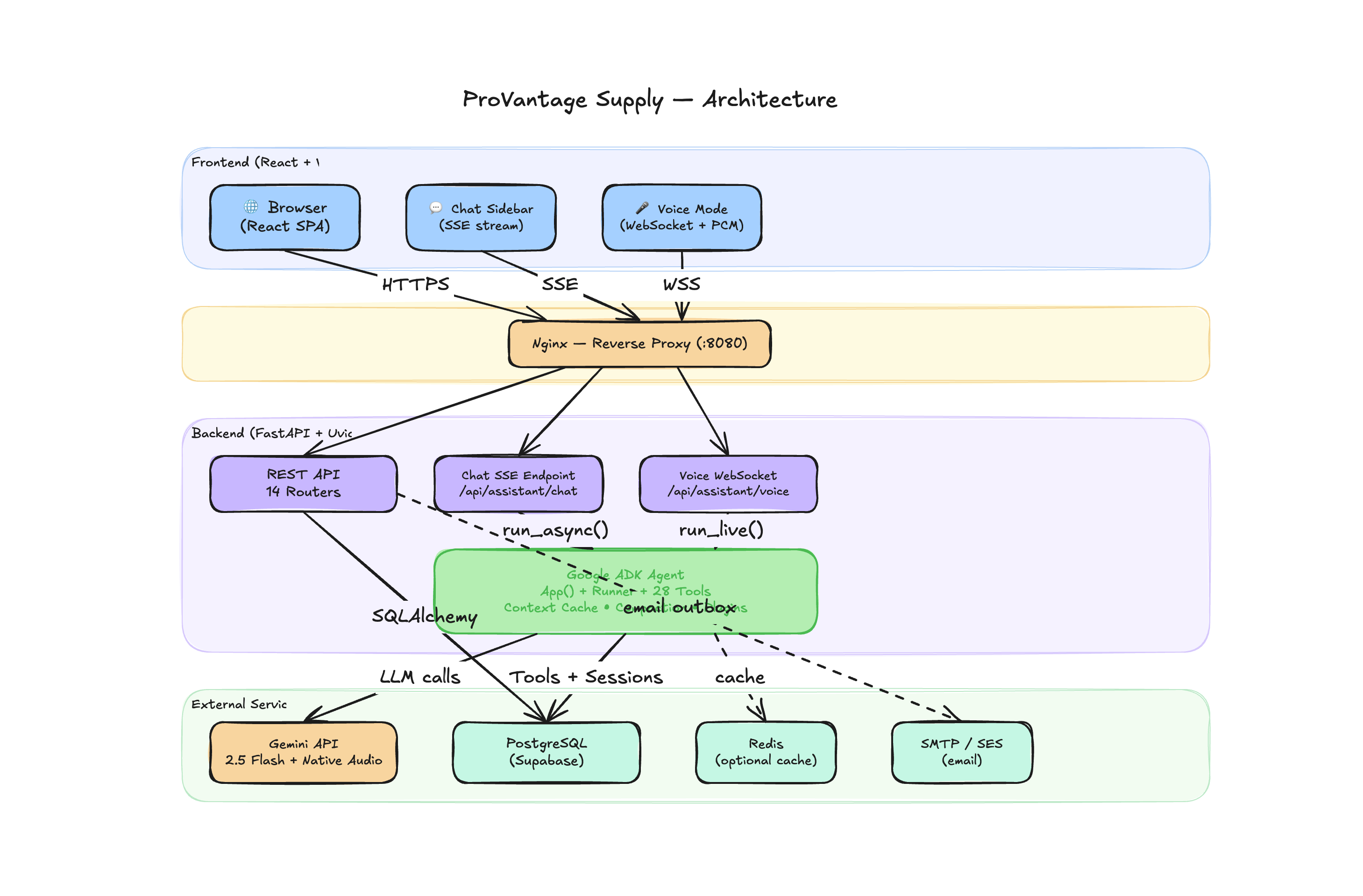
arch 1
Inspiration
Shopping online with a voice assistant should feel like talking to a knowledgeable store associate — someone who knows your order history, can pull up exactly what you need, and doesn't lose the thread when you switch from speaking to typing. Every voice commerce demo I'd seen was either a scripted toy or a disconnected bolt-on that forgot everything the moment you closed the mic.
I wanted to build the version that actually works: a real e-commerce store with a real database, real auth, and an AI shopping assistant that handles both voice and text in the same conversation, using the same session, with no context reset between them. The Google ADK hackathon was the forcing function to finally do it properly.
What it does
ProVantage Supply is a professional contractor supply storefront where the shopping assistant is a first-class citizen, not an afterthought.
- Browse, search, and buy across 100+ products in 6 trade categories (Plumbing, Electrical, Tools, HVAC, Paint, Flooring) with a full cart, checkout, order history, wishlist, and saved addresses
- Text assistant — a sidebar chat panel backed by 20+ Google ADK tools: search products, add to cart, check order status, navigate pages, suggest a shipping address, manage your wishlist, and more — all streaming in real time over SSE
- Voice assistant — click the mic and the same agent handles bidirectional audio via Gemini's Native Audio Live API. Speak naturally, hear the response back. Switch mid-conversation between voice and text — the agent remembers everything
- Full auth — email/password registration with email verification, magic link login, password reset, JWT cookies, and rate-limited endpoints throughout
- Cloud Run deployment — single Docker container (nginx + uvicorn + supervisord), production-ready
How I built it
I started from a production-grade FastAPI + React monorepo — not a scaffolded demo, but a real storefront with PostgreSQL, server-calculated pricing, JWT auth, email outbox with retry semantics, and account management. That gave the AI assistant real tools to work with: actual database queries, live cart mutations, real order lookups.
