Inspiration
86% of clinical trials miss their enrollment timelines, and the average Phase III trial runs nearly 12 months late. Every delay means patients waiting longer for treatments that could change their lives. Clinical trial protocols are dense, high-stakes documents, and teams often discover operational issues too late, after sites are already struggling. We built ProtoSense to shift that left: identify inefficiencies, timeline risks, and execution bottlenecks before a trial goes live, so teams can prevent avoidable delays and protocol deviations.
What it does
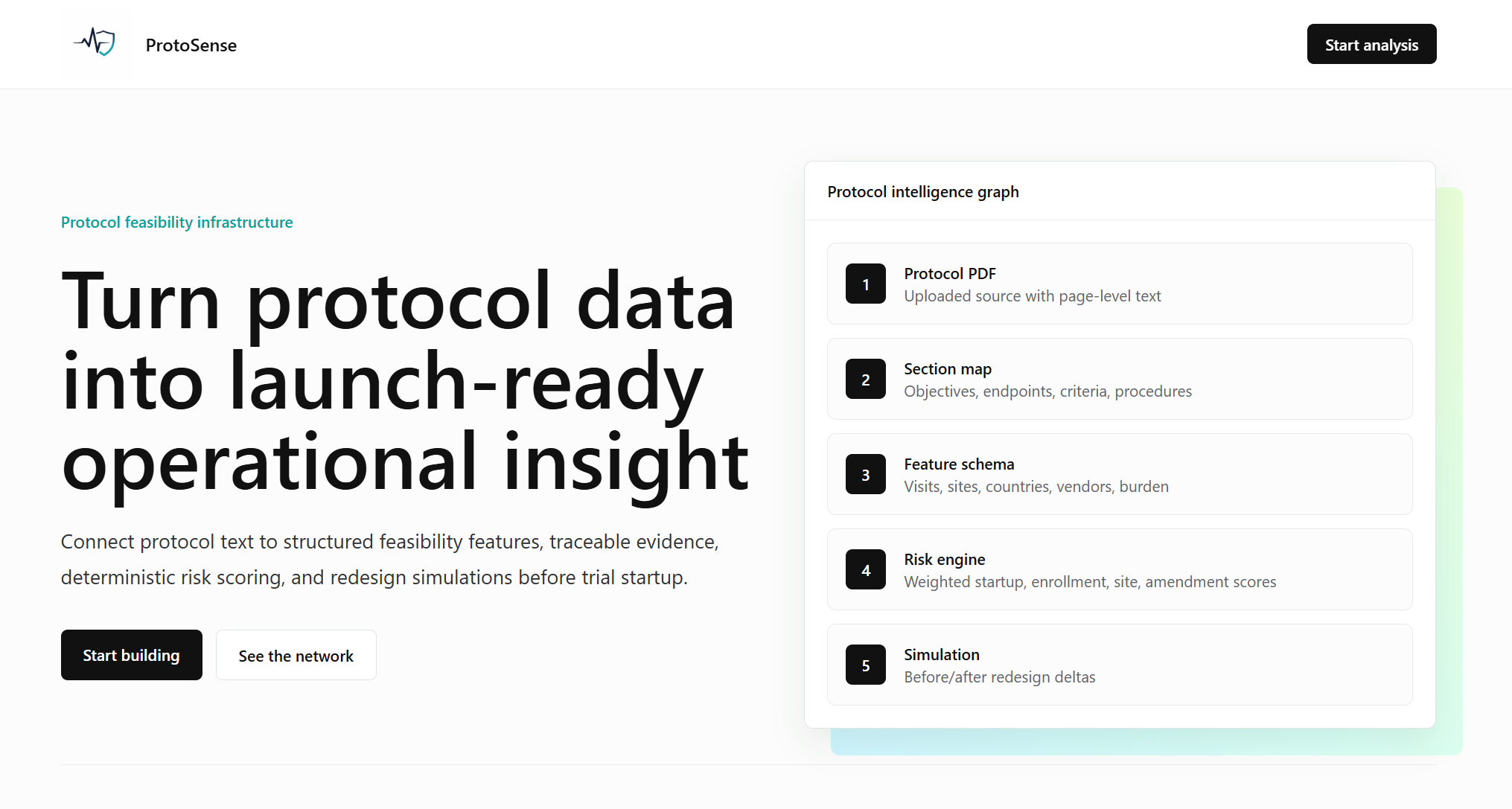
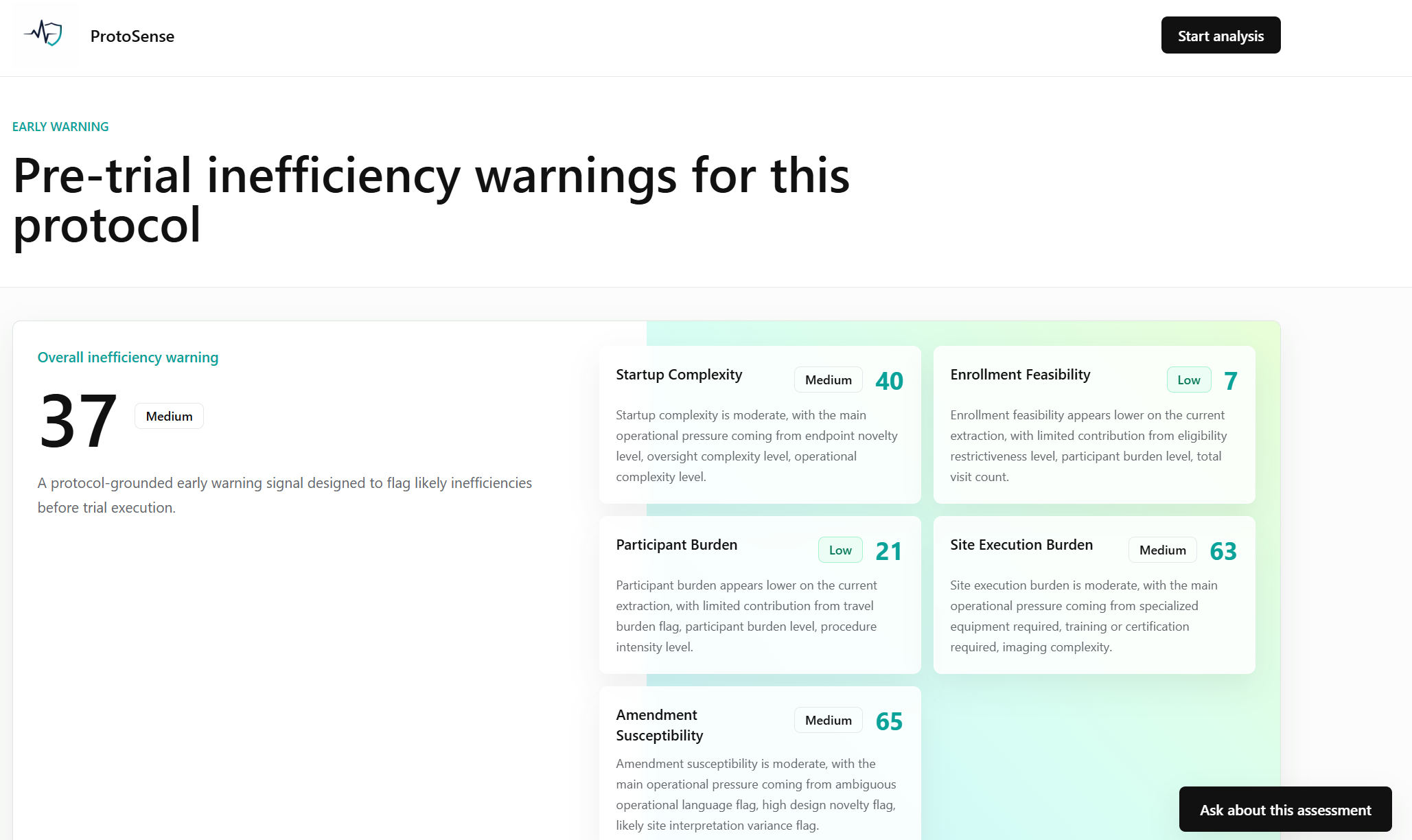
ProtoSense is a protocol feasibility copilot for clinical operations teams. Upload a protocol PDF, and ProtoSense maps every section, extracts operational signals, and generates risk scores across five dimensions: Startup Complexity, Enrollment Feasibility, Participant Burden, Site Execution Burden, and Amendment Susceptibility.
ProtoSense ingests a protocol PDF/text file, structures key operational signals, and generates pre-trial warning insights across startup complexity, enrollment feasibility, participant burden, site execution burden, and amendment susceptibility. It provides:
A risk/warning dashboard with explainable drivers Evidence-backed snippets tied to source sections/pages Action-oriented mitigation recommendations A simulation workflow to test “what-if” assumptions A chat assistant for protocol-grounded Q&A
How we built it
We built a full-stack app with:
Backend: FastAPI + Python services for ingestion, extraction, scoring, recommendations, simulation, and traceability Frontend: Next.js + React + Tailwind for the dashboard and upload/analysis experience Parsing + extraction: deterministic parsing plus optional LLM support for messy protocol sections Scoring: deterministic weighted logic to keep outputs transparent and reproducible Data layer: repository-based persistence and structured schemas for assessment outputs
