-
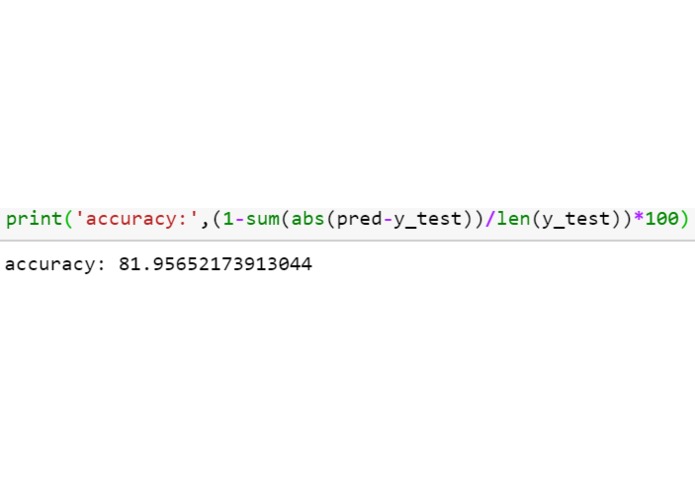
Accuracy
-
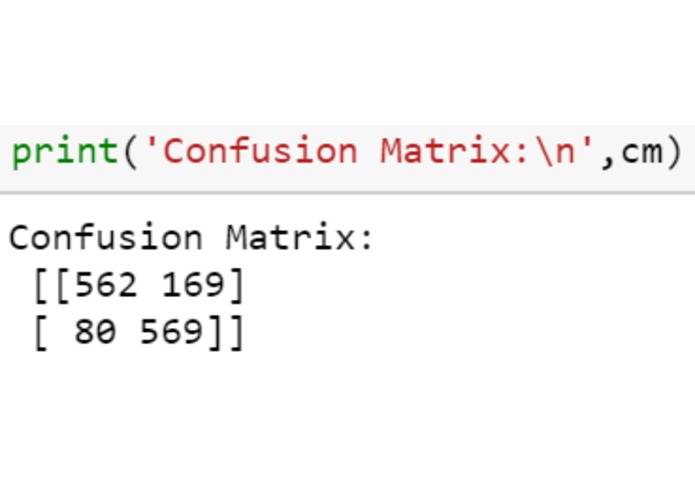
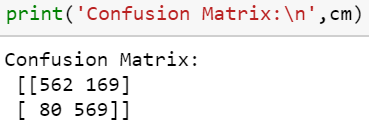
confusion_matrix
-

performance_metrics
-
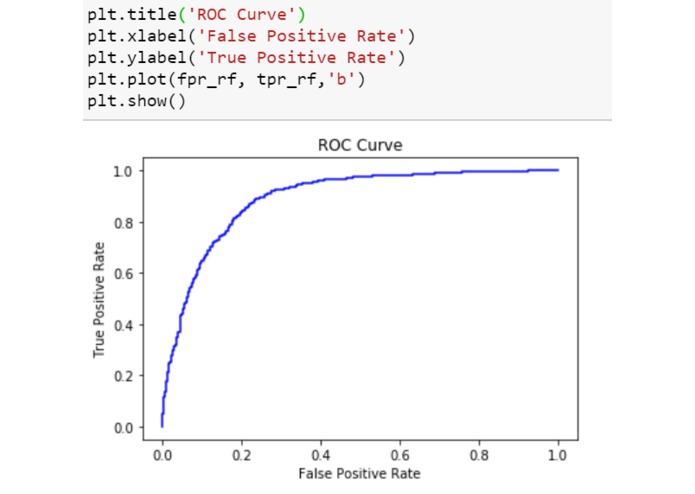
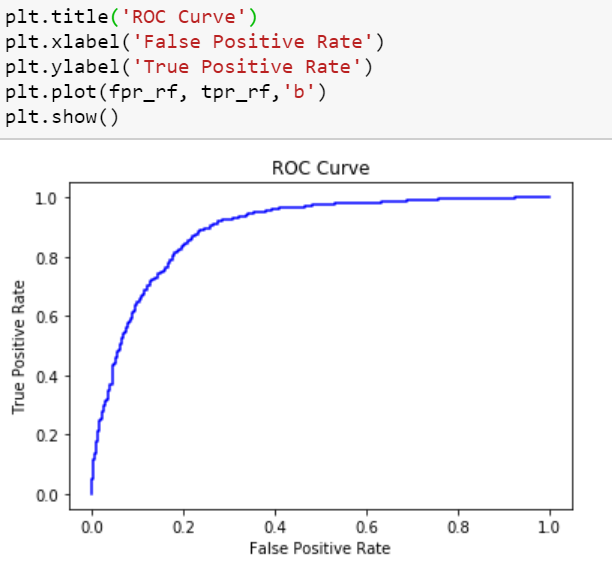
roc_curve
-
trained_model



Inspiration
Due to increase in data related to genetics and DNA, we decided to make things easier for the biologists. We figured out the problems that were involved in finding data related to protein sequences which affect many aspects of modern day microbiology. Upon contacting our friend from this area, we found that we can in fact apply AI and ML models for this data. Thus, we came to a conclusion of building this project.
What it does
An ML model which classifies the protein sequences to ordered and disordered. Without these techniques, it would cost lots of money and time to figure out the characteristics of protein sequences from data available. Given a protein sequence, we determine its disorderliness for diseased states and checked for these occurrences in the human proteome.
How we built it
We gathered data-set and extracted features from it that were correlated with orderliness of the protein sequence. Through these features, we trained an ML model and verified the results with those obtained in labs. We achieved an accuracy of about 82% using the Random Forest Classifier. We then found the relations of these proteins with the ones that are believed to be disordered and disease related.
Challenges we ran into
Understanding the data-set to get the features for the model was hard. Trying to optimize the model without having structural data of the proteins was hard enough and we had to try different models to get the desired results. Due to this, we had to extract some more derived features and then achieve good results.
Accomplishments that we're proud of
Finishing a multi-disciplinary project within 24 hours was a huge accomplishment. Above that, getting a good enough accuracy was also a success.
What we learned
We learned that how we can't simply apply the machine learning models to any data. To effectively get information, we need to have knowledge about the data and then work out to solve the problem. Moreover, we learned that how can we apply computer science techniques to solve multi-disciplinary problems that are of utmost importance today and will be in near future.
What's next for ProteoML - ML based Prediction of Disordered Proteins
By collecting the structural information using X-Ray image and then using image processing techniques, we can train this model and get enough accuracy that the results can be more dependable and the laboratory testing time and costs can be reduced significantly.

Log in or sign up for Devpost to join the conversation.