Text assistant — Google ADK's LlmAgent + Runner connects Gemini 2.5 Flash to typed tool functions. Every tool returns a ToolResult — {success, data, error} — so the agent handles failures cleanly instead of hallucinating. The ADK App wrapper added context caching (the system prompt is cached to Gemini's cache layer) and session compaction for long conversations.
Voice assistant — I used runner.run_live() with Gemini 2.5 Flash Native Audio Preview over a WebSocket, sending and receiving raw PCM audio bidirectionally. The critical design decision: both transports share the same session_id. Whether the user typed or spoke, the ADK session service (Redis-backed on Cloud Run, in-memory locally) maintained full context. Switching modes doesn't clear anything.
Frontend — React 18 + TypeScript + Vite + Tailwind CSS v4. The voice UI awaits a confirmed WebSocket open before setting any state — no optimistic voiceMode = true that strands the user in a dead mic state. All event callbacks are ref-stabilized to prevent render cascades from dropping stream events mid-response.
Deployment — Multi-stage Docker build. nginx serves the React frontend, uvicorn runs FastAPI, supervisord keeps both processes up. Deployed on Google Cloud Run with environment-injected secrets.
Challenges I ran into
WebSocket lifecycle with the Live API is unforgiving. The Gemini Live API connection must be fully established before you acknowledge it to the user. An optimistic state flip before the socket opens leaves the UI frozen if the connection fails. I ended up implementing a Promise<boolean>-based connect() with a 10-second timeout and stale-epoch guards — voiceMode only flips on confirmed open.
Streaming callbacks cascade renders. Every onEvent and onDisconnect handler passed as an inline prop recreated itself on every render, which caused ADK event handlers to be torn down and replaced mid-stream, silently dropping messages. Stabilizing them all in refs was non-negotiable.
Per-IP rate limiting breaks across uvicorn workers. With multiple workers behind nginx, each worker has its own in-process counter — so rate limits are ineffective. Voice connections in particular needed cross-process enforcement. I moved to a Redis-backed counter keyed on voice_rate:{client_ip} with a 60-second TTL and graceful fallback when Redis is unavailable.
WebSocket origin validation is not automatic. Browsers enforce CORS for HTTP requests but not for WebSocket upgrades. Without an explicit origin check, any page can open a mic connection to the backend. I added validation against the CORS_ALLOWED_ORIGINS allow-list in the voice endpoint.
Tool confirmation is a no-op in bidi streaming mode. ADK's require_confirmation flag doesn't work in live mode — there's literally a # TODO comment in the ADK source for this. For destructive tools like clear_cart, I replaced it with instruction-level two-phase patterns: the agent verbally confirms the action before calling the tool, enforced entirely through the system prompt.
Accomplishments that I'm proud of
Shipping a voice assistant that actually shares state with the text assistant — not two separate agents pretending to be one. A user can type "find me copper pipe fittings", get results, switch to voice, say "add the first one to my cart", and the agent knows exactly what "the first one" refers to. That continuity is the whole point, and it works.
I'm also proud that this is a real application, not a demo veneer over mock data. Rate limiting, token-based auth, email verification with retry semantics, server-calculated order totals, proper security on the WebSocket endpoint — the kind of things that get cut in hackathon projects but make the difference between a demo and something you could actually ship.
What I learned
ADK's App wrapper pays for itself immediately. Context caching on the system instruction reduced per-turn latency noticeably on long sessions. Session compaction meant I never had to think about context window overflow. These are not experimental — they work reliably out of the box.
Voice UX demands a different failure model than text. A silent text chat is mildly annoying. A voice session that freezes mid-sentence with no feedback is disorienting. I had to add onDisconnect hooks, stale-epoch detection, disconnect reason surfacing, and mode-transition system messages in the conversation thread to make failures feel intentional rather than broken.
Designing for two transports from the start is far easier than retrofitting one. The agent itself is transport-agnostic — run_async() for text, run_live() for voice, same LlmAgent, same tools, same session service. That architecture is why context sharing works cleanly. If I had built text-only first and bolted on voice later, the session sharing would have been a significant refactor.
What's next for ProVantage Supply - ADK powered shopping experience
- Navigation guard during active voice — switching routes during a call is currently an unsupported edge case that should be handled gracefully
- Voice conversation titles — infer a meaningful title from voice sessions the same way text sessions already generate them
- Multimodal product search — speak what you're looking for and surface visual results alongside the audio response
- Full voice checkout — guide the user through the complete order flow without touching the keyboard, including address confirmation and order placement
- Proactive assistant — nudge the user contextually based on what's in their cart or what page they're on, without waiting to be asked
Built With
- cloudrun
- docker
- fastapi
- gemini
- googleadk
- postgresql
- react
- redis

Log in or sign up for Devpost to join the conversation.