Challenges we ran into
Parsing real-world protocol text is messy: inconsistent formatting, section headers, and mixed prose/table content Balancing LLM flexibility with deterministic reliability and explainability Keeping recommendations actionable instead of generic Designing a UX that communicates “early warning” clearly without overwhelming users Tight hackathon timeline while integrating end-to-end upload → extract → score → explain flows
Accomplishments that we're proud of
Delivered a working end-to-end MVP from protocol upload to scored dashboard Built evidence-backed outputs, not just black-box scores Added simulation + recommendations to support decision-making, not just monitoring Implemented drag-and-drop upload and clearer, prevention-focused product messaging Created a clean, demo-ready product narrative around pre-trial inefficiency detection
What we learned
In regulated/clinical contexts, explainability and traceability matter as much as model accuracy Deterministic scoring layers are critical for trust and reproducibility Product wording dramatically changes user understanding of value (risk scoring vs. pre-trial warning) Iterating on UX quickly with real feedback improves clarity more than adding extra features
What's next for ProtoSense
Expand protocol coverage with richer section/table extraction and stronger deadline normalization Add site-level benchmarks and configurable warning thresholds Integrate role-specific views (coordinator vs sponsor vs operations lead) Add collaboration workflows: assign actions, track mitigation status, and audit trails Strengthen evaluation with historical/synthetic validation datasets and calibration metrics Prepare production readiness: auth, multi-tenant data isolation, and deployment automation


Log in or sign up for Devpost to join the conversation.