Proteus: Virtual Try-On — See the Fit Before You Buy
Live link: https://proteus-frontend-psi.vercel.app/
Inspiration
The fitting room is broken. Returns cost U.S. retailers over $800 billion annually, and a huge chunk of that comes from online clothing purchases that simply didn't look right on the buyer. We wanted to ask: what if you could see the outfit on yourself before clicking "buy"?
We were also drawn to the technical challenge, diffusion-based image synthesis, GPU-accelerated inference, real-time event delivery, and wanted to prove that a genuinely production-grade AI/ML pipeline could be built entirely on open-source infrastructure running on Linode Kubernetes Engine, with no proprietary inference APIs in sight.
What it does
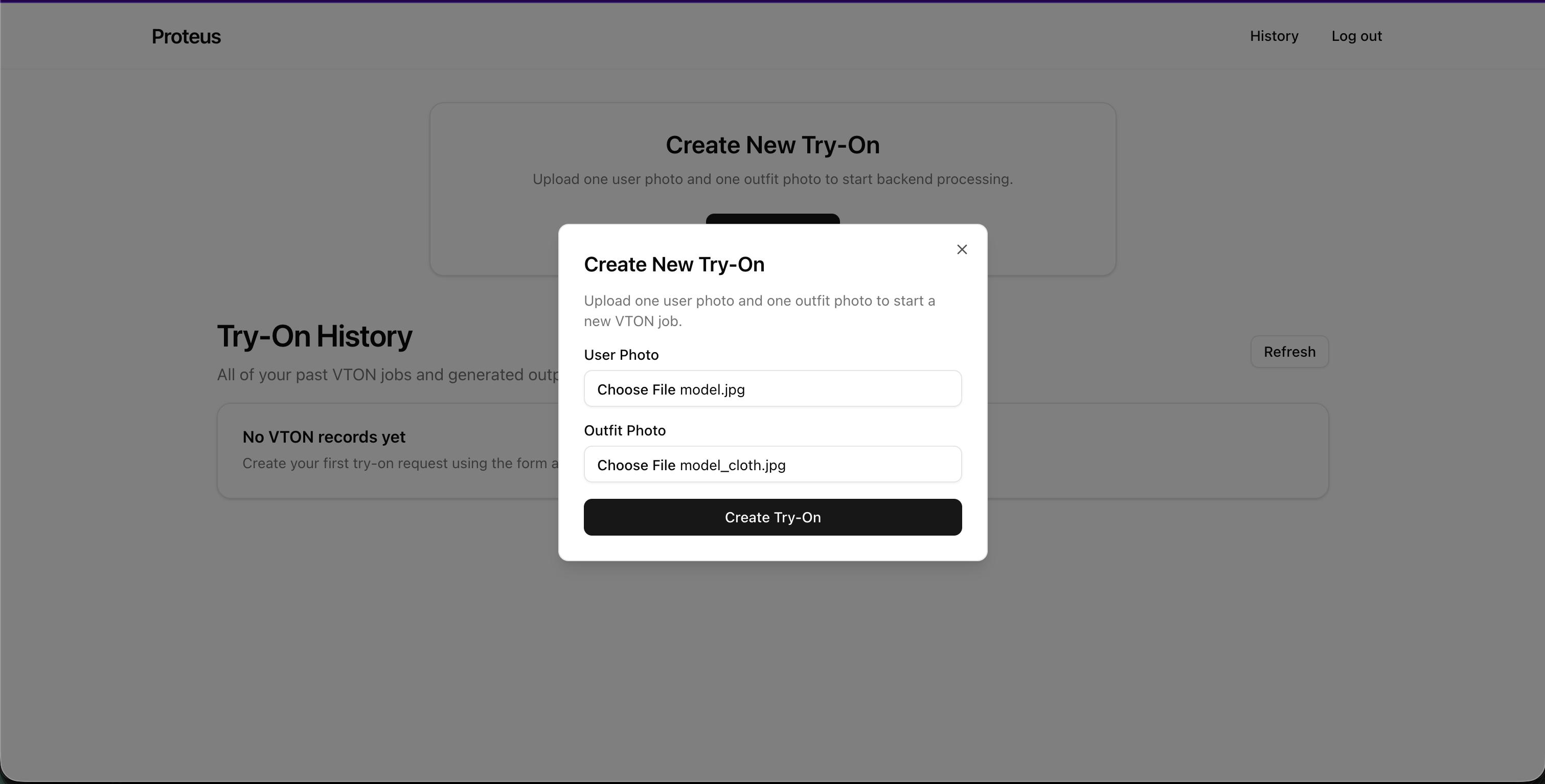
Proteus is a real-time, GPU-powered virtual try-on system. The experience is simple: upload a photo of yourself and a photo of a garment. Within seconds, you see a synthesized image of yourself wearing that outfit - no physical try-on, no guessing, no returns.
Under the hood, the system is a fully event-driven pipeline:
- Images are converted to JPEG in the browser (including iPhone HEIC files) and uploaded directly to S3 via presigned URLs - no file bytes ever pass through the backend.
- A Weaver worker running on an NVIDIA GPU pulls jobs from a Redis queue and runs the CatVTON diffusion model. Rather than processing one image at a time, Weaver uses dynamic batching: it groups multiple queued jobs together and runs them through the model in a single forward pass, dramatically improving GPU utilization under load. The Arbitrator control loop monitors queue depth in real time and adjusts the batch size accordingly, so the system gets more efficient as traffic increases, not less.
- The moment inference completes, the Gateway pushes a WebSocket event to the user's browser - the new try-on image appears automatically, no reload required.
- Optionally, KEDA scales Weaver replicas up and down based on Redis queue length, adding a second layer of horizontal scaling on top of batching.
