Inspiration
We were inspired by the expressed pain points in clinical trial inefficiencies and the idea of speed and quality developments that places patient needs above all. If addressed, Protoscore could directly impact the level of findings and developments of future patient care solutions.
What it does
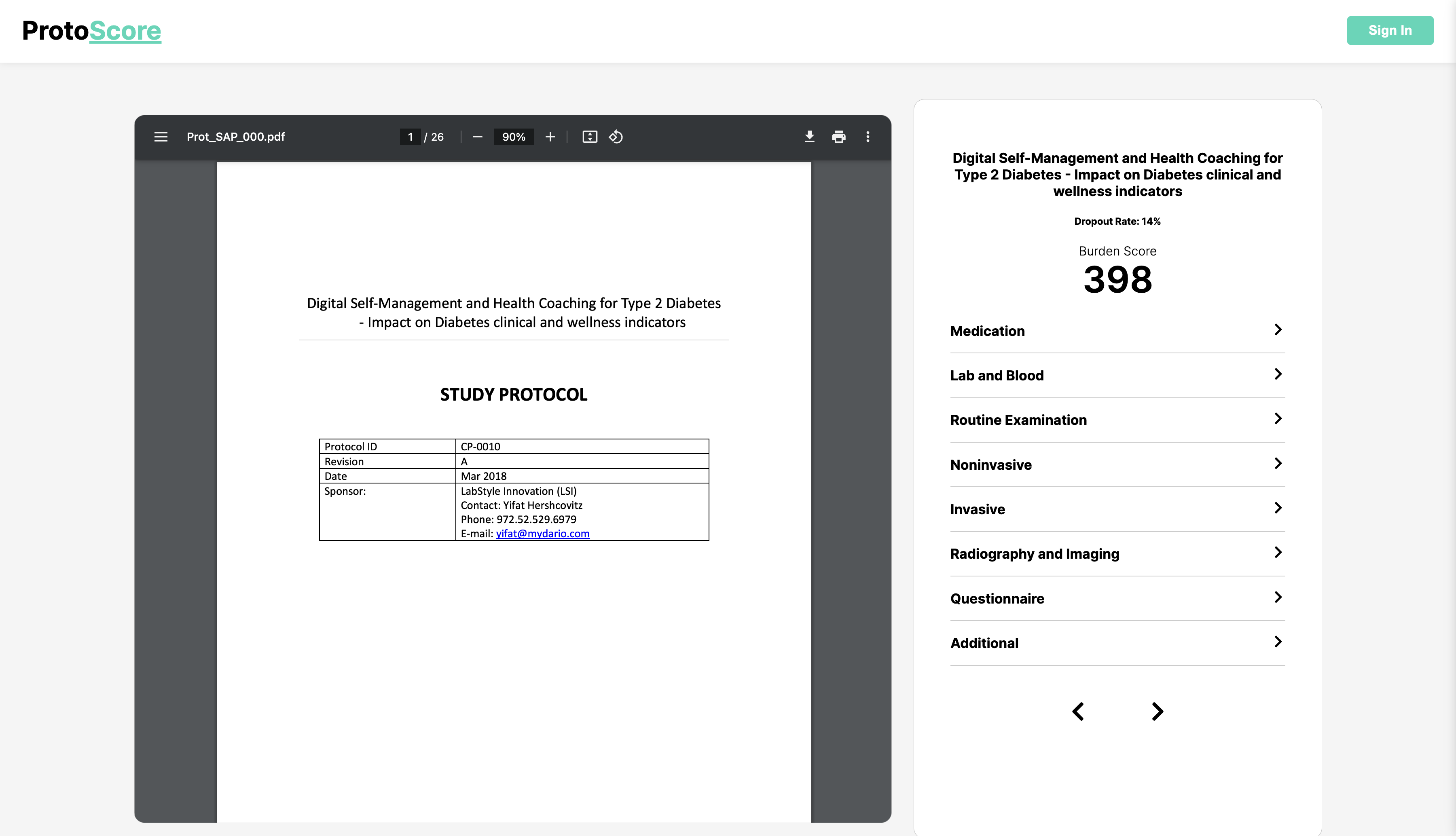
Protoscore works by first allowing users to upload their protocols into the software, which will then assign a burden score and return recommended protocols based on the type of conditions identified. The burden scores are derived from a net weight by cross-referencing metadata cognizant of Zach Smith’s work, like the steps and procedures required to complete a treatment. Protoscore guides the user’s revisions by bringing to attention specific steps and procedures from these related protocols backed by data-driven metrics.`
How we built it
Optical Character Recognition for protocol extraction Frontend: Figma, React JS Backend: OpenAI, Python Considerations: Backend: sklearn Infrastructure: AWS Authentication & Security: Firebase, Express.js middleware to secure API integration
Challenges we ran into
When concerning model training, working around limitations of extensive protocol extraction from clinicaltrials.gov API resulted in us having to web scrape or download individual protocols in order to gather data.
What we learned
We initially struggled with the concept of data provenance in terms of mapping out data conversions between systems into the necessary data storages and structures. We overcame this through highlighted insights by Zach Smith and utilizing a JSON that stores information not only about the sources, links, and authors, but also components extracted from the text.
Accomplishments that we're proud of
Protoscore was developed with the notion of easing the process of clinical trials for healthcare individuals. In doing so, our work has the potential to drastically improve the stride at which patients can receive treatment. We hope that taking part in such a cause inspires others in their developments as much as it did us.
What's next for ProtoScore
Eventually we would like to utilize specific metadata and parameters in order to predict patient dropout rates based on burden score. Additionally, Improving related protocol relevance by taking into consideration factors like the scale of a study can provide valuable feedback.






Log in or sign up for Devpost to join the conversation.