How we built it
The stack is intentionally open-source end-to-end:
| Layer | Technology |
|---|---|
| Frontend | React, Vite, TanStack Query, WebSocket client |
| Gateway | Node.js, Express, ws, Prisma, JWT auth |
| Inference | Python, PyTorch, Diffusers, CatVTON-MaskFree |
| Messaging | Redis (queues + pub/sub) |
| Storage | S3-compatible (Linode Object Storage / MinIO) |
| Database | PostgreSQL |
| Orchestration | LKE, Docker, optional KEDA |
The data flow is clean and stateless. When a user submits a try-on request, the Gateway issues presigned S3 URLs, the frontend uploads directly, and the job is pushed to queue:weaver_jobs. Weaver pops a batch of jobs, runs inference, writes results to S3, and publishes to events:job_done. The Gateway - subscribed to that channel - routes each event to the correct WebSocket connection by user_id. The CatVTON works by starting with a noisy, scrambled image and gradually cleaning it up, guided by the garment photo, until a realistic try-on result emerges.
We used Kilo Code throughout development as an AI-powered coding assistant that genuinely changed how fast we could ship. Kilo Code runs on MiniMax M2.5, and we integrated it directly into our frontend workflow - it helped us make smarter React/Vite component decisions, caught UX issues before they became bugs, and gave us a second pair of eyes on architecture choices we weren't confident about. On the backend side, we used Kilo for code reviews on every pull request, which meant integration bugs got caught before merge rather than after. When we were figuring out system design - how services should talk to each other, how to structure the API contracts between Gateway, Weaver, and Arbitrator - Kilo's architect mode helped us think through tradeoffs we would have otherwise learned the hard way. Deploying a multi-service GPU pipeline on Akamai Cloud's Linode Kubernetes Engine as first-time Kubernetes users was already a steep climb; having Kilo Code alongside us meant we could move faster without sacrificing quality.
Challenges we ran into
Kubernetes from scratch. Neither of us had touched Kubernetes before this hackathon. Learning to write manifests, understand namespaces, configure secrets, wire up services, and reason about pod scheduling - all while simultaneously building the actual application - was the single biggest challenge we faced. Getting GPU nodes working on LKE with the right node selectors, tolerations, and resource limits was a particularly steep cliff. We went from zero Kubernetes knowledge to a multi-service GPU-backed cluster in a matter of days.
HEIC/AVIF image handling was a surprise paper cut. Mobile photos (especially from iPhones) arrive as HEIC, which most browsers and ML pipelines don't handle natively. We solved it client-side using heic2any and canvas-based conversion to JPEG, keeping the backend and Weaver completely agnostic to input format.
Real-time delivery without polling required careful design. Routing WebSocket events to the correct user across potentially multiple Gateway replicas meant leaning on Redis pub/sub as the event bus and stamping every event with user_id so the Gateway could dispatch correctly.
Keeping the backend stateless while supporting live updates was a constant design constraint - but one worth enforcing, because it's what makes horizontal scaling on LKE tractable.
Accomplishments that we're proud of
- A fully working, end-to-end GPU try-on pipeline deployed on LKE - not a demo, a live system at proteus-frontend-psi.vercel.app.
- Zero proprietary inference APIs. CatVTON, Redis, Kubernetes, React - fully open-source.
- Dynamic batching in Weaver with Arbitrator-controlled batch sizes, so GPU throughput scales up as queue depth grows.
- Presigned S3 uploads meaning the Gateway never touches image bytes, keeping it lean and horizontally scalable.
- WebSocket-driven real-time delivery: try-on results appear the instant GPU inference completes.
- All of this built by two people who had never written a Kubernetes manifest before the hackathon started.
What we learned
Building a real AI/ML pipeline in a cloud-native way is fundamentally a distributed systems problem, not just an ML problem. Getting the model running was the easier half; wiring together stateless APIs, queue-based workers, dynamic batching, event-driven delivery, and GPU scheduling in a way that's reliable and scalable was where the real engineering lived.
We also learned how much friction client-side image normalization eliminates downstream. Handling format conversion at the edge (browser) rather than in the pipeline made every other component simpler and more robust.
And we learned Kubernetes. Fast.
What's next for Proteus - Virtual Try-On: See the Fit Before You Buy
The immediate next step is Tailor - a SegFormer-based outfit segmentation worker that cleans garment images before they reach Weaver. The queue route and API endpoint already exist; the worker is the missing piece. With Tailor online, users can submit raw product photos (backgrounds, mannequins, hangers) and get clean, try-on-ready garment masks automatically.
Beyond that, the path to a real product is clear:
- E-commerce integrations - a Shopify plugin or embeddable widget so retailers can drop Proteus directly into product pages.
- Multi-garment try-on - full outfits, not just single pieces.
- Feedback loop - using user preference signals to fine-tune the diffusion model over time.
- Autoscaling in production - KEDA is already wired; tuning ScaledObject parameters for real traffic patterns is the next operational milestone.
The core insight is simple: the fitting room is the last major unsolved UX problem in e-commerce. Proteus is a credible, open-source, GPU-native answer to it - and it's already running.
Built With
- akamai-cloud
- aws-sdk
- boto3
- catvton-maskfree
- diffusers
- docker
- express.js
- heic2any
- jwt
- keda
- kilo-code
- kubernetes
- linode-kubernetes-engine
- linode-object-storage
- minimax
- minio
- node.js
- nvidia-gpu
- postgresql
- prisma
- python
- pytorch
- react
- redis
- s3
- tanstack-query
- typescript
- vite
- websockets


Log in or sign up for Devpost to join the conversation.